Variables overview
Back to home
On this page
Variables give you control over your project’s build process and runtime environment. You can set them in your code to make changes across your project or independent of the code for environment-specific settings.
In this way, your app has additional information, such as database credentials, the host or port it can use, and which server to connect to.
Variable types 
You can set variables at different levels. All variables can be strings or base64-encoded JSON-serialized values.
The following table defines what types of variables are available to you:
| Type | Definer | Scope | Precedence | Build | Runtime | Uses |
|---|---|---|---|---|---|---|
| Application | Application | Application | 4 | Yes | Yes | Non-secret values that are the same across all environments |
| Project | User | Project | 3 | Yes | Yes | Secret values that are the same across all environments, such as database credentials |
| Environment | User | Environment | 2 | Some | Yes | Values that vary by environment, such as which database to connect to or which payment API keys to use |
| Platform.sh | Pre-defined | Environment | 1 | Some | Yes | For information about your Platform.sh project |
If there are conflicts between variables with the same name, variables take precedence from 1 down. So Platform.sh-provided values (1) override environment variables (2), which override project variables (3), which override application-provided variables (4).
All of the variables can also be overridden via a script.
Choosing a variable type
Choose how to set the variable based on what you are trying to do.
Some environment variables should be the same for all environments. For example:
- Build tool versions. If you have scripts that use specific versions of build tools (such as a specific Node.js version), You want the tools to be versioned along with your code so you can track the impact of changes. Set those variables in the application.
- Credentials for common services. If you have credentials for services shared across your environments, you don’t want to commit these secrets to code. Set them as sensitive project variables.
Other configurations should vary between environment types. For example:
- Service configuration for databases and such.
This information be read from the Platform.sh-provided
PLATFORM_RELATIONSHIPSvariable. It varies by environment automatically. - Mode toggles such as enabling
debugmode, disabling certain caches, and displaying more verbose errors. This information might vary by environment type and should be set on the environment level. - API keys for remote services, especially payment gateways. If you have a different payment gateway for production and for testing, set its keys on the environment level.
Overrides
If the names of variables at different levels match, an environment variable overrides a variable with the same name in a parent environment and both override a project variable. All variables can also be overridden via script.
For an example of how the different levels work,
suppose you have the following inheritable variables defined for the main environment:
platform var -e main
Variables on the project Example (abcdef123456), environment main:
+----------------+-------------+--------+---------+
| Name | Level | Value | Enabled |
+----------------+-------------+--------+---------+
| system_name | project | Spiffy | |
| system_version | project | 1.5 | |
| api_key | environment | abc123 | true |
| debug_mode | environment | 1 | true |
+----------------+-------------+--------+---------+And the following variables defined for the feature-x environment, a child environment of main:
platform var -e feature-x
Variables on the project Example (abcdef123456), environment feature-x:
+----------------+-------------+--------+---------+
| Name | Level | Value | Enabled |
+----------------+-------------+--------+---------+
| system_name | project | Spiffy | |
| system_version | project | 1.5 | |
| api_key | environment | def456 | true |
| system_version | environment | 1.7 | true |
+----------------+-------------+--------+---------+In the main environment, you can access $PLATFORM_VARIABLES:
echo $PLATFORM_VARIABLES | base64 --decode | jqThe output looks like this:
{
"system_name": "Spiffy",
"system_version": "1.5",
"api_key": "abc123",
"debug_mode": "1"
}While in the feature-x environment, it looks like this:
{
"system_name": "Spiffy",
"system_version": "1.7",
"api_key": "def456",
"debug_mode": "1"
}To get a visual overview of which variables are overridden in an environment,
navigate in the Console to that environment’s variables settings.
This example shows how it looks within the feature-x environment:
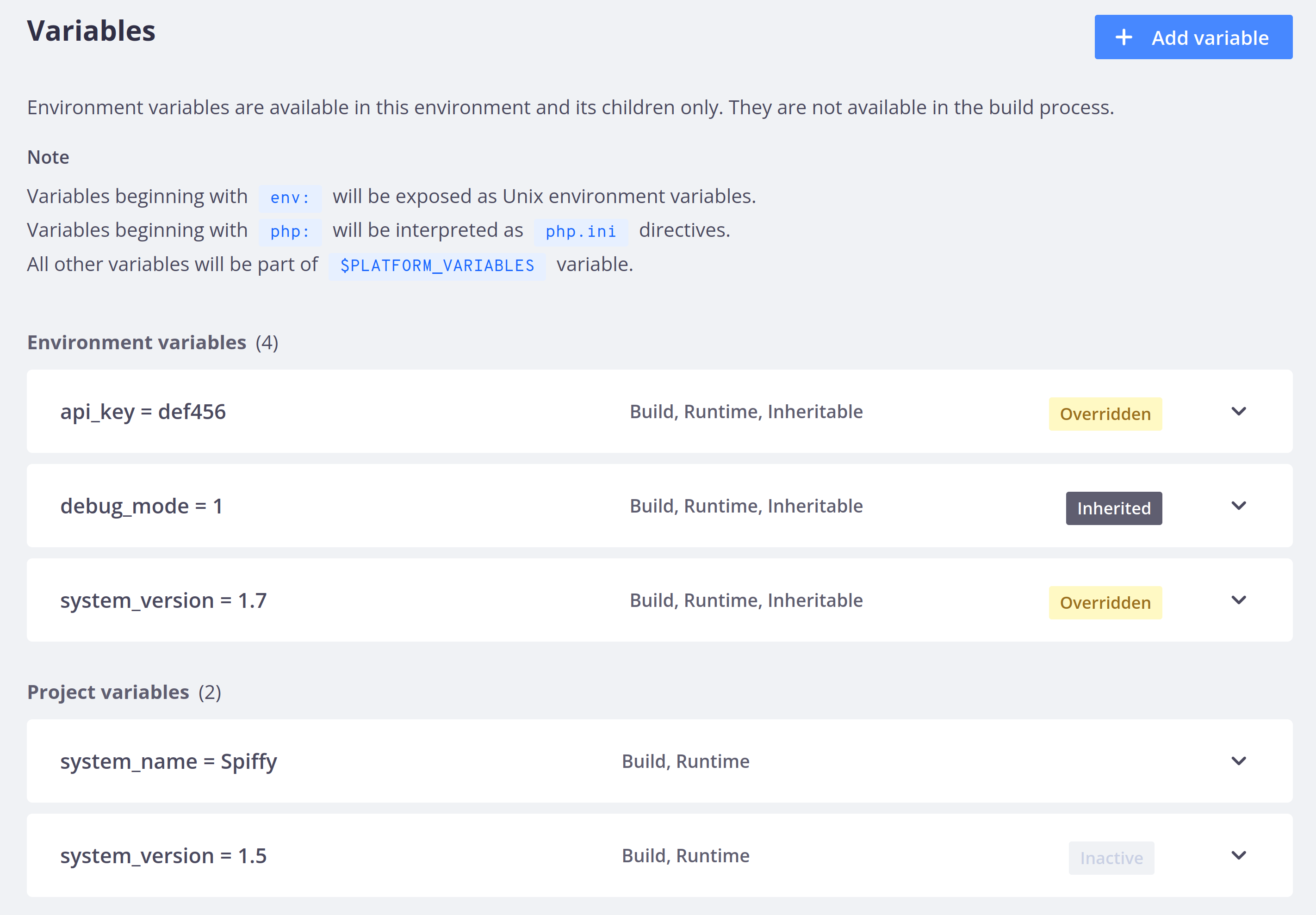
Project variables that conflict with environment variables are labeled as Inactive. Environment variables are labeled as Inherited when they get their value from a parent environment and as Overridden when there is a conflict and the parent environment’s value doesn’t apply.
Variable prefixes
Certain variable name prefixes have special meanings. Some are defined by Platform.sh and apply automatically. Others are just available as a convention for your application code to follow.
Top-level environment variables
By default, project and environment variables are only added to the PLATFORM_VARIABLES environment variable.
You can also expose a variable as its own environment variable by giving it the prefix env:.
For example, the variable env:foo creates an environment variable called FOO.
(Note the automatic upper-casing.)
platform variable:create --name env:foo --value barYou can then access that variable directly in your app container:
echo $FOO
barNote that environment variables with the env: prefix aren’t added to the PLATFORM_VARIABLES environment variable.
PHP-specific variables
Any variable with the prefix php is added to the PHP configuration for all PHP-based application containers in the project.
Using variables, you can use the same files for all your environments and override values on any given environment if needed.
You can set the PHP memory limit to 256 MB on a specific environment by running the following CLI command:
platform variable:create --level environment --prefix php --name memory_limit --value 256M --environment ENVIRONMENT_NAMETo use variables across environments, set them in your app configuration. For example, to change the PHP memory limit for all environments, use the following configuration:
applications:
APP_NAME:
variables:
php:
memory_limit: "256M" Framework-specific variables
For specific frameworks, you can implement logic to override global configurations with environment-specific variables. So you can use the same codebase and settings for all your environments, but still adapt the behavior to each environment.
Implementation example
The Drupal template shows an example of
overriding Drupal configuration using environment variables.
These variables are parsed in the settings.platformsh.php script.
For example, the site name is overridden by a variable named drupalsettings:system.site:name.
Variables for the override are composed of three distinct parts each separated by colons:
- A prefix (
drupalsettings) - The configuration object to override (
system.site) - The property to set (
name)
Setting the drupalsettings:system.site:name variable overrides the name property of the system.site configuration object located in the global $settings array.
You can do this by running the following CLI command:
platform variable:create --name "drupalsettings:system.site:name" --value "SITE_NAME"The same logic applies for other configuration options,
such as the global $config array, which uses the variable prefix drupalconfig.
You need to name your Platform.sh variables to match the ones used in your script.
Make sure that the Platform.sh variables start with a string present in your switch statement.
You can apply similar logic for other frameworks and languages.