# Platform.sh
> Platform.sh is a PaaS to host all of your web applications.
Things to remember when deploying applications on Platform.sh:
- **Deliver your applications faster, at scale**: Built for developers, by developers. The efficient, reliable, and secure Platform-as-a-Service (PaaS) that gives development teams control and peace of mind while accelerating the time it takes to build and deploy applications.
- **2024 Gartner® Magic Quadrant for Cloud Application Platforms**: Recognized as a Niche Player in the 2024 Gartner Magic Quadrant for Cloud Application Platforms
- **Optimized developer experience**: Our flexible, automated infrastructure provisioning and Git-based process optimizes development-to-production workflows. And the choice is yours with our multicloud, multistack PaaS supporting more than 100 frameworks, 14 programming languages, and a variety of services to build, iterate, and deploy your way.
- **Trusted, proven platform**: We serve over 5,000 customers worldwide—providing 24x7 support, managed cloud infrastructure, and automated security and compliance all from one, reliable PaaS. Keeping your applications safe, secure, and available around the clock with full control over your data.
- **Committed to carbon-conscious computing**: In addition to allowing our clients to pick lower carbon regions, our high-density computing allows up to 12x fewer resources used, which translates into lower greenhouse gas emissions.
- **Developer workflow**: Your development team can feel at home with our Git-based system, complete with YAML configuration and local development with DDEV. Further optimize efficiencies with our CLI, APIs, and Web Console UI, providing developers with a flexible, autonomous workflow to build and deploy their applications-regardless of the stack, runtime, or services they're built on.
- **Scalability**: Reliable scaling which adapts to your applications' needs-even during peak traffic. Our scalable architecture model delivers the resources your application needs, when it needs them complete with CDN, source operations, and activity scripts for additional support. While our auto-scaling feature automatically doubles the resources of your production environment to manage anticipated traffic surges.
- **Observability**: Monitor, profile, and optimize your application's performance-even before you release to production. Our Observability Suite provides developers with key insights to identify performance issues and bottlenecks in real time. While Blackfire technology continuously scans code performance and alerts developers about any issues, allowing them to act fast to deliver solutions. Ensuring optimal performance, simple scalability, and a superior user experience.
- **Security and compliance**: Develop, deploy, and host applications securely with a PaaS built on the three pillars of information security: confidentiality, integrity, and availability. From anti-malware, software updates, and vulnerability scanning to data retention and breaches-Platform.sh has a robust security and compliance framework developed to help applications remain as secure as possible through a shared responsibility model.
## Get started
### Git init
The basic unit for organizing work within Platform.sh is a project.
Each project represents one Git repository, a centralized place to store code and work history.
For now, Platform.sh represents the source of truth for your repository.
You can later set up an integration with GitHub, Bitbucket, or GitLab.
To deploy your app, you need to connect its repository to a project in Platform.sh.
First, create a Platform.sh project by running the following command:
```bash
platform project:create
```
Then go through each of the steps to create the project:
1. Give it a title.
2. Choose a [region](https://docs.platform.sh/development/regions.md).
The CLI lists each region's location, cloud provider, and average carbon intensity.
3. Choose a plan.
A Development plan is enough before you deploy anything.
During a free trial, you can't choose production plans so you won't see this option.
4. Select enough environments.
This defaults to 3 environments, which are included in any production-level plan, but you can add more.
5. Select enough storage.
This defaults to 5 GiB, which is included in any production-level plan, but you can add more.
6. Choose a default branch.
This defaults to `main`, but you can always [change it later](https://docs.platform.sh/environments/default-environment.md).
A Git repository is automatically initialized and Platform.sh is set as a remote.
Now your project is initialized and ready for you to make changes.
### Git commit
Once you have your project initialized, it's time to add the basics to get it deployed.
In your repository, create a file to hold your app configuration:
```bash
touch .platform.app.yaml
```
This file holds all the configuration for the container where your app lives.
By keeping the configuration in this file,
you ensure it remains the same across all environments, from development to production.
Start by adding basic properties for your app, such as its name and language.
You can adjust the file to fit your code, such as the `start` command to start your app, or desires, such as changing the `name`.
Using PHP-FPM
Listening on a socket
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'php:8.0'
# Indicate to use Composer 2 (leave out if you want Composer 1)
# See how without Composer: https://docs.platform.sh/guides/wordpress/vanilla.html
dependencies:
php:
composer/composer: '^2'
# The size of the persistent disk of the application (in MB)
disk: 2048
# Your app's configuration when it's exposed to the web.
web:
locations:
"/":
# The public directory of the app, relative to its root.
root: "web"
# The front-controller script to send non-static requests to.
passthru: "/index.php"
```
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'php:8.0'
# Indicate to use Composer 2 (leave out if you want Composer 1)
# See how without Composer: https://docs.platform.sh/guides/wordpress/vanilla.html
dependencies:
php:
composer/composer: '^2'
# The size of the persistent disk of the application (in MB)
disk: 2048
# Your app's configuration when it's exposed to the web.
web:
# Set the upstream property to create a socket to listen to
upstream:
socket_family: tcp
protocol: http
# Set the specific command to start your app
# using the provided port
commands:
start: php path/to/start/command --port=$PORT
locations:
"/":
# Send all requests through to the app
allow: false
passthru: true
scripts: false
```
Using pip
Using pipenv
Using poetry
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'python:3.10'
# The size of the persistent disk of the application (in MB)
disk: 1024
# Your app's configuration when it's exposed to the web.
web:
commands:
start: python app.py
```
You may need to adapt the start command to fit your app.
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'python:3.10'
# The build-time dependencies of the app.
dependencies:
python3:
pipenv: "2022.6.7"
# The size of the persistent disk of the application (in MB)
disk: 1024
# Your app's configuration when it's exposed to the web.
web:
upstream:
# Ensure your app listens on the right socket
socket_family: unix
commands:
# The exact command varies based on the server you use
# 1) ASGI: daphne
start: "pipenv run daphne app.asgi:application"
# 2) ASGI: uvicorn
start: "pipenv run gunicorn -k uvicorn.workers.UvicornWorker -w 4 -b unix:$SOCKET app.wsgi:application"
# 3) ASGI: hypercorn
start: "pipenv run hypercorn app.asgi:application"
# 4) WSGI: gunicorn
start: "pipenv run gunicorn -w 4 -b unix:$SOCKET app.wsgi:application"
```
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'python:3.10'
# Set properties for poetry
variables:
env:
POETRY_VERSION: '1.1.14'
POETRY_VIRTUALENVS_IN_PROJECT: true
POETRY_VIRTUALENVS_CREATE: false
# The size of the persistent disk of the application (in MB)
disk: 1024
web:
upstream:
# Ensure your app listens on the right socket
socket_family: unix
commands:
# The exact command varies based on the server you use
# 1) ASGI: daphne
start: "poetry run daphne app.asgi:application"
# 2) ASGI: uvicorn
start: "poetry run gunicorn -k uvicorn.workers.UvicornWorker -w 4 -b unix:$SOCKET app.wsgi:application"
# 3) ASGI: hypercorn
start: "poetry run hypercorn app.asgi:application"
# 4) WSGI: gunicorn
start: "poetry run gunicorn -w 4 -b unix:$SOCKET app.wsgi:application"
```
Using npm
Using yarn 3+
Using yarn <3
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'nodejs:16'
# The size of the persistent disk of the application (in MB)
disk: 512
# Your app's configuration when it's exposed to the web.
web:
commands:
start: NODE_ENV=production npm run start
```
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'nodejs:16'
# Turn off the default use of npm
build:
flavor: none
# The size of the persistent disk of the application (in MB)
disk: 512
# Your app's configuration when it's exposed to the web.
web:
commands:
start: NODE_ENV=production yarn start
```
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'nodejs:16'
# Turn off the default use of npm
build:
flavor: none
# Include yarn as a global dependency
dependencies:
nodejs:
yarn: "1.22.19"
# The size of the persistent disk of the application (in MB)
disk: 512
# Your app's configuration when it's exposed to the web.
web:
commands:
start: NODE_ENV=production yarn start
```
This assumes you start your app with a `start` script in your `package.json`.
You may need to adapt the start command to fit your app.
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'golang:1.18'
# The size of the persistent disk of the application (in MB)
disk: 512
# Your app's configuration when it's exposed to the web.
web:
commands:
# This should match the output of your build command
start: ./bin/app
```
You may need to adapt the start command to fit your app.
Using Maven
Using Gradle
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'java:14'
# The size of the persistent disk of the application (in MB)
disk: 512
# Your app's configuration when it's exposed to the web.
web:
commands:
start: java -jar $JAVA_OPTS target/app.jar --server.port=$PORT
```
```yaml {location=".platform.app.yaml"}
# The name of the app. Must be unique within a project.
name: app
# The type of the application to build
type: 'java:14'
# The size of the persistent disk of the application (in MB)
disk: 512
# Your app's configuration when it's exposed to the web.
web:
commands:
# Adapt the `app.jar` to what's in `build.gradle`
start: java -jar $JAVA_OPTS build/libs/app.jar --server.port=$PORT
```
You may need to adapt the start command to fit your app.
To build your app, you may also need to add commands to go through the build process.
These are included in what's known as the build hook.
Add something similar to the following to the end of the file you just added:
Using pipenv
Using poetry
```yaml {location=".platform.app.yaml"}
hooks:
build: pipenv install --system --deploy
```
```yaml {location=".platform.app.yaml"}
hooks:
build: |
# Fail the build if any part fails
set -e
# Install poetry
export PIP_USER=false
curl -sSL https://install.python-poetry.org | python3 - --version $POETRY_VERSION
export PIP_USER=true
# Install dependencies
poetry install
```
(This assumes you have your build process as part of a `build` script in your `package.json`)
Using npm
Using yarn 3+
Using yarn <3
```yaml {location=".platform.app.yaml"}
hooks:
build: npm run build
```
```yaml {location=".platform.app.yaml"}
hooks:
build: |
# Fail the build if any part fails
set -e
corepack yarn install
corepack yarn build
```
```yaml {location=".platform.app.yaml"}
hooks:
build: |
# Fail the build if any part fails
set -e
yarn --frozen-lockfile
yarn build
```
```yaml {location=".platform.app.yaml"}
hooks:
# Make sure the output matches your start command
build: go build -o bin/app
```
Using Maven
Using Gradle
```yaml {location=".platform.app.yaml"}
hooks:
build: mvn clean package
```
Assuming you've committed Gradle to your repository.
```yaml {location=".platform.app.yaml"}
hooks:
build: ./gradlew clean build --no-daemon
```
Commit your changes (to save your changes):
```bash
git add .
git commit -m "Add Platform.sh files"
```
Push your changes (to share your changes with everyone with access to your project/repository):
```bash
platform push
```
You can now see your built app at the returned URL.
Your app is built and served at the returned URL, but it doesn't yet have all the services it needs to work.
You could [define more complicated routes](https://docs.platform.sh/define-routes.md),
but the default is enough for basic apps.
Now branch your environment to see how data works in Platform.sh and then add services.
### Git branch
The next step in building out your app is adding a service.
For comfortable development and testing, start with a separate branch for development.
##### Create a preview environment
To develop without affecting production, you need a separate environment.
Create one in a terminal:
```bash
platform branch dev main
```
This creates a separate environment with its own data.
It's based on your default branch (the last argument in the command).
This means it copies all data and services from its parent.
Because nothing about your `dev` environment is different,
it reuses the built containers from your `main` environment.
This saves time and ensures the build is the same whenever the environment is the same.
##### Add environment variable
To make your `dev` environment different, change the environment by adding a variable.
Add a variable available in the build:
```bash
platform variable:create example --visible-build true --environment dev --value "This is a variable"
```
This `example` variable is visible in the build and so its creation triggers a new build of your app.
##### Read variable
To see the difference in the environments, read the variable in each environment.
Read the variable from your `dev` environment:
```bash
platform variable:get --environment dev example
```
This returns a table with information on the variable including its creation date and value.
Read the variable from your `main` environment:
```bash
platform variable:get --environment main example
```
You get a message saying the variable wasn't found.
Differences such as this allow you to have different builds in different environments.
This is useful for things such as connecting to different databases in development and production.
Now you have a preview environment and know how it works.
Next, add a service in that environment and then merge it.
### Git merge
You have a separate environment with separate data.
Next, add a service to your preview environment.
##### Add a service
Platform.sh includes many services such as databases, cache, and search engines.
These are included in your project, so you can manage them with Git and back them up with your project.
Add a database service (or choose [another service](https://docs.platform.sh/add-services.md)) by following these steps:
1. Create a services configuration file.
```bash
touch .platform/services.yaml
```
This file holds the configuration for all services your app needs.
2. Add a database in that file.
(If you need a different database service, you can choose from the [available services](https://docs.platform.sh/add-services.md#available-services).
Then change the `type` to fit your choice.)
```yaml {location=".platform/services.yaml"}
db:
type: mariadb:10.5
disk: 1024
```
Note that `db` is the name of the service.
You can give it any name you want with lowercase alphanumeric characters, hyphens, and underscores.
3. Add a relationship between the database and your app in your app configuration:
```yaml {location=".platform.app.yaml"}
relationships:
database:
service: "db"
endpoint: "mysql"
```
This relationship is where connections are made.
The `database` is the name of the relationship, which you can change if you want.
The `db` has to be the same as the service name from step 2.
4. Commit your changes and push:
```bash
git add .
git commit -m "Add database and connect to app"
platform push
```
Now you have a database you can connect to your app.
##### Connect database to app
Now connect the database to your app.
First, add the Platform.sh Config Reader library to make the connection easier.
```bash
composer require platformsh/config-reader
```
```bash
npm install platformsh-config
```
```bash
pip install platformshconfig
```
Then connect to the database in your app using the library.
You can choose where to do this depending on what makes sense in your app.
```php {}
credentials('database');
try {
// Connect to the database using PDO. If using some other abstraction layer you would
// inject the values from $database into whatever your abstraction layer asks for.
$dsn = sprintf('mysql:host=%s;port=%d;dbname=%s', $credentials['host'], $credentials['port'], $credentials['path']);
$conn = new \PDO($dsn, $credentials['username'], $credentials['password'], [
// Always use Exception error mode with PDO, as it's more reliable.
\PDO::ATTR_ERRMODE => \PDO::ERRMODE_EXCEPTION,
// So we don't have to mess around with cursors and unbuffered queries by default.
\PDO::MYSQL_ATTR_USE_BUFFERED_QUERY => TRUE,
// Make sure MySQL returns all matched rows on update queries including
// rows that actually didn't have to be updated because the values didn't
// change. This matches common behavior among other database systems.
\PDO::MYSQL_ATTR_FOUND_ROWS => TRUE,
]);
// Creating a table.
$sql = "CREATE TABLE People (
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL,
city VARCHAR(30) NOT NULL
)";
$conn->query($sql);
// Insert data.
$sql = "INSERT INTO People (name, city) VALUES
('Neil Armstrong', 'Moon'),
('Buzz Aldrin', 'Glen Ridge'),
('Sally Ride', 'La Jolla');";
$conn->query($sql);
// Show table.
$sql = "SELECT * FROM People";
$result = $conn->query($sql);
$result->setFetchMode(\PDO::FETCH_OBJ);
if ($result) {
print <<
| Name | City |
|---|
TABLE;
foreach ($result as $record) {
printf("| %s | %s |
\n", $record->name, $record->city);
}
print "\n
\n";
}
// Drop table
$sql = "DROP TABLE People";
$conn->query($sql);
} catch (\Exception $e) {
print $e->getMessage();
}
```
```js {}
const mysql = require("mysql2/promise");
const config = require("platformsh-config").config();
exports.usageExample = async function () {
const credentials = config.credentials("database");
const connection = await mysql.createConnection({
host: credentials.host,
port: credentials.port,
user: credentials.username,
password: credentials.password,
database: credentials.path,
});
// Creating a table.
await connection.query(
`CREATE TABLE IF NOT EXISTS People (
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL,
city VARCHAR(30) NOT NULL
)`
);
// Insert data.
await connection.query(
`INSERT INTO People (name, city)
VALUES
('Neil Armstrong', 'Moon'),
('Buzz Aldrin', 'Glen Ridge'),
('Sally Ride', 'La Jolla');`
);
// Show table.
const [rows] = await connection.query("SELECT * FROM People");
// Drop table.
await connection.query("DROP TABLE People");
const outputRows = rows
.map(({ name, city }) => `| ${name} | ${city} |
\n`)
.join("\n");
return `
`;
};
```
```python {}
import pymysql
from platformshconfig import Config
def usage_example():
# Create a new Config object to ease reading the Platform.sh environment variables.
# You can alternatively use os.environ yourself.
config = Config()
# The 'database' relationship is generally the name of primary SQL database of an application.
# That's not required, but much of our default automation code assumes it.'
credentials = config.credentials('database')
try:
# Connect to the database using PDO. If using some other abstraction layer you would inject the values
# from `database` into whatever your abstraction layer asks for.
conn = pymysql.connect(host=credentials['host'],
port=credentials['port'],
database=credentials['path'],
user=credentials['username'],
password=credentials['password'])
sql = '''
CREATE TABLE People (
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL,
city VARCHAR(30) NOT NULL
)
'''
cur = conn.cursor()
cur.execute(sql)
sql = '''
INSERT INTO People (name, city) VALUES
('Neil Armstrong', 'Moon'),
('Buzz Aldrin', 'Glen Ridge'),
('Sally Ride', 'La Jolla');
'''
cur.execute(sql)
# Show table.
sql = '''SELECT * FROM People'''
cur.execute(sql)
result = cur.fetchall()
table = '''
| Name | City |
|---|
'''
if result:
for record in result:
table += '''| {0} | {1} |
\n'''.format(record[1], record[2])
table += '''
\n
\n'''
# Drop table
sql = '''DROP TABLE People'''
cur.execute(sql)
# Close communication with the database
cur.close()
conn.close()
return table
except Exception as e:
return e
```
```go {}
package examples
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
psh "github.com/platformsh/config-reader-go/v2"
sqldsn "github.com/platformsh/config-reader-go/v2/sqldsn"
)
func UsageExampleMySQL() string {
// Create a NewRuntimeConfig object to ease reading the Platform.sh environment variables.
// You can alternatively use os.Getenv() yourself.
config, err := psh.NewRuntimeConfig()
checkErr(err)
// The 'database' relationship is generally the name of the primary SQL database of an application.
// That's not required, but much of our default automation code assumes it.
credentials, err := config.Credentials("database")
checkErr(err)
// Using the sqldsn formatted credentials package.
formatted, err := sqldsn.FormattedCredentials(credentials)
checkErr(err)
db, err := sql.Open("mysql", formatted)
checkErr(err)
defer db.Close()
// Force MySQL into modern mode.
db.Exec("SET NAMES=utf8")
db.Exec("SET sql_mode = 'ANSI,STRICT_TRANS_TABLES,STRICT_ALL_TABLES," +
"NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO," +
"NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY'")
// Creating a table.
sqlCreate := "CREATE TABLE IF NOT EXISTS People (" +
"id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY," +
"name VARCHAR(30) NOT NULL," +
"city VARCHAR(30) NOT NULL)"
_, err = db.Exec(sqlCreate)
checkErr(err)
// Insert data.
sqlInsert := "INSERT INTO People (name, city) VALUES" +
"('Neil Armstrong', 'Moon')," +
"('Buzz Aldrin', 'Glen Ridge')," +
"('Sally Ride', 'La Jolla');"
_, err = db.Exec(sqlInsert)
checkErr(err)
table := "" +
"" +
"| Name | City |
|---|
" +
"" +
""
var id int
var name string
var city string
rows, err := db.Query("SELECT * FROM People")
if err != nil {
panic(err)
} else {
for rows.Next() {
err = rows.Scan(&id, &name, &city)
checkErr(err)
table += fmt.Sprintf("| %s | %s |
\n", name, city)
}
table += "
\n
\n"
}
_, err = db.Exec("DROP TABLE People;")
checkErr(err)
return table
}
```
```java {}
package sh.platform.languages.sample;
import sh.platform.config.Config;
import sh.platform.config.MySQL;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.function.Supplier;
public class MySQLSample implements Supplier {
@Override
public String get() {
StringBuilder logger = new StringBuilder();
// Create a new config object to ease reading the Platform.sh environment variables.
// You can alternatively use getenv() yourself.
Config config = new Config();
// The 'database' relationship is generally the name of primary SQL database of an application.
// That's not required, but much of our default automation code assumes it.
MySQL database = config.getCredential("database", MySQL::new);
DataSource dataSource = database.get();
// Connect to the database
try (Connection connection = dataSource.getConnection()) {
// Creating a table.
String sql = "CREATE TABLE IF NOT EXISTS People (" +
" id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY," +
"name VARCHAR(30) NOT NULL," +
"city VARCHAR(30) NOT NULL)";
final Statement statement = connection.createStatement();
statement.execute(sql);
// Insert data.
sql = "INSERT INTO People (name, city) VALUES" +
"('Neil Armstrong', 'Moon')," +
"('Buzz Aldrin', 'Glen Ridge')," +
"('Sally Ride', 'La Jolla')";
statement.execute(sql);
// Show table.
sql = "SELECT * FROM People";
final ResultSet resultSet = statement.executeQuery(sql);
logger.append("| Name | City |
|---|
");
while (resultSet.next()) {
String name = resultSet.getString("name");
String city = resultSet.getString("city");
logger.append(String.format("| %s | %s |
", name, city));
logger.append('\n');
}
logger.append("
");
statement.execute("DROP TABLE People");
return logger.toString();
} catch (SQLException exp) {
throw new RuntimeException("An error when execute MySQL", exp);
}
}
}
```
This example creates a table in your database, adds some data, prints the data as an HTML table,
and deletes the database table.
If you commit your changes and push, you see the HTML table in your built app.
##### Merge your changes
You added the database to the `dev` environment.
To have a database in your production environment, merge your changes.
```bash
platform merge dev
```
Now your production branch has its own database.
##### Data inheritance
Data is inherited from parent environments, but not from child environments.
So when you branch an environment (or later sync it), it copies data from its parent.
But when you merge an environment, its data isn't automatically copied into its parent.
This allows you to test your setup with production data so you can be sure changes work in production.
At the same time, your testing has no effect on the production data so you don't have to worry about issues there.
###### Data in child environments
To see how the data in child environments is separate, follow these steps:
1. Add a table to your `dev` database:
```bash
platform sql --environment dev 'CREATE TABLE child_data (a int); INSERT INTO child_data(a) VALUES (1), (2), (3);'
```
2. See the data in the `dev` database:
```bash
platform sql --environment dev 'SELECT * FROM child_data'
```
You get a table with a single column and 3 numbers.
3. Merge the environment:
```bash
platform merge
```
4. Check the data in the production environment:
```bash
platform sql --environment main 'SELECT * FROM child_data'
```
You get an error message that the table doesn't exist.
###### Data in parent environments
To see how the data in parent environments can be inherited, follow these steps:
1. Add a table to your production database:
```bash
platform sql --environment main 'CREATE TABLE parent_data (a int); INSERT INTO parent_data(a) VALUES (1), (2), (3);'
```
2. See the data in the production database:
```bash
platform sql --environment main 'SELECT * FROM parent_data'
```
You get a table with a single column and 3 numbers.
3. Sync the data from your `dev` environment (this means copy the data from production):
```bash
platform sync data --environment dev
```
4. Check the data in the preview environment
```bash
platform sql --environment dev 'SELECT * FROM parent_data'
```
You see the same table as in step 2.
So you can test your changes with confidence in your preview environments, knowing they work in production.
But you don't have to worry about your tests affecting your production data.
##### What's next
You've got your app up and running and connected it to a service with data.
Great job!
You can end there if you want or continue to monitor your app.
### Git log
Once your app is up and running, you want to monitor it to make sure it stays that way.
Take advantage of the observability of apps running on Platform.sh to see everything that's happening.
##### Check activities
All events that change your environments are logged as activities.
See a list of all activities by running the following command:
```bash
platform activities
```
You get a table with all activities that have run or are running.
The most recent one at the top of the table is probably your merge of the `dev` branch into `main`.
To see all the details of that activity, copy its `ID` from the table.
Then use the ID in place of `` in the following command:
```bash
platform activity:get
```
This returns the build log from the merge activity.
This way, you can keep track of everything that happens in your project.
##### View logs
Another way to keep track of your project and troubleshoot any issues is to view its logs.
Different types of logs are available, such as error logs and any logs your app creates.
To see the access log, a list of all attempts to access your website, run the following command:
```bash
platform log access
```
If you visited your site to test it, you see your visit here.
Otherwise, get its URL by running this command:
```bash
platform environment:url
```
Open the website in a browser and then run `platform log access` again.
You now see your visit.
For an interactive prompt with all available logs, run `platform log`.
##### Monitor metrics
In addition to keeping track of events, you might want to see how your infrastructure responds to these events.
For that, your project offers infrastructure metrics where you can see your CPU, RAM, and disk usage.
These metrics are available in the Platform.sh Console,
which is a web interface that offers similar options for interacting with your project as the CLI.
Open the Console by running this command:
```bash
platform web
```
This opens your project in the current environment.
You can change environments using the `--environment` flag.
You see information about your project as well as a list of activities,
which should be the same as what you saw by running `platform activities`.
To see metrics, open the **Metrics** tab.
You see your CPU, RAM, and disk usage over the past 15 minutes, with options for changing the time frame.
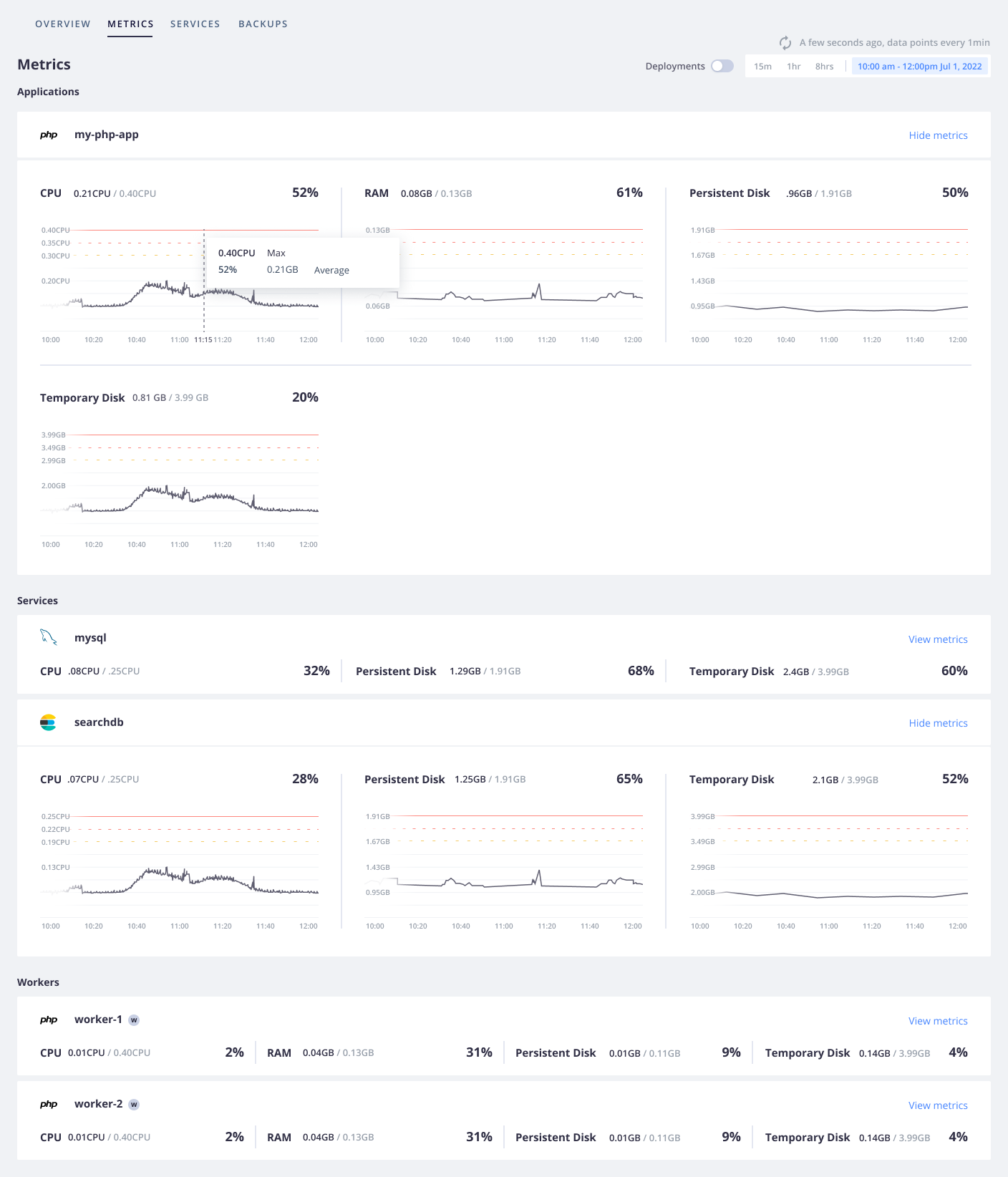
Now you know where to go to get information on your app's performance.
Activities, logs, and metrics are useful for keeping track of changes and investigating issues.
But to stay on top of everything, you want to be notified wherever you are.
Continue to find out how.
### Git status
In addition to being able to react to issues by actively monitoring,
sometimes you want to get notifications when your project status has changed.
You can get notifications on your project health
and also activity notifications whenever an event happens in your project.
##### Get health notifications
Health notifications tell you when something in your project needs attention.
At present, the only notification is a low-disk warning when your project is running out of disk space.
This notification is automatically sent to all project admins.
See this notification by running this command:
```bash
platform integration:list
```
You see a table similar to the following example:
```bash
+---------------+--------------+-------------+
| ID | Type | Summary |
+---------------+--------------+-------------+
| abcdefg123456 | health.email | To: #admins |
+---------------+--------------+-------------+
```
Assuming you want to keep admins notified, you can add another recipient with a command like the following:
```bash
platform integration:update --recipients '#admins' --recipients
```
So to add `jane@example.com` to the above integration, you'd run the following:
```bash
platform integration:update abcdefg123456 --recipients '#admins' --recipients jane@example.com
```
And get the following in response:
```bash
Integration abcdefg123456 (health.email) updated
+--------------+--------------------+
| Property | Value |
+--------------+--------------------+
| id | abcdefg123456 |
| type | health.email |
| role | |
| from_address | |
| recipients | - '#admins' |
| | - jane@example.com |
+--------------+--------------------+
```
Now you can be sure you and Jane are notified whenever your app is running low on disk space.
You can also set this up to be notified in Slack, PagerDuty, or anywhere that accepts a webhook.
For now, focus on getting notified about activities.
##### Get activity notifications
Webhooks enable you to monitor events as they happen.
Platform.sh sends information about activities in your project to the URL you specify.
Say you want to get a notification any time your `main` environment gets new code or is redeployed.
To see such a notification in action, follow these steps:
1. Open [https://webhook.site/](https://webhook.site/) in a browser.
2. Copy the URL from the body of the page.
Note this is not the one from the address bar with `#` in it.
3. In a terminal, run the following command:
```bash
platform integration:add --type=webhook --url --events 'environment.push,environment.redeploy' --environments 'main' --excluded-environments '' --states complete --shared-key=null
```
The last three flags are all the default options.
You could also leave them out and just accept the defaults when the CLI prompts you.
4. Redeploy your main environment by running this command:
```bash
platform environment:redeploy --environment main
```
5. After the activity has finished, see the JSON payload at the `webhook.site` page.
You can use its values to trigger anything you wish, including human-readable notifications elsewhere.
You can also run the redeploy command for the `dev` environment and verify that it doesn't send anything.
##### What's next
Your Platform.sh project is now up and running and you can keep track of it!
That's a great start to working with Platform.sh.
Now that you've mastered the basics, you can choose more advanced tasks to complete:
- Manage [multiple apps in a single project](https://docs.platform.sh/create-apps/multi-app.md).
- See how to set up for [local development](https://docs.platform.sh/development/local.md).
- Go live at a [custom domain](https://docs.platform.sh/domains/steps.md).
- Increase observability by [integrating Blackfire](https://docs.platform.sh/increase-observability/integrate-observability/blackfire.md)
- To maintain code in a third-party repository, integrate with [Bitbucket, GitHub, or GitLab](https://docs.platform.sh/integrations/source.md).
- Read more on [health notifications](https://docs.platform.sh/integrations/notifications.md).
- See a reference on [all options available for activity notifications](https://docs.platform.sh/integrations/activity/reference.md) or
use an [activity script](https://docs.platform.sh/integrations/activity.md) to manage activity responses in Platform.sh.
## Learn
### Philosophy
Platform.sh aims at reducing configuration and making developers more productive.
It abstracts your project infrastructure and manages it for you,
so you never have to configure services like a web server, a MySQL database, or a Redis cache from scratch again.
Platform.sh is built on one main idea — your server infrastructure is part of your app,
so it should be version controlled along with your app.
Every branch you push to your Git repository can come with bug fixes,
new features, **and** infrastructure changes.
You can then test everything as an independent deployment,
including your application code and all of your services with a copy of their data
(database entries, search index, user files, etc.).
This allows you to preview exactly what your site would look like if you merged your changes to production.
##### The basics
On Platform.sh, a **project** is linked to a Git repository and is composed of one or more **apps**.
An app is a directory in your Git repository with a specific Platform.sh configuration
and dedicated HTTP endpoints (via the `.platform.app.yaml` file).
Projects are deployed in **environments**.
An environment is a standalone copy of your live app which can be used for testing,
Q&A, implementing new features, fixing bugs, and so on.
Every project you deploy on Platform.sh is built as a *virtual cluster* containing a series of containers.
The main branch of your Git repository is always deployed as a production cluster.
Any other branch can be deployed as a staging or development cluster.
There are three types of containers within your cluster,
all configured by files stored alongside your code:
- The [*router*](https://docs.platform.sh/define-routes.md), configured in `.platform/routes.yaml`,
is a single Nginx process responsible for mapping incoming requests to an app container,
and for optionally providing HTTP caching.
- One or more [*apps*](https://docs.platform.sh/create-apps.md), configured via `.platform.app.yaml` files, holding the code of your project.
- Some optional [*services*](https://docs.platform.sh/add-services.md), configured in `.platform/services.yaml`,
like MySQL/MariaDB, Elasticsearch, Redis, or RabbitMQ.
They come as optimized pre-built images.
##### The workflow
Every time you deploy a branch to Platform.sh, the code is *built* and then *deployed* on a new cluster.
The [**build** process](https://docs.platform.sh/learn/overview/build-deploy.md#build-steps) looks through the configuration files in your repository
and assembles the necessary containers.
The [**deploy** process](https://docs.platform.sh/learn/overview/build-deploy.md#deploy-steps) makes those containers live, replacing the previous
versions, with no service downtime.
Depending on your needs, you can also [set up a **post-deploy** hook](#add-a-post-deploy-hook) to run after your app is deployed and your application container starts accepting traffic.
Adding a [`post-deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook) can be useful to run updates that don't require exclusive database access.
Note that if you're using [Gatsby](https://docs.platform.sh/guides/gatsby/headless.md) to pull from a backend container on the same environment,
you need a `post-deploy` hook to successfully build and deploy your app.
###### How your app is built
During the [build step](https://docs.platform.sh/learn/overview/build-deploy.md#build-steps),
dependencies specified in `.platform.app.yaml` are installed on application containers.
You can also customize the build step by providing a [`build` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#build-hook) composed of one or more shell commands
that help create your production codebase.
That could be compiling TypeScript files, running some scripts,
rearranging files on disk, or whatever else you want.
Note that at this point all you have access to is the filesystem;
there are **no services or other databases available**.
Your live website is unaffected.
Once the build step is completed, the filesystem is frozen and a read-only container image is created.
That filesystem is the final build artifact.
###### How your app is deployed
Before starting the [deployment](https://docs.platform.sh/learn/overview/build-deploy.md#deploy-steps) of your app,
Platform.sh pauses all incoming requests and holds them to avoid downtime.
Then, the current containers are stopped and the new ones are started.
Platform.sh then opens networking connections between the various containers,
as specified in the configuration files.
The connection information for each service is available from the [`PLATFORM_RELATIONSHIPS` environment variable](https://docs.platform.sh/development/variables/use-variables.md).
Similar to the build step, you can define a [deploy hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#deploy-hook) to prepare your app.
Your app has complete access to all services, but the filesystem where your code lives is now read-only.
Finally, Platform.sh opens the floodgates and lets incoming requests through your newly deployed app.
###### Add a post-deploy hook
You can add a [`post-deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook) to be run after the build and deploy steps.
Similar to the [`deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#deploy-hook),
the `post-deploy` hook only runs once your application container accepts requests.
So you can use it to run updates such as content imports or cache warmups that can be executed simultaneously with normal traffic.
During a redeploy, the `post-deploy` hook is the only hook that is run.
##### Get support
If you're facing an issue with Platform.sh,
open a [support ticket](https://docs.platform.sh/learn/overview/get-support.md).
##### What's next?
To get a feeling of what working with Platform.sh entails,
see the [Get Started](https://docs.platform.sh/get-started.md) framework guides.
### YAML
[YAML](https://en.wikipedia.org/wiki/YAML) is a human-readable format for data serialization across languages.
This means it's a good fit for human-edited configuration files, like those at Platform.sh.
You can control nearly all aspects of your project's build and deploy pipeline with YAML files.
Learn what YAML is or, if you're already familiar, what custom tags Platform.sh offers.
#### What YAML is
[YAML](https://en.wikipedia.org/wiki/YAML) is a human-readable format for data serialization.
This means it can be used for structured data, like what you can find in configuration files.
Some basic rules about YAML files:
- YAML files end in `.yaml`.
Some other systems use the alternative `.yml` extension.
- YAML is case-sensitive.
- YAML is whitespace-sensitive and indentation defines the structure,
but it doesn't accept tabs for indentation.
- Empty lines are ignored.
- Comments are preceded by an octothorpe `#`.
###### Data types
YAML represents data through three primitive data structures:
- Scalars (strings/numbers/booleans)
- Mappings (dictionaries/objects)
- Sequences (arrays/lists)
####### Scalars (strings/numbers/booleans)
The most straightforward data structure involves defining key–value pairs where the values are strings or integers.
So you could have a basic configuration for an app:
```yaml {location=".platform.app.yaml"}
name: myapp
type: "golang:1.18"
disk: 1024
```
This results in three key–value pairs:
| Key | Value |
| ------------------- |-------------------- |
| name | app |
| type | golang:1.18 |
| disk | 1024 |
You can define strings either with or without quotes, which can be single `'` or double `"`.
Quotes let you escape characters (if double) and make sure the value is parsed as a string when you want it.
For example, you might be representing version numbers and want to parse them as strings.
If you use `version: 1.10`, it's parsed as an integer and so is treated the same as `1.1`.
If you use `version: "1.10"`, it's parsed as a string and isn't treated as the same as `1.1`.
####### Mappings (dictionaries/objects)
In addition to basic scalar values, each key can also represent a set of other key–value pairs.
So you can define entire dictionaries of pairs.
The structure of the mapping is determined by the indentation.
So children are indented more than parents and siblings have the same amount of indentation.
The exact number of spaces in the indentation isn't important, just the level relative to the rest of the map.
In contrast, when you define mappings, the order doesn't matter.
So you could expand the configuration from before to add another mapping:
```yaml {location=".platform.app.yaml"}
name: myapp
type: "golang:1.18"
disk: 1024
web:
commands:
start: ./bin/app
locations:
'/':
passthru: true
allow: false
```
This creates a `web` dictionary that has two dictionaries within it: `commands` and `locations`,
each with their own mappings:
- `web` → `commands` → `start: ./bin/app`
- `web` → `locations` → `'/'` → `passthru: true` and `allow: false`
####### Sequences (arrays/lists)
In addition to maps defining further key–value pairs, you can also use sequences to include lists of information.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
index:
- index.html
- index.htm
passthru: true
allow: false
```
You can also define sequences using a flow syntax:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
index: [index.html, index.htm]
passthru: true
allow: false
```
In either case, you get a list of values within `index`:
`web` → `locations` → `'/'` → `index` → `index.html` and `index.htm`
###### Define multi-line strings
If you have a long string that spans multiple lines, use a pipe `|` to preserve line breaks.
The new lines need to have at least the same indentation as the first
(you can add more indentation that's then preserved).
So you could add a multi-line string to a `build` key in the `hooks` map:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -e
cp a.txt b.txt
```
And the resulting value preserves the line break.
This lets you do things like enter small shell scripts within a YAML file.
`hooks` → `build` → `set -e` and `cp a.txt b.txt`
###### Reuse content
YAML supports internal named references, known as anchors, which can be referenced using an alias.
This allows you to reuse YAML blocks in multiple places within a single file.
Define an anchor by adding `&` to the start of a value, where `` is a unique identifier.
The anchor represents this entire value.
Then refer to the anchor using `*`.
The following example shows 4 different workers:
```yaml {location=".platform.app.yaml"}
workers:
queue1: &runner
size: S
commands:
start: python queue-worker.py
queue2: *runner
queue3:
<<: *runner
size: M
queue4:
<<: *runner
disk: 512
```
- `queue1` and `queue2` are identical with the same `size` and `commands` properties.
- `queue3` is the same as `queue1` except that it has a different value for `size`.
- `queue4` is the same as `queue1` except that it has the `disk` property.
Note that you need to place an alias with `<<:` at the same level as the other keys within that value.
###### What's next
- See what Platform.sh makes possible with [custom tags](https://docs.platform.sh/learn/overview/yaml/platform-yaml-tags.md).
- Read everything that's possible with YAML in the [YAML specification](https://yaml.org/spec/1.2.2/).
- See a [YAML file that explains YAML syntax](https://learnxinyminutes.com/docs/yaml/).
#### Platform.sh YAML structure
In addition to the [basic functions you should be familiar with](https://docs.platform.sh/learn/overview/yaml/what-is-yaml.md), YAML structure is important.
Platform.sh accepts a certain structure for YAML configuration files.
When you run the `platform project:init` command, three default YAML configuration files are generated in the `.platform` folder and at the root of your source code. They contain the minimum default configuration based on your detected local stack.
These YAML files are a good starting point before customization.
```bash
.
├── .platform
| ├── routes.yaml
| └── services.yaml
├── .platform.app.yaml
└──
```
These three YAML files configure the following:
- ``routes.yaml``: this file contains all of your [routes definition](https://docs.platform.sh/define-routes.md)
- ``services.yaml``: this file contains the list of your [services definition](https://docs.platform.sh/add-services.md)
- ``.platform.app.yaml``: this file contains your [application definition](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md)
###### Examples
```yaml {location=".platform.app.yaml"}
# Complete list of all available properties
# A unique name for the app. Must be lowercase alphanumeric characters.
# Changing the name destroys data associated with the app.
name: "myapp"
# The runtime the application uses.
# Complete list of available runtimes
type: "php:8.2"
...
```
```yaml {location=".platform/services.yaml"}
# The services of the project.
#
# Each service listed will be deployed
# to power your Platform.sh project.
# Full list of available services
mariadb:
# All available versions are: 10.6, 10.5, 10.4, 10.3
type: mariadb:10.6
```
```yaml {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
# More information
"https://{default}/":
type: upstream
upstream: "myapp:http"
# A basic redirect definition
# More information
"https://www.{default}":
type: redirect
to: "https://{default}/"
```
In these files, you can use any of the [available YAML tags](https://docs.platform.sh/learn/overview/yaml/platform-yaml-tags.md) you need.
###### Multi-app
In a [multiple application](https://docs.platform.sh/create-apps/multi-app.md) context, you can also group all of your app configurations in a global ``.platform/applications.yaml`` file.
This file contains a list of app configurations, such as:
```yaml {location=".platform/applications.yaml"}
app1:
type: php:8.3
source:
root: app1
app2:
type: nodejs:20
source:
root: app2
```
#### Platform.sh YAML tags
In addition to the [basic functions you should be familiar with](https://docs.platform.sh/learn/overview/yaml/what-is-yaml.md), YAML allows for special tags.
Platform.sh accepts certain custom tags to facilitate working with configuration files.
These tags work with Platform.sh configuration files, but may not elsewhere.
###### Include
Use the `!include` tag to embed external files within a given YAML file.
The tag requires two properties:
| Property | Type | Possible values | Description |
| -------- | -------- | ----------------------------- |---------------------------------------------------------------------------------------------------------|
| `type` | `string` | `string`, `binary`, or `yaml` | See the descriptions of [strings](#string), [binaries](#binary), and [YAML](#yaml). Defaults to `yaml`. |
| `path` | `string` | | The path to the file to include, relative to the application directory or `source.root` if defined. |
By default, `path` is relative to the current application's directory (what you would define with `source.root`).
For example, to include another ``.platform/app1.yaml`` file in the main `.platform/applications.yaml`, follow these steps:
1. Write and save your ``.platform/app1.yaml`` file:
```yaml {location=".platform/app1.yaml"}
source:
root: "/"
type: "nodejs:20"
web:
commands:
start: "node index.js"
upstream:
socket_family: tcp
locations:
"/":
passthru: true
```
And including it:
```yaml {location=".platform/applications.yaml"}
myapp: !include
type: yaml
path: ./app1.yaml
# or as default type is "yaml", it could be:
#api: !include ./app1.yaml
```
You can also include files from a directory that is parent to the folder.
For example, for the following project structure:
```bash
.
├── .platform
| └── applications.yaml
├── backend
│ ├── main.py
│ ├── requirements.txt
│ └── scripts
│ ├── ...
│ └── common_build.sh
└── frontend
├── README.md
├── package-lock.json
├── package.json
├── public
├── scripts
│ └── clean.sh
└── src
```
This configuration is valid:
```yaml {location=".platform/applications.yaml"}
frontend:
source:
root: frontend
# ...
hooks:
build: !include
type: string
path: ../backend/scripts/common_build.sh
```
**Note**:
Platform.sh will execute this ``../backend/scripts/common_build.sh`` script using [Dash](https://wiki.archlinux.org/title/Dash).
####### `string`
Use `string` to include an external file inline in the YAML file as if entered as a multi-line string.
For example, if you have a build hook like the following:
```yaml {location=".platform/applications.yaml"}
frontend:
hooks:
build: |
set -e
cp a.txt b.txt
```
You could create a file for the script:
```text {location="build.sh"}
set -e
cp a.txt b.txt
```
And replace the hook with an include tag for an identical result:
```yaml {location=".platform/applications.yaml"}
frontend:
hooks:
build: !include
type: string
path: build.sh
```
This helps you break longer configuration like build scripts out into a separate file for easier maintenance.
####### `binary`
Use `binary` to include an external binary file inline in the YAML file.
The file is base64 encoded.
For example, you could include a `favicon.ico` file in the same folder as your app configuration.
Then you can include it as follows:
```yaml {location=".platform/applications.yaml"}
properties:
favicon: !include
type: binary
path: favicon.ico
```
####### `yaml`
Use `yaml` to include an external YAML file inline as if entered directly.
Because `yaml` is the default, you can use it without specifying the type.
For example, you could have your configuration for works defined in a `worker.yaml` file:
```yaml {location="worker.yaml"}
size: S
commands:
start: python queue-worker.py
variables:
env:
type: worker
```
Then the following three configurations are exactly equivalent:
```yaml {location=".platform.app.yaml"}
workers:
queue1: !include "worker.yaml"
```
```yaml {location=".platform.app.yaml"}
workers:
queue1: !include
type: yaml
path: 'worker.yaml'
```
```yaml {location=".platform.app.yaml"}
workers:
queue1:
size: S
commands:
start: python queue-worker.py
variables:
env:
type: worker
```
This can help simplify more complex files.
###### Archive
Use the `!archive` tag for a reference to an entire directory specified relative to where the YAML file is.
For example, you might want to define a configuration directory for your [Solr service](https://docs.platform.sh/add-services/solr.md).
You might do so as follows:
```yaml {location=".platform/services.yaml"}
mysearch:
type: solr:8.0
disk: 1024
configuration:
conf_dir: !archive "solr/conf"
```
The `!archive` tag means that the value for `conf_dir` isn't the string `solr/conf` but the entire `solr/conf` directory.
This directory is in the `.platform` directory, since that's where the `.platform/services.yaml` file is.
The `solr/conf` directory is then copied into the Platform.sh management system to use with the service.
### Structure
**Note**:
This page describes how things work on Grid projects.
For Dedicated Gen 2 projects, read about how [Dedicated Gen 2 projects are structured](https://docs.platform.sh/dedicated-environments/dedicated-gen-2/overview.md).
Each environment you deploy on Platform.sh is built as a set of containers.
Each container is an isolated instance with specific resources.
Each environment has 2 to 4 types of containers:
- One [*router*](#router) (configured in a `.platform/routes.yaml` file)
- One or more [*app* containers](#apps) (configured in `.platform.app.yaml` files)
- Zero or more [*service* containers](#services) (configured in a `.platform/services.yaml` file)
- Zero or more [*worker* containers](#workers) (configured in the files for apps)
If you have two app containers, two services (a database and a search engine), and a worker,
requests to your environment might look something like this:
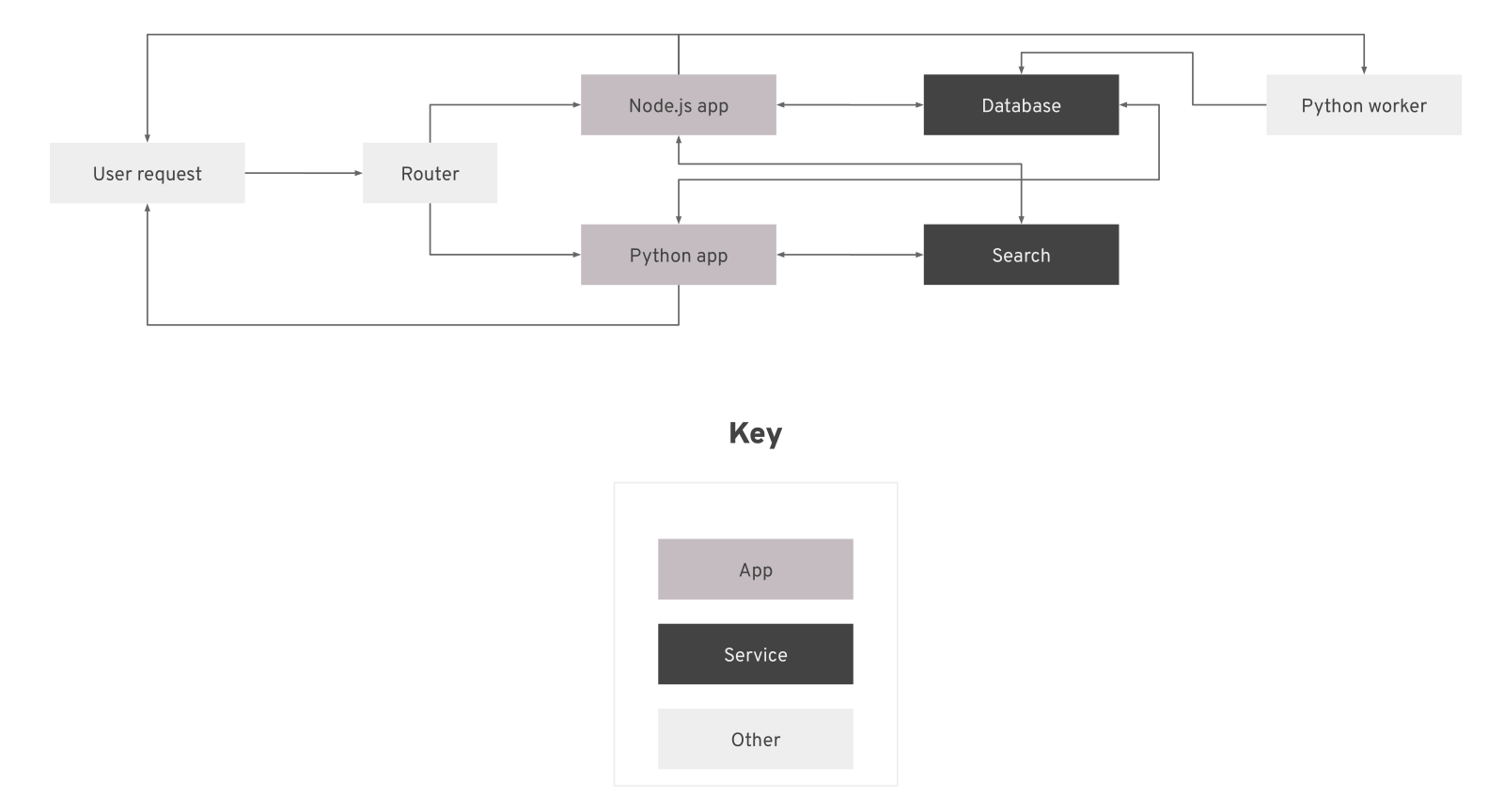
If you have only one app container, your repository might look like this:
```text
project
├── .git
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── .platform.app.yaml
└──
```
##### Router
Each environment always has exactly one router.
This router maps incoming requests to the appropriate app container
and provides basic caching of responses, unless configured otherwise.
The router is configured in a `.platform/routes.yaml` file.
If you don't include configuration, a single [default route is deployed](https://docs.platform.sh/define-routes.md#default-route-definition).
Read more about how to [define routes](https://docs.platform.sh/define-routes.md).
##### Apps
You always need at least one app container, but you can have more.
App containers run the code you provide via your Git repository.
They handle requests from the outside world and can communicate with other containers within the environment.
Each app container is built from a specific language image with a given version for the language.
To configure your apps, you usually create one `.platform.app.yaml` file for each app container.
A basic app generally has only one such file placed in the repository root.
Read more about how to [configure apps](https://docs.platform.sh/create-apps.md).
##### Services
You don't need any service containers, but you can add them as you like.
Service containers run predefined code for specific purposes, such as a database or search service.
You don't need to add their code yourself, just set up how your apps communicate with them.
Service containers are configured by the `.platform/services.yaml` file.
Read more about how to [add services](https://docs.platform.sh/add-services.md).
##### Workers
You don't need any worker containers, but you can add them as you like.
Worker containers are copies of an app containers
that have no access to the outside world and can have a different start command.
They're useful for continually running background processes.
Read more about how to [work with workers](https://docs.platform.sh/create-apps/workers.md).
### Build and deploy
Each time you push a change to your app through Git or activate an [environment](https://docs.platform.sh/environments.md),
your app goes through a process to be built and deployed.
If your app is redeployed with no changes to its codebase, the output of the previous build and deploy process is reused.
The build process looks through the configuration files in your repository and assembles the necessary containers.
The deploy process makes those containers live, replacing any previous versions, with minimal interruption in service.

Hooks are points in the build and deploy process where you can inject a custom script.
##### The build
The outcome of the build process is designed to be repeatable and reusable.
Each app in a project is built separately.
Container configuration depends exclusively on your configuration files.
So each container is tied to a specific Git commit.
If there are no new changes for a given container, the existing container can be reused.
This saves you the time the build step would take.
This means the build is independent of the given environment and preview environments are perfect copies of production.
If you use environment variables to set up different build configuration options for different environments,
your build step isn't reused and your preview environments may differ from production.
You can't connect to services (like databases) during the build step.
Once the app has gone through all of the build steps, it can connect to services in the deploy process.
###### Build steps
1. **Validate configuration**:
The configuration is checked by validating the `.platform` directory and scanning the repository for any app configurations to validate individually.
2. **Pull container images**:
Any container images that have been built before and that don't have any changes are pulled to be reused.
3. **Install dependencies**:
If you have specified additional global dependencies, they're downloaded during this step.
This is useful for commands you may need in the build hook.
4. **Run build flavor commands**:
For some languages (NodeJS, PHP), a series of standard commands are run based on the build flavor.
You can change the flavor or skip the commands by specifying it in your `.platform.app.yaml` file.
5. **Run build hook**:
The `build` hook comprises one or more shell commands that you write to finish creating your production code base.
It could be compiling Sass files, running a bundler, rearranging files on disk, or compiling.
The committed build hook runs in the build container.
During this time, commands have write access to the file system, but there aren't connections to other containers (services and other apps).
Note that you can [cancel deployments stuck on the build hook](https://docs.platform.sh/environments/cancel-activity.md).
6. **Freeze app container**:
The file system is frozen and produces a read-only container image, which is the final build artifact.
##### The deploy
The deploy process connects each container from the build process and any services.
The connections are defined in your app and services configuration.
So unlike the build process, you can now access other containers,
but the file system is read-only.
###### Deploy steps
1. **Hold requests**:
Incoming [idempotent requests](https://www.iana.org/assignments/http-methods/http-methods.xhtml) (like `GET`, `PUT`, `DELETE` but **not** `POST`, `PATCH` etc.) are held.
1. **Unmount current containers**:
Any previous containers are disconnected from their file system mounts.
1. **Mount file systems**:
The file system is connected to the new containers.
New branches have file systems cloned from their parent.
1. **Expose services**:
Networking connections are opened between any containers specified in your app and services configurations.
1. **Run (pre-) start commands**:
The [commands](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web-commands) necessary to start your app are run.
Often this stage will only include a start command, which is restarted if ever terminated going forward.
You may also, however, define a `pre_start` command, when you need to run _per-instance_ actions.
In this case, as you might expect, the `pre_start` command is run, then the `start` command.
1. **Run deploy hook**:
The `deploy` hook is any number of shell commands you can run to finish your deployment.
This can include clearing caches, running database migrations, and setting configuration that requires relationship information.
1. **Serve requests**:
Incoming requests to your newly deployed application are allowed.
After the deploy process is over, any commands in your `post_deploy` hook are run.
##### Deployment types
Platform.sh supports two deployment types - automatic and manual. These types help to provide control over when changes are applied to staging and production environments.
###### Automatic deployment (default)
This is the default behavior for all environments. With automatic deployment, changes like code pushes and variable updates are deployed immediately.
###### Manual deployment
When enabled, manual deployment lets you control when deployments happen. This means that changes will be staged but not deployed until explicitly triggered by the user. This type of deployment is ideal for teams that want to bundle multiple changes and deploy them together in a controlled manner.
When manual deployment is enabled in an environment, the following actions are queued until deployment is triggered:
| Category | Staged Activities |
|----------------------|------------------|
| **Code** | `environment.push`, `environment.merge`, `environment.merge-pr` |
| **Variables** | `environment.variable.create`, `update`, `delete` |
| **Resources** | `environment.resources.update` |
| **Domains & Routes** | `environment.domain.*`, `environment.route.*` |
| **Subscription** | `environment.subscription.update `|
| **Environment Settings** | `environment.update.http_access`, `smtp`, `restrict_robots` |
**Note**:
Note that development environments **always** use automatic deployment, while manual deployment is only available for staging and production environments.
###### Change deployment type
You can adjust deployment behavior in your environment (staging or production only).
The output should look similar to the example below:
```bash {}
Selected project: [my-project (ID)]
Selected environment: main (type: production)
Deployment type: manual
```
For more information about how this command works, use:
```bash {}
platform environment:deploy:type --help
```
To switch to manual, navigate to the environment settings in the Console and select the manual deployments option.
###### Trigger deployment manually
Once manual deployment is enabled, eligible changes are staged. You can deploy them in the following ways:
The output should look similar to the example below:
```bash {}
Deploying staged changes:
+---------------+---------------------------+-----------------------------------------------------------+---------+
| ID | Created | Description | Result |
+---------------+---------------------------+-----------------------------------------------------------+---------+
| 5uh3xwmkh5boq | 2024-11-22T14:01:10+00:00 | Patrick pushed to main | failure |
| fno2qiodq7e3c | 2024-11-22T13:06:18+00:00 | Arseni updated resource allocation on main | success |
| xzvcazrtoafeu | 2024-11-22T13:01:10+00:00 | Pilar added variable HELLO_WORLD to main | success |
| fq73u53ruwloq | 2024-11-22T12:06:17+00:00 | Pilar pushed to main | success |
+---------------+---------------------------+-----------------------------------------------------------+---------+
```
In the Console, a deploy button will be visible in the environment whenever changes are staged. Click this button to deploy your staged changes.Trigger the deployment of staged changes with the following:
```bash {}
POST /projects/{projectId}/environments/{environmentId}/deploy
```
**Note**:
As soon as your deployment type is switched from manual to automatic, all currently staged changes are deployed immediately and the environment resumes its default automatic deployment behavior.
##### Deployment philosophy
Platform.sh values consistency over availability, acknowledging that it's nearly impossible to have both.
During a deployment, the [deploy hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#deploy-hook) may make database changes
that are incompatible with the previous code version.
Having both old and new code running in parallel on different servers could therefore result in data loss.
Platform.sh believes that a minute of planned downtime for authenticated users is preferable to a risk of race conditions
resulting in data corruption, especially with a CDN continuing to serve anonymous traffic uninterrupted.
That brief downtime applies only to the environment changes are being pushed to.
Deployments to a staging or development branch have no impact on the production environment and cause no downtime.
##### What's next
* See how to [configure your app](https://docs.platform.sh/create-apps.md) for the entire process.
* Learn more about [using build and deploy hooks](https://docs.platform.sh/create-apps/hooks.md).
### Get support
Find out how to get help if you’re experiencing issues with Platform.sh.
##### Create a support ticket
If you're experiencing issues related to the proper functioning of the Platform.sh infrastructure, application container software, build processes, have found possible bugs, have general questions or wish to submit a feature request, open a support ticket:
1. [Open the Console](https://console.platform.sh/)
2. Click the **Help** dropdown in the upper right-hand corner.
3. Select **Support** from the options in the dropdown.
4. Click **+ New ticket**.
5. Fill in the ticket fields and click **Submit**.
Or use these shortcuts to [access all support tickets](https://console.platform.sh/-/users/~/tickets)
or [open a new ticket](https://console.platform.sh/-/users/~/tickets/open).
Once you submit a ticket, you see it in a list of all tickets created, for all projects you have access to, within your organization.
**Note**:
Note that once you submit the ticket, you can’t modify or delete the submission.
If you have any additional information, you can select the submitted ticket and write a message.
##### Discord
To talk about app development or framework-related questions,
join other customers and engineers in the [public Discord channel](https://chat.platform.sh/).
##### Community
The [Platform.sh Community site](https://community.platform.sh/) has how-to guides with suggestions
on how to get the most out of Platform.sh.
##### Contact Sales
If you have questions about pricing or need help figuring out if Platform.sh is the right solution for your team,
get in touch with [Sales](https://platform.sh/contact/).
##### Delete your account
To permanently delete your Platform.sh account, follow these steps:
**Warning**:
Deleting your Platform.sh account automatically deletes any linked Upsun, Ibexa Cloud, Pimcore PaaS, or Shopware PaaS accounts you may hold.
1. [Open the Console](https://console.platform.sh/).
2. Open the user menu (your name or profile picture) and select **My Profile**.
3. Click **Delete account**.
4. Check that the pre-filled information is correct and click **Submit**.
5. Read the consequences of account deletion and click **Submit request** to confirm.
Your request is now submitted and will be handled by Support shortly.
### Automate your code updates
Platform.sh allows you to update your dependencies through [source operations](https://docs.platform.sh/create-apps/source-operations.md).
##### Before you start
You need:
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md)
- An [API token](https://docs.platform.sh/administration/cli/api-tokens.md#2-create-an-api-token)
##### 1. Define a source operation to update your dependencies
To facilitate updating your dependencies in your project,
define a source operation in your `.platform.app.yaml` file
depending on your dependency manager:
```yaml {}
source:
operations:
update:
command: |
set -e
composer update
git add composer.lock
git add -A
git diff-index --quiet HEAD || git commit --allow-empty -m "Update Composer dependencies"
```
.platform.app.yaml
```yaml {}
source:
operations:
update:
command: |
set -e
npm update
git add package.json package-lock.json
git add -A
git diff-index --quiet HEAD || git commit --allow-empty -m "Update npm dependencies"
```
.platform.app.yaml
```yaml {}
source:
operations:
update:
command: |
set -e
yarn upgrade
git add yarn.lock
git add -A
git diff-index --quiet HEAD || git commit --allow-empty -m "Update yarn dependencies"
```
.platform.app.yaml
```yaml {}
source:
operations:
update:
command: |
set -e
go get -u
go mod tidy
git add go.mod go.sum
git add -A
git diff-index --quiet HEAD || git commit --allow-empty -m "Update Go dependencies"
```
.platform.app.yaml
```yaml {}
source:
operations:
update:
command: |
set -e
pipenv update
git add Pipfile Pipfile.lock
git add -A
git diff-index --quiet HEAD || git commit --allow-empty -m "Update Python dependencies"
```
.platform.app.yaml
```yaml {}
source:
operations:
update:
command: |
set -e
bundle update --all
git add Gemfile Gemfile.lock
git add -A
git diff-index --quiet HEAD || git commit --allow-empty -m "Update Ruby dependencies"
```
##### 2. Automate your dependency updates with a cron job
After you've defined a source operation to [update your dependencies on your project](#1-define-a-source-operation-to-update-your-dependencies),
you can automate it using a cron job.
Note that it’s best not to run source operations on your production environment,
but rather on a dedicated environment where you can test changes.
Make sure you have the [Platform.sh CLI](https://docs.platform.sh/administration/cli.md) installed
and [an API token](https://docs.platform.sh/administration/cli/api-tokens.md#2-create-an-api-token)
so you can run a cron job in your app container.
1. Set your API token as a top-level environment variable:
- Open the environment where you want to add the variable.
- Click Settings **Settings**.
- Click **Variables**.
- Click **+ Add variable**.
- In the **Variable name** field, enter ``env:PLATFORMSH_CLI_TOKEN``.
- In the **Value** field, enter your API token.
- Make sure the **Available at runtime** and **Sensitive variable** options are selected.
- Click **Add variable**.
**Note**:
Once you add the API token as an environment variable,
anyone with [SSH access](https://docs.platform.sh/development/ssh.md) can read its value.
Make sure you carefully check your [user access on this project](https://docs.platform.sh/administration/users.md#manage-project-users).
2. Add a build hook to your app configuration to install the CLI as part of the build process:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -e
echo "Installing Platform.sh CLI"
curl -fsSL https://raw.githubusercontent.com/platformsh/cli/main/installer.sh | bash
echo "Testing Platform.sh CLI"
platform
```
3. Then, to configure a cron job to automatically update your dependencies once a day,
use a configuration similar to the following:
```yaml {location=".platform.app.yaml"}
crons:
update:
# Run the code below every day at midnight.
spec: '0 0 * * *'
commands:
start: |
set -e
platform sync -e development code data --no-wait --yes
platform source-operation:run update --no-wait --yes
```
The example above synchronizes the `development` environment with its parent
and then runs the `update` source operation defined [previously](#1-define-a-source-operation-to-update-your-dependencies).
**Note**:
If you have enabled a [source integration](https://docs.platform.sh/integrations/source.md), and have enabled ``--fetch-branches`` on that
integration, merging on Platform.sh is not possible. Therefore, the ``sync`` command in the example above would
fail.
##### 3. Configure notifications about dependency updates
To get notified every time a source operation is triggered and therefore every time a dependency is updated,
you can configure activity scripts or webhooks.
###### Notifications through an activity script
After you've defined a source operation to [update your dependencies on your project](#1-define-a-source-operation-to-update-your-dependencies),
you can configure an activity script
to receive notifications every time a dependency update is triggered.
**Example**:
You want to get notified of every dependency update
through a message posted on a Slack channel.
To do so, follow these steps:
- In your Slack administrative interface, [create a new Slack webhook](https://api.slack.com/messaging/webhooks).
You get a URL starting with ``https://hooks.slack.com/``.
- Replace ``SLACK_URL`` in the following ``.js`` script with your webhook URL.
- Add the following code to a ``.js`` file:
```javascript {}
/**
* Sends a color-coded formatted message to Slack.
*
* To control what events trigger it, use the --events switch in
* the Platform.sh CLI.
*
* Replace SLACK_URL in the following script with your Slack webhook URL.
* Get one here: https://api.slack.com/messaging/webhooks
* You should get something like: const url = 'https://hooks.slack.com/...';
*
* activity.text: a brief, one-line statement of what happened.
* activity.log: the complete build and deploy log output, as it would be seen in the Console log screen.
*/
function sendSlackMessage(title, message) {
const url = 'SLACK_URL';
const messageTitle = title;
const color = activity.result === "success" ? "#66c000" : "#ff0000";
const body = {
attachments: [
{
title: messageTitle,
text: message,
color: color,
},
],
};
const resp = fetch(url, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(body),
});
if (!resp.ok) {
console.log("Sending slack message failed: " + resp.body.text());
}
}
sendSlackMessage(activity.text, activity.log);
```
- Run the following [Platform.sh CLI](https://docs.platform.sh/administration/cli.md) command:
```bash {}
platform integration:add --type script --file ./my_script.js --events=environment.source-operation
```
Optional: to only get notifications about specific environments,
add the following flag to the command: ``--environments=your_environment_name``.
Anytime a dependency is updated via a source operation,
the activity script now reports it to Slack.
###### Notifications through a webhook
After you've defined a source operation to [update your dependencies on your project](#1-define-a-source-operation-to-update-your-dependencies),
you can configure a webhook to receive notifications every time a dependency update is triggered.
[Webhooks](https://docs.platform.sh/integrations/activity/webhooks.md) allow you to host a script yourself externally.
This script receives the same payload as an activity script and responds to the same events,
but can be hosted on your own server and in your own language.
To configure the integration between your webhook and your source operation,
run the following [Platform.sh CLI](https://docs.platform.sh/administration/cli.md) command:
```bash
platform integration:add --type=webhook --url=URL_TO_RECEIVE_JSON --events=environment.source-operation
```
Optional: to only get notifications about specific environments,
add the following flag to the command: `--environments=your_environment_name`.
To test the integration and the JSON response,
you can generate a URL from a service such as [webhook.site](https://webhook.site)
and use the generated URL as `URL_TO_RECEIVE_JSON`.
This URL then receives the JSON response when a source operation is triggered.
Anytime a dependency is updated via a source operation,
the webhook now receives a POST message.
This POST message contains complete information about the entire state of the project at that time.
### Restrict access to a service
Platform.sh allows you to restrict access to a service.
In this tutorial, learn how to grant your Data team `read-only` access to your production database.
##### Before you start
You need:
- A project with a database service
- A `viewer` user on your project
##### 1. Add a read-only endpoint to your database service
Edit your `.platform/services.yaml` file and add the following [endpoints](https://docs.platform.sh/add-services/mysql/_index.md#define-permissions):
- `website` with `admin` access to the `main` database
- `reporting` with read-only `ro` access to the `main` database
```yaml {location=".platform/services.yaml"}
maindb:
type: mariadb:10.5
disk: 2048
configuration:
schemas:
- main
endpoints:
website:
default_schema: main
privileges:
main: admin
reporting:
privileges:
main: ro
```
##### 2. Grant your app access to the new endpoints
Edit your app configuration and add new relationships to your new endpoints:
```yaml {location=".platform.app.yaml"}
relationships:
database:
service: maindb
endpoint: website
reports:
service: maindb
endpoint: reporting
```
##### 3. Create a worker with access to the read-only endpoint
Edit your app configuration to add a new worker which:
- Does nothing (`sleep infinity`)
- Can access the read-only `reporting` endpoint
- Allows SSH access to `viewer`
```yaml {location=".platform.app.yaml"}
workers:
data_access:
size: S
disk: 128
mounts: {}
commands:
start: |
sleep infinity
relationships:
reports:
service: maindb
endpoint: reporting
access:
ssh: viewer
```
You're done!
From now on, your `viewer` users can SSH in to the worker application,
and connect to your database with read-only permissions.
### Converting to Platform.sh
If you already have an app running somewhere else, you want to convert it to Platform.sh and deploy it.
To do so, follow these steps.
##### Before you begin
You need:
- An app that works and is ready to be built
- Code in Git
- A Platform.sh account – if you don’t already have one, [start a trial](https://auth.api.platform.sh/register?trial_type=general)
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md) installed locally
##### 1. Export from previous system
Start by exporting everything you might need from your current app.
This includes data in databases, files on a file system,
and for some apps, such as Drupal, configuration that you need to export from the system into files.
##### 2. Create a project
When prompted, fill in details like the project name, [region](https://docs.platform.sh/development/regions.md), and [plan](https://docs.platform.sh/administration/pricing.md).
[Create a new project from scratch](https://console.platform.sh/org/create-project/info?_utm_campaign=cta_deploy_marketplace_template&utm_source=public_documentation&_utm_medium=organic).
In the form, fill in details like the project name and [region](https://docs.platform.sh/development/regions.md).
The project is automatically created with a [Development plan](https://docs.platform.sh/administration/pricing.md),
which you can then upgrade.
##### 3. Add configuration
The exact configuration you want depends on your app.
You likely want to configure three areas:
- [The app itself](https://docs.platform.sh/create-apps.md) -- this is the only required configuration
- [Services](https://docs.platform.sh/add-services.md)
- [Routes](https://docs.platform.sh/define-routes.md)
You can also take guidance from the [project templates](https://docs.platform.sh/development/templates.md),
which are starting points for various technology stacks with working configuration examples.
When you've added your configuration, make sure to commit it to Git.
##### 4. Push your code
The way to push your code to Platform.sh depends on
whether you're hosting your code with a third-party service using a [source integration](https://docs.platform.sh/integrations/source.md).
If you aren't, your repository is hosted in Platform.sh
and you can use the CLI or just Git itself.
- Add Platform.sh as a remote repository by running the following command:
```bash {}
platform project:set-remote
```
- Push to the Platform.sh repository by running the following command:
```bash {}
platform push
```
When you try to push, any detected errors in your configuration are reported and block the push.
After any errors are fixed, a push creates a new environment.
Set up the integration for your selected service:
- [Bitbucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Then push code to that service as you do normally.
Pushing to a branch creates an environment from that branch.
Note that the source integration doesn’t report any errors in configuration directly.
You have to monitor those in your project activities.
- Add an [SSH key](https://docs.platform.sh/development/ssh/ssh-keys.md).
- In the Console, open your project and click **Code **.
- Click **Git**.
- From the displayed command, copy the location of your repository.
It should have a format similar to the following:
```text {}
abcdefgh1234567@git.eu.platform.sh:abcdefgh1234567.git
```
- Add Platform.sh as a remote repository by running the following command:
```bash {}
git remote add platform
```
- Push to the Platform.sh repository by running the following command:
```bash {}
git push -u platform
```
When you try to push, any detected errors in your configuration are reported and block the push.
After any errors are fixed, a push creates a new environment.
##### 5. Import data
Once you have an environment, you can import the data you backed up in step 1.
The exact process may depend on the service you use.
For SQL databases, for example, you can use a version of this command:
```bash
platform sql <
```
For any potential more details, see the [specific service](https://docs.platform.sh/add-services.md).
##### 6. Import files
Your app may include content files, meaning files that aren't intended to be part of your codebase so aren't in Git.
You can upload such files to [mounts you created](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts).
Upload to each mount separately.
Suppose for instance you have the following file mounts defined:
```yaml {location=".platform.app.yaml"}
mounts:
'web/uploads':
source: local
source_path: uploads
'private':
source: local
source_path: private
```
Upload to each of directories above by running the following commands:
```bash
platform mount:upload --mount web/uploads --source ./uploads
platform mount:upload --mount private --source ./private
```
You can adjust these commands for your own case.
Or upload to your mounts using a different [SSH method](https://docs.platform.sh/development/file-transfer.md#transfer-files-using-an-ssh-client).
##### Optional: Add variables
If your app requires environment variables to build properly, [add them to your environment](https://docs.platform.sh/development/variables/set-variables.md).
##### What's next
Now that your app is ready to be deployed, you can do more:
- Upgrade from a Development plan.
- [Add a domain](https://docs.platform.sh/domains/steps.md).
- Set up for [local development](https://docs.platform.sh/development/local.md).
- Configure [health notifications](https://docs.platform.sh/integrations/notifications.md).
- For monitoring and profiling, [integrate Blackfire](https://docs.platform.sh/increase-observability/integrate-observability/blackfire.md).
### Exporting data
As a Platform.sh user, your code and data belong to you.
At any time, you can download your site's data for local development, to back up your data, or to change provider.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads)
- A Platform.sh account
- Code in your project
- Optional: the [Platform.sh CLI](https://docs.platform.sh/administration/cli.md)
##### 1. Download your app's code
Your app's code is maintained through the Git version control system.
To download your entire app's code history:
- Retrieve the project you want to back up by running the following command:
```bash {}
platform get
```
- In the [Console](https://console.platform.sh/), open your project and click **Code **.
- Click **Git**.
- To copy the command, click ** Copy**.
The command is similar to the following:
```text {}
git clone abcdefgh1234567@git.eu.platform.sh:abcdefgh1234567.git project-name
```
##### 2. Download your files
Some files might not be stored in Git,
such as data your app writes [in mounts](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts).
You can download your files [using the CLI](https://docs.platform.sh/development/file-transfer.md#transfer-files-using-the-cli) or [using SSH](https://docs.platform.sh/development/file-transfer.md#transfer-files-using-an-ssh-client).
##### 3. Download data from services
The mechanism for downloading from each service (such as your database) varies.
For services designed to hold non-persistent data, such as [Redis](https://docs.platform.sh/add-services/redis.md) or [Solr](https://docs.platform.sh/add-services/solr.md),
it's generally not necessary to download data as it can be rebuilt from the primary data store.
For services designed to hold persistent data, see each service's page for instructions:
- [MySQL](https://docs.platform.sh/add-services/mysql.md#exporting-data)
- [PostgreSQL](https://docs.platform.sh/add-services/postgresql.md#exporting-data)
- [MongoDB](https://docs.platform.sh/add-services/mongodb.md#exporting-data)
- [InfluxDB](https://docs.platform.sh/add-services/influxdb.md#export-data)
##### 4. Get environment variables
Environment variables can contain critical information such as tokens or additional configuration options for your app.
Environment variables can have different prefixes:
- Variables beginning with `env:` are exposed [as Unix environment variables](https://docs.platform.sh/development/variables.md#top-level-environment-variables).
- Variables beginning with `php:` are interpreted [as `php.ini` directives](https://docs.platform.sh/development/variables.md#php-specific-variables).
All other variables are [part of `$PLATFORM_VARIABLES`](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
To back up your environment variables:
Note that you can also get all the environment variable values by running the following command:
```bash {}
platform ssh -- env
```
- Store the data somewhere secure on your computer.
- In the [Console](https://console.platform.sh/), open your project and click **Settings**.
- Click **Project Settings **.
- Click **Variables** and access your variable’s values and settings.
- Store the data somewhere secure on your computer.
Note that in the Console, you can’t access the value of variables that have been [marked as sensitive](https://docs.platform.sh/development/variables/set-variables.md#variable-options).
Use the CLI to retrieve these values.
##### What's next
- Migrate data from elsewhere [into Platform.sh](https://docs.platform.sh/learn/tutorials/migrating.md).
- Migrate to [another region](https://docs.platform.sh/projects/region-migration.md).
- To use data from an environment locally, export your data and set up your [local development environment](https://docs.platform.sh/development/local.md).
### HTTP caching
You can configure HTTP caching for your site on Platform.sh in several ways.
Which one you should use depends on your specific use case.
You should use only one of these at a time and disable any others.
Mixing them together most likely results in stale cache that can't be cleared.
##### The Platform.sh router cache
Every project includes a router instance that includes [optional HTTP caching](https://docs.platform.sh/define-routes/cache.md).
It's reasonably configurable and obeys HTTP cache directives, but doesn't support push-based clearing.
If you're uncertain what caching tool to use, start with this one.
It's enough for most uses.
##### A Content Delivery Network (CDN)
Platform.sh is compatible with most commercial CDNs.
If you have a Dedicated instance, it comes with the [Fastly CDN](https://docs.platform.sh/domains/cdn/fastly.md).
CDNs generally offer the best performance as they're the only option that includes multiple geographic locations.
But they do tend to be the most expensive option.
See more on setting up [Fastly](https://docs.platform.sh/domains/cdn/fastly.md) and [Cloudflare](https://docs.platform.sh/domains/cdn/cloudflare.md).
The methods for other CDNs are similar.
##### Varnish
Platform.sh offers a [Varnish service](https://docs.platform.sh/add-services/varnish.md) that you can insert between the router and your app.
It has roughly the same performance as the router cache.
Varnish is more configurable, but it requires you to be comfortable with Varnish Configuration Language (VCL).
Platform.sh doesn't help with VCL configuration and a misconfiguration may be difficult to debug.
Varnish supports [clearing cache with a push](https://docs.platform.sh/add-services/varnish.md#clear-cache-with-a-push),
but access control is complicated by the inability to have [circular relationships](https://docs.platform.sh/add-services/varnish.md#circular-relationships).
Generally speaking, you should use Varnish only if your application requires push-based clearing or relies on Varnish-specific business logic.
##### App-specific caching
Many web apps and frameworks include a built-in web cache layer that mimics what Varnish or the Router cache would do.
Most of the time they're slower than a dedicated caching service as they still require invoking the app server
and only serve as a fallback for users that don't have a dedicated caching service available.
Generally speaking, use app-specific web cache only when it includes app-specific business logic you depend on,
such as app-sensitive selective cache clearing or partial page caching.
Note that this refers only to HTTP caching.
Many apps have an internal app cache for data objects and similar information.
That should remain active regardless of the HTTP cache in use.
##### Cookies and caching
HTTP-based caching systems generally default to including cookie values in cache keys
to avoid serving authenticated content to the wrong user.
While this is a safe default, it means that *any* cookie effectively disables the cache,
including mundane cookies like analytics.
The solution is to set which cookies should impact the cache and limit them to session cookies.
For the router cache, see [cookies in HTTP caching](https://docs.platform.sh/define-routes/cache.md#cookies).
For other cache systems, consult their documentation.
### From monoliths through headless to microservices
With Platform.sh, you can run multiple application containers in a single environment.
This gives you access to a large variety of setups and allows you to seamlessly upgrade your app
from a monolith with a single application server to a more elaborate and effective topology.
You can set up multiple apps to achieve the following:
- Keep your backend and frontend systems separate
- Run workers alongside your main app
- Or even go for a full microservices architecture
Platform.sh makes implementing such setups and switching from one to the other pain-free.
The same flexibility applies to any supported services, from relational databases to search engines and message queues.
Depending on your specific use case, you can run a single database,
multiple databases inside a single instance, or multiple databases in multiple versions...
It's up to you!
Whether you embrace a mono-repo approach with a single Git repository describing your entire setup,
or divide your project into multiple repositories, Platform.sh allows you to build the best architecture for your needs.
But while the possibilities are endless, making the right choice between creating one big project with multiple apps
or keeping each app in its own project can be a tough formula to crack.
So read on for guidance!
##### Separate projects
If you have multiple apps sharing the same code but each of them has its own data,
keep your apps in separate projects.
Platform.sh provides the automation to deploy multiple projects from the same code base,
which makes their maintenance effortless.
**Note**:
By design, Platform.sh doesn’t allow your app to access services in another project through HTTP.
So separate projects are appropriate in the following cases:
- Your apps are for different customers/clients
- Your apps don't need to directly connect to the same database
- Different teams are working on different apps
- You want to develop true microservices, where each microservice is a fully standalone process with its own data
When in doubt over your own needs,
it's better to keep separate projects than build an architecture that may prove difficult for you to maintain.
##### Clustered applications
A clustered application is one where your project requires multiple _app services_ that are all part of the same conceptual project.
Clustered applications can range from a straightforward headless architecture, where frontend and backend systems are separated,
to micro-services with dozens of apps in multiple runtimes and frameworks forming a consistent whole.
Meaning, removing one of the app services would break the others.
Platform.sh allows you to configure access from one service to another
without having to worry about service discovery or complex _ingress controllers_.
[Configuring incoming routes](https://docs.platform.sh/define-routes.md) is straightforward.
You can have services that are only exposed to another service as well as services that are exposed to the internet.
In a clustered application, you can have one of the following configurations:
- Multiple [`.platform.app.yaml` files](https://docs.platform.sh/create-apps/multi-app.md) in different directories, with separate code bases that deploy separately
- A single app that spawns one or more [worker instances](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#workers) that run background processes
**Note**:
Note that a clustered application requires at least a [Medium](https://platform.sh/pricing/).
With a clustered application, you often don't need multiple service instances.
The [MySQL, MariaDB](https://docs.platform.sh/add-services/mysql.md),
and [Solr](https://docs.platform.sh/add-services/solr.md) services support defining multiple databases on a single service,
which is significantly more efficient than defining multiple services.
[Redis](https://docs.platform.sh/add-services/redis.md), [Memcached](https://docs.platform.sh/add-services/memcached.md),
[Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md), and [RabbitMQ](https://docs.platform.sh/add-services/rabbitmq.md)
natively support multiple bins (also called _queues_ or _indexes_) defined by the client application as part of the request.
Therefore, they don't need additional configuration on Platform.sh.
Clustered applications are appropriate in the following cases:
- You want one user-facing app and an entirely separate admin-facing app that are both operating on the same data
- You want to have a user-facing app and a separate worker process (either the same code or separate) that handles background tasks
- You want a single conceptual app written in multiple programming languages
##### A note on "multi-site" applications
Some Content Management Systems or other applications support running multiple logical "sites" off of a single code base.
This approach isn't recommended on Platform.sh.
This multi-site logic is often dependent on the domain name of the incoming request, which on Platform.sh varies by branch.
Running multiple databases, as is often recommended with this approach,
is supported on Platform.sh but makes the setup process for each site more difficult.
Leveraging the multi-site capabilities of an app are appropriate only in the following cases:
- There is only a single team working on all of the "sites" involved
- All "sites" should be updated simultaneously as a single unit
- Each individual site is relatively low traffic, such that the aggregate traffic is appropriate for your plan size
- All sites really do use the same codebase with no variation, just different data
Otherwise, [separate projects](#separate-projects) are a better long-term plan.
### Keep your Git repository clean
When a Git repository contains a high number of references and files, the performance of Git can decrease.
This is why most Git providers have repository size limits in place (for more information, see the [GitHub](https://docs.github.com/en/repositories/working-with-files/managing-large-files/about-large-files-on-github), [GitLab](https://docs.gitlab.com/ee/user/gitlab_com/index.md#account-and-limit-settings)
and [Bitbucket](https://support.atlassian.com/bitbucket-cloud/docs/reduce-repository-size/) documentation).
The Platform.sh API and [Console](https://docs.platform.sh/administration/web.md) are closely tied to Git.
When the performance of Git decreases, Platform.sh API servers also become slower.
As a user, you can then experience significant latencies.
If your repository becomes too large, your Console may even become unresponsive,
leaving you unable to access your project.
To avoid such issues, make sure you keep your Git repository clean by following the instructions on this page.
If you're already facing performance issues and suspect they might be related to the size of your Git repository,
see how you can [troubleshoot a sizeable Git repository](#troubleshoot-a-sizeable-git-repository).
##### Enable the automated pruning of old branches in your project
To keep your repository size to a minimum,
make sure that branches that don't exist anymore in your repository have also been deleted from Platform.sh.
To automate this process, when setting up a [source integration](https://docs.platform.sh/integrations.md),
enable the `prune-branches` option.
If you already have a source integration set up and want to enable the `prune-branches` option,
follow these steps:
- Then, to enable the ``prune-branches`` option, run the following command:
```bash {}
platform integration:update --project --prune-branches true
```
- Navigate to your project.
- Click Settings **Settings**.
- Click **Project Settings**.
- Click **Integrations** and select your source integration.
- Click **Edit**.
- Enter your access token and click **Continue**.
- Select your repository and check the following boxes:
- **Fetch branches from the remote repository to your project** (``fetch-branches`` option, mandatory to enable ``prune-branches``).
- **Remove branches from your project that have disappeared remotely (requires the fetch branches option to be enabled)** (``prune-branches`` option).
- Click **Save**.
##### Upload your files through mounts
Keeping too many files, especially large binary files, in your Git repository can cause performance and stability issues.
Therefore, Platform.sh recommends that you only commit your source code in Git.
To upload any other files to your app, [create mounts](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts)
and [transfer your files directly to them](https://docs.platform.sh/development/file-transfer.md#transfer-a-file-to-a-mount).
**Note**:
Platform.sh does not currently support [Git Large File Storage](https://git-lfs.com/).
There is a **100MB default file size limit** for direct Git pushes to Platform.sh. Pushing files larger than the limit will result in rejecting the push, so please keep this in mind. If you’d like to request a custom limit, please [contact Support](https://docs.platform.sh/learn/overview/get-support.md).
##### Troubleshoot a sizeable Git repository
If you're experiencing latencies or can't access your Console anymore,
your Git repository may have become too large and may need to be cleaned up.
To do so, follow these instructions:
1. Remove old, unwanted files from your repository (especially large files).
You can do it manually, or use a tool such as [BFG Repo-Cleaner](https://rtyley.github.io/bfg-repo-cleaner/).
2. Remove stale branches from your repository and Platform.sh project.
3. Rebase and/or squash commits to clean up your history.
4. Make sure you [enable the automated pruning of old branches in your project](#enable-the-automated-pruning-of-old-branches-in-your-project)
and [upload your files through mounts](#upload-your-files-through-mounts) to avoid facing the same situation in the future.
## Frameworks
### Deploy Django on Platform.sh
Django is a web application framework written in Python with a built-in ORM (Object-Relational Mapper).
This guide provides instructions for deploying, and working with, Django on Platform.sh.
It includes examples for working with Django on all of the major package managers: pip, Pipenv, and Poetry.
To get Django running on Platform.sh, you have two potential starting places:
- You already have a Django site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic Django site.
See an example for doing this under initializing a project.
- Use a ready-made [Django template](https://github.com/platformsh-templates/django4).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Django template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
**Note**:
This guide is written for Django 4, but should apply almost exactly the same for other versions.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
If you don’t have code, create a new Django project from scratch.
The following commands create a brand new Django project using [Django Admin](https://docs.djangoproject.com/en/4.1/intro/tutorial01/#creating-a-project).
```bash {}
django-admin startproject
cd
git init
git add . && git commit -m "Create basic Django app."
```
The community also provides a number of open-source starting points you can consult:
- [django-simple-deploy](https://github.com/ehmatthes/django-simple-deploy) maintained by [@ehmatthes](https://github.com/ehmatthes)
- [djangox](https://github.com/wsvincent/djangox) maintained by [@wsvincent](https://github.com/wsvincent)
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/django/deploy/configure.md)
#### Configure Django for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml && touch .platform.app.yaml
```
Now that you've added these files to your project,
configure each one for Django in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Django requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
The examples vary based on whether you use Pip, Pipenv, or Poetry to manage dependencies.
```yaml {}
#########################
# Django 4 using pip
##########################
# Container configuration.
# Complete list of all available properties: https://docs.platform.sh/create-apps/app-reference.html
# A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated
# with the app.
name: 'app'
# The runtime the application uses.
# Complete list of available runtimes: https://docs.platform.sh/create-apps/app-reference.html#types
type: 'python:3.10'
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
# More information: https://docs.platform.sh/create-apps/app-reference.html#relationships
relationships:
database: "db:postgresql"
# The size of the persistent disk of the application (in MB). Minimum value is 128.
disk: 512
# Mounts define directories that are writable after the build is complete. If set as a local source, disk property is required.
# More information: https://docs.platform.sh/create-apps/app-reference.html#mounts
mounts:
'logs':
source: local
source_path: logs
# The web key configures the web server running in front of your app.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web
web:
# Commands are run once after deployment to start the application process.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web-commands
commands:
# The command to launch your app. If it terminates, it’s restarted immediately.
start: "gunicorn -w 4 -b unix:$SOCKET myapp.wsgi:application"
# More information: https://docs.platform.sh/configuration/app-containers.html#upstream
upstream:
# Whether your app should speak to the webserver via TCP or Unix socket. Defaults to tcp
# More information: https://docs.platform.sh/create-apps/app-reference.html#where-to-listen
socket_family: unix
# Each key in locations is a path on your site with a leading /.
# More information: https://docs.platform.sh/create-apps/app-reference.html#locations
locations:
"/":
# Whether to forward disallowed and missing resources from this location to the app. A string is a path
# with a leading / to the controller, such as /index.php.
passthru: true
"/static":
# The directory to serve static assets for this location relative to the app’s root directory. Must be an
# actual directory inside the root directory.
root: "static"
# The number of seconds whitelisted (static) content should be cached.
expires: 1h
# Whether to allow serving files which don’t match a rule.
allow: true
# Hooks allow you to customize your code/environment as the project moves through the build and deploy stages
# More information: https://docs.platform.sh/create-apps/app-reference.html#hooks
hooks:
# The build hook is run after any build flavor.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#build-hook
build: |
set -eu
# Download the latest version of pip
python3.10 -m pip install --upgrade pip
# Install dependencies
pip install -r requirements.txt
# Collect static assets
python manage.py collectstatic
# The deploy hook is run after the app container has been started, but before it has started accepting requests.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#deploy-hook
deploy: python manage.py migrate
```
.platform.app.yaml
```yaml {}
#########################
# Django4 using pipenv
##########################
# Container configuration.
# Complete list of all available properties: https://docs.platform.sh/create-apps/app-reference.html
# A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated
# with the app.
name: 'app'
# The runtime the application uses.
# Complete list of available runtimes: https://docs.platform.sh/create-apps/app-reference.html#types
type: 'python:3.10'
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
# More information: https://docs.platform.sh/create-apps/app-reference.html#relationships
relationships:
database: "db:postgresql"
# The size of the persistent disk of the application (in MB). Minimum value is 128.
disk: 512
# Mounts define directories that are writable after the build is complete. If set as a local source, disk property is required.
# More information: https://docs.platform.sh/create-apps/app-reference.html#mounts
mounts:
'logs':
source: local
source_path: logs
'.cache':
source: local
source_path: cache
# The web key configures the web server running in front of your app.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web
web:
# Commands are run once after deployment to start the application process.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web-commands
commands:
# The command to launch your app. If it terminates, it’s restarted immediately.
start: "pipenv run gunicorn -w 4 -b unix:$SOCKET myapp.wsgi:application"
# More information: https://docs.platform.sh/configuration/app-containers.html#upstream
upstream:
# Whether your app should speak to the webserver via TCP or Unix socket. Defaults to tcp
# More information: https://docs.platform.sh/create-apps/app-reference.html#where-to-listen
socket_family: unix
# Each key in locations is a path on your site with a leading /.
# More information: https://docs.platform.sh/create-apps/app-reference.html#locations
locations:
"/":
# Whether to forward disallowed and missing resources from this location to the app. A string is a path
# with a leading / to the controller, such as /index.php.
passthru: true
"/static":
# The directory to serve static assets for this location relative to the app’s root directory. Must be an
# actual directory inside the root directory.
root: "static"
# The number of seconds whitelisted (static) content should be cached.
expires: 1h
# Whether to allow serving files which don’t match a rule.
allow: true
# Installs global dependencies as part of the build process. They’re independent of your app’s dependencies and
# are available in the PATH during the build process and in the runtime environment. They’re installed before
# the build hook runs using a package manager for the language.
# More information: https://docs.platform.sh/create-apps/app-reference.html#dependencies
dependencies:
python3:
pipenv: '2022.9.4'
# Hooks allow you to customize your code/environment as the project moves through the build and deploy stages
# More information: https://docs.platform.sh/create-apps/app-reference.html#hooks
hooks:
# The build hook is run after any build flavor.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#build-hook
build: |
set -eu
# Download the latest version of pip
python3.10 -m pip install --upgrade pip
# Install dependencies
pipenv install --deploy
# Collect static assets
pipenv run python manage.py collectstatic
# The deploy hook is run after the app container has been started, but before it has started accepting requests.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#deploy-hook
deploy: pipenv run python manage.py migrate
```
.platform.app.yaml
```yaml {}
#########################
# Django4 using Poetry
##########################
# Container configuration.
# Complete list of all available properties: https://docs.platform.sh/create-apps/app-reference.html
# A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated
# with the app.
name: 'app'
# The runtime the application uses.
# Complete list of available runtimes: https://docs.platform.sh/create-apps/app-reference.html#types
type: 'python:3.10'
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
# More information: https://docs.platform.sh/create-apps/app-reference.html#relationships
relationships:
database: "db:postgresql"
# The size of the persistent disk of the application (in MB). Minimum value is 128.
disk: 512
# Mounts define directories that are writable after the build is complete. If set as a local source, disk property is required.
# More information: https://docs.platform.sh/create-apps/app-reference.html#mounts
mounts:
'logs':
source: local
source_path: logs
# The web key configures the web server running in front of your app.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web
web:
# Commands are run once after deployment to start the application process.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web-commands
commands:
# The command to launch your app. If it terminates, it’s restarted immediately.
start: "poetry run gunicorn -w 4 -b unix:$SOCKET myapp.wsgi:application"
# More information: https://docs.platform.sh/configuration/app-containers.html#upstream
upstream:
# Whether your app should speak to the webserver via TCP or Unix socket. Defaults to tcp
# More information: https://docs.platform.sh/create-apps/app-reference.html#where-to-listen
socket_family: unix
# Each key in locations is a path on your site with a leading /.
# More information: https://docs.platform.sh/create-apps/app-reference.html#locations
locations:
"/":
# Whether to forward disallowed and missing resources from this location to the app. A string is a path
# with a leading / to the controller, such as /index.php.
passthru: true
"/static":
# The directory to serve static assets for this location relative to the app’s root directory. Must be an
# actual directory inside the root directory.
root: "static"
# The number of seconds whitelisted (static) content should be cached.
expires: 1h
# Whether to allow serving files which don’t match a rule.
allow: true
# Variables to control the environment. More information: https://docs.platform.sh/create-apps/app-reference.html#variables
variables:
env:
POETRY_VIRTUALENVS_IN_PROJECT: true
POETRY_VIRTUALENVS_CREATE: false
# Hooks allow you to customize your code/environment as the project moves through the build and deploy stages
# More information: https://docs.platform.sh/create-apps/app-reference.html#hooks
hooks:
# The build hook is run after any build flavor.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#build-hook
build: |
set -eu
# Download the latest version of pip
python3.10 -m pip install --upgrade pip
# Install and configure Poetry
# NOTE: There is a matching export PATH=... in `.environment`, which allows the use of Poetry
# in the deploy hook, start command, and during SSH sessions. Make sure to include in your
# own projects.
export PIP_USER=false
curl -sSL https://install.python-poetry.org | python3 - --version $POETRY_VERSION
export PATH="/app/.local/bin:$PATH"
export PIP_USER=true
# Install dependencies
poetry install
# Collect static assets
poetry run python manage.py collectstatic
# The deploy hook is run after the app container has been started, but before it has started accepting requests.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#deploy-hook
deploy: poetry run python manage.py migrate
```
####### How to start your app
Each of these examples includes a command to start your app under `web.commands.start`.
It uses the Gunicorn WSGI server and Unix sockets.
```yaml {}
web:
upstream:
socket_family: unix
commands:
start: "gunicorn -w 4 -b unix:$SOCKET myapp.wsgi:application"
```
.platform.app.yaml
```yaml {}
web:
upstream:
socket_family: unix
commands:
start: "pipenv run gunicorn -w 4 -b unix:$SOCKET myapp.wsgi:application"
```
.platform.app.yaml
```yaml {}
web:
upstream:
socket_family: unix
commands:
start: "poetry run gunicorn -w 4 -b unix:$SOCKET myapp.wsgi:application"
```
To use this server, update the command to replace the WSGI application Gunicorn calls.
The example uses a `myapp/wsgi.py` file with a callable `application`.
To use a different web server, change this start command.
For examples of how to do so, see more about [Python web servers](https://docs.platform.sh/languages/python/server.md).
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure Django to use those services once they're enabled.
Each service entry has a name (`db` in the example)
and a `type` that specifies the service and version to use.
Services that store persistent data have a `disk` key, to specify the amount of storage.
Below is an example configuration to make [PostgreSQL](https://docs.platform.sh/add-services/postgresql.md) available for your Django application.
```yaml {location=".platform/services.yaml"}
# The services of the project.
#
# Each service listed will be deployed
# to power your Platform.sh project.
# More information: https://docs.platform.sh/add-services.html
# Full list of available services: https://docs.platform.sh/add-services.html#available-services
db:
type: postgresql:12
disk: 1024
```
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Django app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
# More information: https://docs.platform.sh/define-routes.html
"https://{default}/":
type: upstream
upstream: "app:http"
# A basic redirect definition
# More information: https://docs.platform.sh/define-routes.html#basic-redirect-definition
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
#### Customize Django for Platform.sh
Now that your code contains all of the configuration to deploy on Platform.sh,
it's time to make your Django site itself ready to run on a Platform.sh environment.
A number of additional steps are either required or recommended, depending on how much you want to optimize your site.
###### Optional: Set up the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
In all of the following examples,
you can replace retrieving and decoding environment variables with this library.
###### Django configuration
Most configuration for Django, such as service credentials, is done in a `settings.py` file.
You can see an example of a [complete settings file in the Django template](https://github.com/platformsh-templates/django4/blob/master/myapp/settings.py).
The example file configures app settings and credentials for connecting to a PostgreSQL database.
The environment variables defined there enable Django apps to remain independent of their environment.
The example file itself contains a lot of settings,
the most important of which are highlighted here to show where you could modify your code.
####### Allowed hosts
[`ALLOWED_HOSTS`](https://docs.djangoproject.com/en/4.1/ref/settings/#allowed-hosts) defines the host names that your Django site can serve.
It's where you define `localhost` and also your site's primary domain.
On Platform.sh, every branch or pull request you create can become an active environment:
a deployed site where you can test changes.
The environment is given a URL that ends with `.platform.site`.
To allow your site to serve these environment, add this suffix to `ALLOWED_HOSTS`.
```py {location="settings.py"}
ALLOWED_HOSTS = [
'localhost',
'127.0.0.1',
'.platformsh.site',
]
```
####### Decoding variables
Platform.sh environment variables, which contain information on deployed environments, are often obscured.
For example, `PLATFORM_RELATIONSHIPS`, which contains credentials to connect to services, is a base64-encoded JSON object.
The example Django configuration file has a `decode` helper function to help with these variables.
Alternatively, you can use the [Platform.sh Config Reader](#optional-set-up-the-config-reader).
```py {location="settings.py"}
#################################################################################
# Platform.sh-specific configuration
# Helper function for decoding base64-encoded JSON variables.
def decode(variable):
"""Decodes a Platform.sh environment variable.
Args:
variable (string):
Base64-encoded JSON (the content of an environment variable).
Returns:
An dict (if representing a JSON object), or a scalar type.
Raises:
JSON decoding error.
"""
try:
if sys.version_info[1] > 5:
return json.loads(base64.b64decode(variable))
else:
return json.loads(base64.b64decode(variable).decode('utf-8'))
except json.decoder.JSONDecodeError:
print('Error decoding JSON, code %d', json.decoder.JSONDecodeError)
```
####### Handling overrides
Once you have a [way to decode variables](#decoding-variables),
you can use them to override settings based on the environment.
The following example uses the `decode` function to set access to the one service defined in this example,
a PostgreSQL database.
```py {location="settings.py"}
# This variable must always match the primary database relationship name,
# configured in .platform.app.yaml.
PLATFORMSH_DB_RELATIONSHIP="database"
# Import some Platform.sh settings from the environment.
# The following block is only applied within Platform.sh environments
# That is, only when this Platform.sh variable is defined
if (os.getenv('PLATFORM_APPLICATION_NAME') is not None):
DEBUG = False
# Redefine the static root based on the Platform.sh directory
# See https://docs.djangoproject.com/en/4.1/ref/settings/#static-root
if (os.getenv('PLATFORM_APP_DIR') is not None):
STATIC_ROOT = os.path.join(os.getenv('PLATFORM_APP_DIR'), 'static')
# PLATFORM_PROJECT_ENTROPY is unique to your project
# Use it to define define Django's SECRET_KEY
# See https://docs.djangoproject.com/en/4.1/ref/settings/#secret-key
if (os.getenv('PLATFORM_PROJECT_ENTROPY') is not None):
SECRET_KEY = os.getenv('PLATFORM_PROJECT_ENTROPY')
# Database service configuration, post-build only
# As services aren't available during the build
if (os.getenv('PLATFORM_ENVIRONMENT') is not None):
platformRelationships = decode(os.getenv('PLATFORM_RELATIONSHIPS'))
db_settings = platformRelationships[PLATFORMSH_DB_RELATIONSHIP][0]
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': db_settings['path'],
'USER': db_settings['username'],
'PASSWORD': db_settings['password'],
'HOST': db_settings['host'],
'PORT': db_settings['port'],
},
'sqlite': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
```
As noted in comments in the example, services on Platform.sh (like PostgreSQL) aren't yet available during the build.
This it enables the environment-independent builds that make the Platform.sh inheritance model possible.
For this reason, when defining a service connection, you need to overwrite the settings during the deploy phase.
You can determine the deploy phase using the `PLATFORM_ENVIRONMENT` variable, which is only available at deploy time.
###### `.environment` and Poetry
`source .environment` is run in the [app root](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#root-directory)
when a project starts, before cron commands are run, and when you log into an environment over SSH.
So you can use the `.environment` file to make further changes to environment variables before the app runs,
including modifying the system `$PATH` and other shell level customizations.
Django projects like this example using Pip or Pipenv don't need a `.environment` file to run.
Using Poetry requires additional configuration to ensure that Poetry can be called during the deploy phase and SSH sessions.
```text {location=".environment"}
# Updates PATH when Poetry is used, making it available during deploys and SSH.
if [ -n "$POETRY_VERSION" ]; then
export PATH="/app/.local/bin:$PATH"
fi
```
If you have other environment variables your app depends on that aren't sensitive and so can be committed to Git,
you can include them in the `.environment` file
#### Deploy Django
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your user files to your local `files/user` directory and your public files to `files/public`
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount src/main/resources/files/user --source ./files/user
platform mount:upload --mount src/main/resources/files/public --source ./files/public
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
**Note**:
The example Django app used in this guide can be migrated solely by importing data into the database.
Other forms of data, such as user uploads, also need to be migrated in the way described above.
To see how to define directories that are writable at runtime, see the [mounts reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts).
Then adjust the previous commands to upload files to them.
Go forth and Deploy (even on Friday)!
#### Additional resources
###### Local development
Once Django has been deployed on Platform.sh, you need to set up a local development environment to begin making revisions.
For more information, consult the [Django local development guides](https://docs.platform.sh/guides/django/local.md).
###### Package management
pip comes pre-installed on all Python containers.
You can also use Pipenv and Poetry to manage dependencies,
but there are a caveats to keep in mind when using those tools.
For more information, see how to [manage Python dependencies](https://docs.platform.sh/languages/python/dependencies.md).
###### Web servers
The examples in this guide primarily use Gunicorn as a web server for Django apps.
Other servers such as Daphne and Uvicorn are equally supported.
See how to configure [Python web servers](https://docs.platform.sh/languages/python/server.md).
###### Sanitize data
By default, each preview environment automatically inherits all data from its parent environment.
So a developer working on a small feature has access to production data,
including personally identifiable information (PII).
This workflow isn't always desirable or even acceptable based on your compliance requirements.
For how to enforce compliance requirements for user data across environments,
see how to [sanitize databases](https://docs.platform.sh/development/sanitize-db.md).
[Back](https://docs.platform.sh/guides/django/deploy/deploy.md)
### Local development
A significant amount of work developing Django takes place locally rather than on an active Platform.sh environment.
You want to ensure that the process of local development is as close as possible to a deployed environment.
You can achieve this through various approaches.
Each of these examples:
- Creates a local development environment for a Django site.
- Syncs data from the active Platform.sh environment where team review takes place.
- Commits aspects of that local development method to the project so collaborators can replicate configuration to contribute.
If you're already using Docker Compose,
consult the Community guide on [using Docker Compose with Django and Platform.sh](https://support.platform.sh/hc/en-us/community/posts/16439578981138).
#### DDEV
[DDEV](https://ddev.readthedocs.io/en/stable/) is an open-source tool for local development environments.
It allows you to use Docker in your workflows while maintaining a GitOps workflow.
You get fully containerized environments to run everything locally
without having to install tools (including the Platform.sh CLI, PHP, and Composer) on your machine.
###### Before you begin
You need:
- A local copy of the repository for a [Django](https://docs.platform.sh../deploy.md) project running on Platform.sh.
To get one, run ``platform
get
``.
Alternatively, you can clone an integrated source repository and set the remote branch.
To do so, run ``platform
project:set-remote
``.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md)
- DDEV installed on your computer.
Make sure your computer meets the [system requirements for DDEV](https://ddev.readthedocs.io/en/stable/#system-requirements).
For the integration to run smoothly, you also need the following tools:
- `jq`
- `base64`
- `perl`
If you don't have these already installed, use your normal package manager.
To install DDEV, follow the [DDEV documentation for your operating system](https://ddev.readthedocs.io/en/stable/users/install/ddev-installation/).
This installs the self-contained `ddev` command-line interface (CLI).
For more information on `ddev`, run `ddev help`.
###### Assumptions
This example makes some assumptions, which you may need to adjust for your own circumstances.
It's assumed you want to run a built-in lightweight development server with `manage.py runserver`.
To match a production web server (such as Gunicorn or Daphne),
[modify those commands accordingly](https://docs.platform.sh../../../languages/python/server.md).
It's generally assumed that Platform.sh is the primary remote for the project.
If you use a source integration, the steps are identical in most cases.
When they differ, the alternative is noted.
###### Set up DDEV
1. Create a new environment off of production.
```bash
platform branch new-feature main
```
If you're using a [source integration](https://docs.platform.sh/integrations/source.md),
open a merge/pull request.
2. Add DDEV configuration to the project.
```bash
ddev config --auto
```
3. Add a Python alias package to the configuration.
```bash
ddev config --webimage-extra-packages python-is-python3
```
4. Add an API token.
To connect DDEV with your Platform.sh account, use a Platform.sh API token.
First [create an API token](https://docs.platform.sh/administration/cli/api-tokens.md#2-create-an-api-token) in the Console.
Then add the token to your DDEV configuration.
You can do so globally (easiest for most people):
```bash
ddev config global --web-environment-add=PLATFORMSH_CLI_TOKEN=
```
You can also add the token only to the project:
```bash
ddev config --web-environment-add=PLATFORMSH_CLI_TOKEN=
```
5. Connect DDEV to your project and the `new-feature` environment.
The best way to connect your local DDEV to your Platform.sh project is through the [Platform.sh DDEV add-on](https://github.com/ddev/ddev-platformsh).
To add it, run the following command:
```bash
ddev get ddev/ddev-platformsh
```
Answer the interactive prompts with your project ID and the name of the environment to pull data from.
With the add-on, you can now run `ddev platform ` from your computer without needing to install the Platform.sh CLI.
6. Update the DDEV PHP version.
Python support in DDEV and the Platform.sh integration is in active development.
At this time, the only officially supported runtime is PHP.
With a few changes, the generated configuration can be modified to run local Django environments.
A `.ddev` directory has been created in the repository containing DDEV configuration.
In the `.ddev/config.platformsh.yaml` file, update the `php_version` attribute to a supported version, like `8.2`.
```yaml {location=".ddev/config.platformsh.yaml"}
# Leaving the generated line as is results in an error.
# php_version: python:3.10
php_version: 8.2
```
7. Update the DDEV `post-start` hooks.
The generated configuration contains a `hooks.post-start` attribute that contains Django's `hooks.build` and `hooks.deploy`.
Add another item to the end of that array with the start command defined in `.platform.app.yaml`:
```yaml {}
hooks:
post-start:
...
# Platform.sh start command
- exec: python manage.py runserver 0.0.0.0:8000
```
.ddev/docker-compose.django.yaml
```yaml {}
hooks:
post-start:
...
# Platform.sh start command
- exec: pipenv run python manage.py runserver 0.0.0.0:8000
```
.ddev/docker-compose.django.yaml
```yaml {}
hooks:
post-start:
...
# Platform.sh start command
- exec: poetry run python manage.py runserver 0.0.0.0:8000
```
8. Create a custom Docker Compose file to define the port exposed for the container you're building, `web`:
```yaml {location=".ddev/docker-compose.django.yaml"}
version: "3.6"
services:
web:
expose:
- 8000
environment:
- HTTP_EXPOSE=80:8000
- HTTPS_EXPOSE=443:8000
healthcheck:
test: "true"
```
9. Create a custom `Dockerfile` to install Python into the container.
``` {location=".ddev/web-build/Dockerfile.python"}
RUN apt-get install -y python3.10 python3-pip
```
10. Update your allowed hosts to include the expected DDEV domain suffix:
```py {location="APP_NAME/settings.py"}
ALLOWED_HOSTS = [
'localhost',
'127.0.0.1',
'.platformsh.site',
'.ddev.site'
]
```
11. Update your database configuration to include environment variables provided by DDEV:
```py {location="APP_NAME/settings.py"}
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.environ.get('POSTGRES_NAME'),
'USER': os.environ.get('POSTGRES_USER'),
'PASSWORD': os.environ.get('POSTGRES_PASSWORD'),
'HOST': 'db',
'PORT': 5432,
}
}
```
This example assumes you have a PostgreSQL database with `db` as the relationship name.
If you have a different setup, adjust the values accordingly.
12. Start DDEV.
Build and start up Django for the first time.
```bash
ddev start
```
If you have another process running, you may get an error such as the following:
```bash
Failed to start django: Unable to listen on required ports, port 80 is already in use
```
If you do, either cancel the running process on port `80` or do both of the following:
- Edit `router_http_port` in `.ddev/config.yaml` to another port such as `8080`.
- Edit the `services.web.environment` variable `HTTP_EXPOSE` in `ddev/docker-compose.django.yaml` to `HTTP_EXPOSE=8080:8000`.
13. Pull data from the environment.
Exit the currently running process (`CTRL+C`)
and then run the following command to retrieve data from the current Platform.sh environment:
```bash
ddev pull platform
```
14. Restart DDEV
```bash
ddev restart
```
You now have a local development environment that's in sync with the `new-feature` environment on Platform.sh.
15. When you finish your work, shut down DDEV.
```bash
ddev stop
```
###### Next steps
You can now use your local environment to develop changes for review on Platform.sh environments.
The following examples show how you can take advantage of that.
####### Onboard collaborators
It's essential for every developer on your team to have a local development environment to work on.
Place the local configuration into a script to ensure everyone has this.
You can merge this change into production.
1. Create a new environment called `local-config`.
2. To set up a local environment for a new Platform.sh environment, create an executable script.
```bash
touch init-local.sh && chmod +x init-local.sh
```
3. Fill it with the following example, depending on your package manager:
```bash {}
#!/usr/bin/env bash
PROJECT=$1
ENVIRONMENT=$2
PARENT=$3
# Create the new environment
platform branch $ENVIRONMENT $PARENT
# Configure DDEV
ddev config --auto
ddev config --web-environment-add PLATFORM_PROJECT=$PROJECT
ddev config --web-environment-add PLATFORM_ENVIRONMENT=$ENVIRONMENT
ddev config --webimage-extra-packages python-is-python3
ddev get drud/ddev-platformsh
# Update .ddev/config.platformsh.yaml
# 1. hooks.post-start
printf " # Platform.sh start command\n - exec: |\n python manage.py runserver 0.0.0.0:8000" >> .ddev/config.platformsh.yaml
# 2. php_version
grep -v "php_version" .ddev/config.platformsh.yaml > tmpfile && mv tmpfile .ddev/config.platformsh.yaml
printf "\nphp_version: 8.0" >> .ddev/config.platformsh.yaml
# Create a docker-compose.django.yaml
printf "
version: \"3.6\"
services:
web:
expose:
- 8000
environment:
- HTTP_EXPOSE=80:8000
- HTTPS_EXPOSE=443:8000
healthcheck:
test: \"true\"
" > .ddev/docker-compose.django.yaml
# Create Dockerfile.python
printf "
RUN apt-get install -y python3.10 python3-pip
" > .ddev/web-build/Dockerfile.python
ddev start
ddev pull platform -y
ddev restart
```
init-local.sh
```bash {}
#!/usr/bin/env bash
PROJECT=$1
ENVIRONMENT=$2
PARENT=$3
# Create the new environment
platform branch $ENVIRONMENT $PARENT
# Configure DDEV
ddev config --auto
ddev config --web-environment-add PLATFORM_PROJECT=$PROJECT
ddev config --web-environment-add PLATFORM_ENVIRONMENT=$ENVIRONMENT
ddev config --webimage-extra-packages python-is-python3
ddev get drud/ddev-platformsh
# Update .ddev/config.platformsh.yaml
# 1. hooks.post-start
printf " # Platform.sh start command\n - exec: |\n pipenv run python manage.py runserver 0.0.0.0:8000" >> .ddev/config.platformsh.yaml
# 2. php_version
grep -v "php_version" .ddev/config.platformsh.yaml > tmpfile && mv tmpfile .ddev/config.platformsh.yaml
printf "\nphp_version: 8.0" >> .ddev/config.platformsh.yaml
# Create a docker-compose.django.yaml
printf "
version: \"3.6\"
services:
web:
expose:
- 8000
environment:
- HTTP_EXPOSE=80:8000
- HTTPS_EXPOSE=443:8000
healthcheck:
test: \"true\"
" > .ddev/docker-compose.django.yaml
# Create Dockerfile.python
printf "
RUN apt-get install -y python3.10 python3-pip
" > .ddev/web-build/Dockerfile.python
ddev start
ddev pull platform -y
ddev restart
```
init-local.sh
```bash {}
#!/usr/bin/env bash
PROJECT=$1
ENVIRONMENT=$2
PARENT=$3
# Create the new environment
platform branch $ENVIRONMENT $PARENT
# Configure DDEV
ddev config --auto
ddev config --web-environment-add PLATFORM_PROJECT=$PROJECT
ddev config --web-environment-add PLATFORM_ENVIRONMENT=$ENVIRONMENT
ddev config --webimage-extra-packages python-is-python3
ddev get drud/ddev-platformsh
# Update .ddev/config.platformsh.yaml
# 1. hooks.post-start
printf " # Platform.sh start command\n - exec: |\n poetry run python manage.py runserver 0.0.0.0:8000" >> .ddev/config.platformsh.yaml
# 2. php_version
grep -v "php_version" .ddev/config.platformsh.yaml > tmpfile && mv tmpfile .ddev/config.platformsh.yaml
printf "\nphp_version: 8.0" >> .ddev/config.platformsh.yaml
# Create a docker-compose.django.yaml
printf "
version: \"3.6\"
services:
web:
expose:
- 8000
environment:
- HTTP_EXPOSE=80:8000
- HTTPS_EXPOSE=443:8000
healthcheck:
test: \"true\"
" > .ddev/docker-compose.django.yaml
# Create Dockerfile.python
printf "
RUN apt-get install -y python3.10 python3-pip
" > .ddev/web-build/Dockerfile.python
ddev start
ddev pull platform -y
ddev restart
```
4. To commit and push the revisions, run the following command:
```bash
git add . && git commit -m "Add local configuration" && git push platform local-config
```
5. Merge the change into production.
Once the script is merged into production,
any user can set up their local environment by running the following commands:
```bash
platform
cd
./init-local.sh another-new-feature
```
####### Sanitize data
It's often a compliance requirement to ensure that only a minimal subset of developers within an organization
have access to production data during their work.
By default, your production data is automatically cloned into _every_ child environment.
You can customize your deployments to include a script that sanitizes the data within every preview environment.
1. Create a new environment called `sanitize-non-prod`.
2. Follow the example on how to [sanitize PostgreSQL with Django](https://docs.platform.sh../../../development/sanitize-db/postgresql.md).
This adds a sanitization script to your deploy hook that runs on all preview environments.
3. Commit and push the revisions by running the following command:
```bash
git add . && git commit -m "Add data sanitization" && git push platform sanitize-non-prod
```
4. Merge the change into production.
Once the script is merged into production, every preview environment created on Platform.sh
and all local environments contain sanitized data free of your users' personally identifiable information (PII).
#### Tethered local
**Note**:
This guide is an example for setting up a local development environment for Django.
The recommended tool for local development is DDEV.
See the [Django DDEV guide](https://docs.platform.sh/guides/django/local/ddev.md).
To test changes locally, you can connect your locally running Django server
to service containers on an active Platform.sh environment.
###### Before you begin
You need:
- A local copy of the repository for a [Django](https://docs.platform.sh../deploy.md) project running on Platform.sh.
To get one, run ``platform
get
``.
Alternatively, you can clone an integrated source repository and set the remote branch.
To do so, run ``platform
project:set-remote
``.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md)
###### Assumptions
This example makes some assumptions, which you may need to adjust for your own circumstances.
It's assumed you want to run a built-in lightweight development server with `manage.py runserver`.
To match a production web server (such as Gunicorn or Daphne),
[modify those commands accordingly](https://docs.platform.sh../../../languages/python/server.md).
It's generally assumed that Platform.sh is the primary remote for the project.
If you use a source integration, the steps are identical in most cases.
When they differ, the alternative is noted.
If you followed the [Django deployment guide](https://docs.platform.sh/guides/django/deploy.md),
you should have a Django configuration file with settings for [decoding variables](https://docs.platform.sh/guides/django/deploy/customize.md#decoding-variables)
and also [overrides for Platform.sh](https://docs.platform.sh/guides/django/deploy/customize.md#decoding-variables).
You can use these settings to set up a tethered connection to services running on a Platform.sh environment.
The settings are used to mock the conditions of the environment locally.
###### Create the tethered connection
1. Create a new environment based on production.
```bash
platform branch new-feature
```
If you're using a [source integration](https://docs.platform.sh/integrations/source.md),
open a merge/pull request.
1. To open an SSH tunnel to the new environment's services, run the following command:
```bash
platform tunnel:open
```
This command returns the addresses for SSH tunnels to all of your services.
1. Export the `PLATFORMSH_RELATIONSHIPS` environment variable with information from the open tunnel:
```bash
export PLATFORM_RELATIONSHIPS="$(platform tunnel:info --encode)"
```
1. To ensure your `settings.py` file acts as if in a Platform.sh environment,
mock two variables present in active environments:
```bash
export PLATFORM_APPLICATION_NAME=django && export PLATFORM_ENVIRONMENT=new-feature
```
1. To install dependencies, run the command for your package manager:
```bash {}
pipenv install
```
```bash {}
poetry install
```
1. Collect static assets.
```bash {}
pipenv run python manage.py collectstatic
```
```bash {}
poetry run python manage.py collectstatic
```
1. To start your local server, run the following command based on your package manager:
```bash {}
pipenv run python manage.py runserver
```
```bash {}
poetry run python manage.py runserver
```
1. When you've finished your work, close the tunnels to your services by running the following command:
```bash
platform tunnel:close --all -y
```
###### Next steps
You can now use your local environment to develop changes for review on Platform.sh environments.
The following examples show how you can take advantage of that.
####### Onboard collaborators
It's essential for every developer on your team to have a local development environment to work on.
Place the local configuration into a script to ensure everyone has this.
You can merge this change into production.
1. Create a new environment called `local-config`.
1. To set up a local environment for a new Platform.sh environment, create an executable script.
```bash
touch init-local.sh && chmod +x init-local.sh
```
1. Fill it with the following example, depending on your package manager:
```bash {}
#!/usr/bin/env bash
PROJECT=$1
ENVIRONMENT=$2
PARENT=$3
# Create the new environment
platform branch $ENVIRONMENT $PARENT
# Configure DDEV
ddev config --auto
ddev config --web-environment-add PLATFORM_PROJECT=$PROJECT
ddev config --web-environment-add PLATFORM_ENVIRONMENT=$ENVIRONMENT
ddev config --webimage-extra-packages python-is-python3
ddev get drud/ddev-platformsh
# Update .ddev/config.platformsh.yaml
# 1. hooks.post-start
printf " # Platform.sh start command\n - exec: |\n python manage.py runserver 0.0.0.0:8000" >> .ddev/config.platformsh.yaml
# 2. php_version
grep -v "php_version" .ddev/config.platformsh.yaml > tmpfile && mv tmpfile .ddev/config.platformsh.yaml
printf "\nphp_version: 8.0" >> .ddev/config.platformsh.yaml
# Create a docker-compose.django.yaml
printf "
version: \"3.6\"
services:
web:
expose:
- 8000
environment:
- HTTP_EXPOSE=80:8000
- HTTPS_EXPOSE=443:8000
healthcheck:
test: \"true\"
" > .ddev/docker-compose.django.yaml
# Create Dockerfile.python
printf "
RUN apt-get install -y python3.10 python3-pip
" > .ddev/web-build/Dockerfile.python
ddev start
ddev pull platform -y
ddev restart
```
init-local.sh
```bash {}
#!/usr/bin/env bash
PROJECT=$1
ENVIRONMENT=$2
PARENT=$3
# Create the new environment
platform branch $ENVIRONMENT $PARENT
# Configure DDEV
ddev config --auto
ddev config --web-environment-add PLATFORM_PROJECT=$PROJECT
ddev config --web-environment-add PLATFORM_ENVIRONMENT=$ENVIRONMENT
ddev config --webimage-extra-packages python-is-python3
ddev get drud/ddev-platformsh
# Update .ddev/config.platformsh.yaml
# 1. hooks.post-start
printf " # Platform.sh start command\n - exec: |\n pipenv run python manage.py runserver 0.0.0.0:8000" >> .ddev/config.platformsh.yaml
# 2. php_version
grep -v "php_version" .ddev/config.platformsh.yaml > tmpfile && mv tmpfile .ddev/config.platformsh.yaml
printf "\nphp_version: 8.0" >> .ddev/config.platformsh.yaml
# Create a docker-compose.django.yaml
printf "
version: \"3.6\"
services:
web:
expose:
- 8000
environment:
- HTTP_EXPOSE=80:8000
- HTTPS_EXPOSE=443:8000
healthcheck:
test: \"true\"
" > .ddev/docker-compose.django.yaml
# Create Dockerfile.python
printf "
RUN apt-get install -y python3.10 python3-pip
" > .ddev/web-build/Dockerfile.python
ddev start
ddev pull platform -y
ddev restart
```
init-local.sh
```bash {}
#!/usr/bin/env bash
PROJECT=$1
ENVIRONMENT=$2
PARENT=$3
# Create the new environment
platform branch $ENVIRONMENT $PARENT
# Configure DDEV
ddev config --auto
ddev config --web-environment-add PLATFORM_PROJECT=$PROJECT
ddev config --web-environment-add PLATFORM_ENVIRONMENT=$ENVIRONMENT
ddev config --webimage-extra-packages python-is-python3
ddev get drud/ddev-platformsh
# Update .ddev/config.platformsh.yaml
# 1. hooks.post-start
printf " # Platform.sh start command\n - exec: |\n poetry run python manage.py runserver 0.0.0.0:8000" >> .ddev/config.platformsh.yaml
# 2. php_version
grep -v "php_version" .ddev/config.platformsh.yaml > tmpfile && mv tmpfile .ddev/config.platformsh.yaml
printf "\nphp_version: 8.0" >> .ddev/config.platformsh.yaml
# Create a docker-compose.django.yaml
printf "
version: \"3.6\"
services:
web:
expose:
- 8000
environment:
- HTTP_EXPOSE=80:8000
- HTTPS_EXPOSE=443:8000
healthcheck:
test: \"true\"
" > .ddev/docker-compose.django.yaml
# Create Dockerfile.python
printf "
RUN apt-get install -y python3.10 python3-pip
" > .ddev/web-build/Dockerfile.python
ddev start
ddev pull platform -y
ddev restart
```
1. To commit and push the revisions, run the following command:
```bash
git add . && git commit -m "Add local configuration" && git push platform local-config
```
1. Merge the change into production.
Once the script is merged into production,
any user can set up their local environment by running the following commands:
```bash
platform
cd
./init-local.sh another-new-feature
```
####### Sanitize data
It's often a compliance requirement to ensure that only a minimal subset of developers within an organization
have access to production data during their work.
By default, your production data is automatically cloned into _every_ child environment.
You can customize your deployments to include a script that sanitizes the data within every preview environment.
1. Create a new environment called `sanitize-non-prod`.
2. Follow the example on how to [sanitize PostgreSQL with Django](https://docs.platform.sh../../../development/sanitize-db/postgresql.md).
This adds a sanitization script to your deploy hook that runs on all preview environments.
3. Commit and push the revisions by running the following command:
```bash
git add . && git commit -m "Add data sanitization" && git push platform sanitize-non-prod
```
4. Merge the change into production.
Once the script is merged into production, every preview environment created on Platform.sh
and all local environments contain sanitized data free of your users' personally identifiable information (PII).
### Deploy Drupal on Platform.sh
Drupal is a flexible and extensible PHP-based CMS framework. To deploy Drupal on Platform.sh, the recommended way is to use Composer, the PHP package management suite.
This guide assumes you are using the well-supported Composer flavor of Drupal.
To get Drupal running on Platform.sh, you have two potential starting places:
- You already have a [Composer-flavored Drupal](https://github.com/drupal/recommended-project/) site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic [Composer-flavored Drupal](https://github.com/drupal/recommended-project/) site.
See an example for doing this under initializing a project.
- Use a ready-made [Drupal template](https://github.com/platformsh-templates/drupal11).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Drupal template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
If you don’t have code, create a new Drupal project from scratch.
The following commands create a brand new Drupal project using Composer.
```bash {}
composer create-project drupal/core-recommended
cd
git init
git add . && git commit -m "Init Drupal from upstream."
```
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/drupal/deploy/configure.md)
#### Configure Drupal for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml && touch .platform.app.yaml
```
Now that you've added these files to your project,
configure each one for Drupal in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Drupal requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
```yaml {location=".platform.app.yaml"}
# This file describes an application. You can have multiple applications
# in the same project.
#
# See https://docs.platform.sh/configuration/app.html
# The name of this app. Must be unique within a project.
name: 'drupal'
# The runtime the application uses.
type: 'php:8.1'
dependencies:
php:
composer/composer: '^2.1'
runtime:
# Enable the redis extension so Drupal can communicate with the Redis cache.
extensions:
- redis
- sodium
- apcu
- blackfire
# The relationships of the application with services or other applications.
#
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
relationships:
database: 'db:mysql'
redis: 'cache:redis'
# The size of the persistent disk of the application (in MB).
disk: 2048
# The 'mounts' describe writable, persistent filesystem mounts in the application.
mounts:
# The default Drupal files directory.
'/web/sites/default/files':
source: local
source_path: 'files'
# Drupal gets its own dedicated tmp directory. The settings.platformsh.php
# file will automatically configure Drupal to use this directory.
'/tmp':
source: local
source_path: 'tmp'
# Private file uploads are stored outside the web root. The settings.platformsh.php
# file will automatically configure Drupal to use this directory.
'/private':
source: local
source_path: 'private'
# Drush needs a scratch space for its own caches.
'/.drush':
source: local
source_path: 'drush'
# Drush will try to save backups to this directory, so it must be
# writeable even though you will almost never need to use it.
'/drush-backups':
source: local
source_path: 'drush-backups'
# Drupal Console will try to save backups to this directory, so it must be
# writeable even though you will almost never need to use it.
'/.console':
source: local
source_path: 'console'
# Configuration of the build of this application.
build:
flavor: composer
# The hooks executed at various points in the lifecycle of the application.
hooks:
# The build hook runs after Composer to finish preparing up your code.
# No services are available but the disk is writeable.
build: |
set -e
# The deploy hook runs after your application has been deployed and started.
# Code cannot be modified at this point but the database is available.
# The site is not accepting requests while this script runs so keep it
# fast.
deploy: |
set -e
php ./drush/platformsh_generate_drush_yml.php
# if drupal is installed, will call the following drush commands:
# - `cache-rebuild`
# - `updatedb`
# - and if config files are present, `config-import`
cd web
bash $PLATFORM_APP_DIR/drush/platformsh_deploy_drupal.sh
# The configuration of app when it is exposed to the web.
web:
locations:
# All requests not otherwise specified follow these rules.
'/':
# The folder from which to serve static assets, for this location.
#
# This is a filesystem path, relative to the application root.
root: 'web'
# How long to allow static assets from this location to be cached.
#
# Can be a time in seconds, or -1 for no caching. Times can be
# suffixed with "s" (seconds), "m" (minutes), "h" (hours), "d"
# (days), "w" (weeks), "M" (months, as 30 days) or "y" (years, as
# 365 days).
expires: 5m
# Redirect any incoming request to Drupal's front controller.
passthru: '/index.php'
# Deny access to all static files, except those specifically allowed below.
allow: false
# Rules for specific URI patterns.
rules:
# Allow access to common static files.
'\.(avif|webp|jpe?g|png|gif|svgz?|css|js|map|ico|bmp|eot|woff2?|otf|ttf)$':
allow: true
'^/robots\.txt$':
allow: true
'^/sitemap\.xml$':
allow: true
# Deny direct access to configuration files.
'^/sites/sites\.php$':
scripts: false
'^/sites/[^/]+/settings.*?\.php$':
scripts: false
# The files directory has its own special configuration rules.
'/sites/default/files':
# Allow access to all files in the public files directory.
allow: true
expires: 5m
passthru: '/index.php'
root: 'web/sites/default/files'
# Do not execute PHP scripts from the writeable mount.
scripts: false
rules:
# Provide a longer TTL (2 weeks) for aggregated CSS and JS files.
'^/sites/default/files/(css|js)':
expires: 2w
crons:
# Run Drupal's cron tasks every 19 minutes.
drupal:
spec: '*/19 * * * *'
commands:
start: 'cd web ; drush core-cron'
source:
operations:
auto-update:
command: |
curl -fsS https://raw.githubusercontent.com/platformsh/source-operations/main/setup.sh | { bash /dev/fd/3 sop-autoupdate; } 3<&0
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
We recommend the latest [MariaDB](https://docs.platform.sh/add-services/mysql.md) version for Drupal,
although you can also use Oracle MySQL or [PostgreSQL](https://docs.platform.sh/add-services/postgresql.md).
For Drupal caching, we strongly recommend [Redis](https://docs.platform.sh/add-services/redis.md).
Drupal’s cache can be very aggressive,
and keeping that data out of the database helps with both performance and disk usage.
See an example of Redis for caching in our [Drupal template](https://github.com/platformsh-templates/drupal10).
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure Drupal to use those services once they're enabled.
Each service entry has a name (`db` and `cache` in the example)
and a `type` that specifies the service and version to use.
Services that store persistent data have a `disk` key, to specify the amount of storage.
```yaml {location=".platform/services.yaml"}
# The services of the project.
#
# Each service listed will be deployed
# to power your Platform.sh project.
db:
type: mariadb:10.11
disk: 2048
cache:
type: redis:7.2
```
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
Generally, you want the user session cookie, which is included in the example for Drupal.
You may need to add other cookies depending on what additional modules you have installed.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Drupal app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://{default}/":
type: upstream
upstream: "drupal:http"
cache:
enabled: true
# Base the cache on the session cookie and custom Drupal cookies. Ignore all other cookies.
cookies: ['/^SS?ESS/', '/^Drupal.visitor/']
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
#### Customize Drupal for Platform.sh
Now that your code contains all of the configuration to deploy on Platform.sh,
it's time to make your Drupal site itself ready to run on a Platform.sh environment.
There are a number of additional steps that are either required or recommended, depending on how well you want to optimize your site.
###### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
The following examples use it, so install it through Composer if you haven't already.
```bash
composer require platformsh/config-reader
```
###### `settings.php`
`settings.php` is the main Drupal environment-configuration file.
In a stock Drupal installation it contains the database credentials, various other settings, and an enormous amount of comments.
In the Drupal template, the [`settings.php`](https://github.com/platformsh-templates/drupal10/blob/master/web/sites/default/settings.php) file
is mostly replaced with a stub that contains only the most basic configuration
and then includes a `settings.platformsh.php` and `settings.local.php` file, if they exist.
The latter is a common Drupal pattern, and the `settings.local.php` file should never be committed to Git.
It contains configuration that's specific to your local development environment,
such as a local development database.
The `settings.platformsh.php` file contains glue code that configures Drupal
based on the information available in Platform.sh's environment variables.
That includes the database credentials, Redis caching, and file system paths.
The file itself is a bit long, but reasonably self-explanatory.
```php
hasRelationship('database')) {
$creds = $platformsh->credentials('database');
$databases['default']['default'] = [
'driver' => $creds['scheme'],
'database' => $creds['path'],
'username' => $creds['username'],
'password' => $creds['password'],
'host' => $creds['host'],
'port' => $creds['port'],
'pdo' => [PDO::MYSQL_ATTR_COMPRESS => !empty($creds['query']['compression'])],
'init_commands' => [
'isolation_level' => 'SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED',
],
];
}
// Enable verbose error messages on development branches, but not on the production branch.
// You may add more debug-centric settings here if desired to have them automatically enable
// on development but not production.
if (isset($platformsh->branch)) {
// Production type environment.
if ($platformsh->onProduction() || $platformsh->onDedicated()) {
$config['system.logging']['error_level'] = 'hide';
} // Development type environment.
else {
$config['system.logging']['error_level'] = 'verbose';
}
}
// Enable Redis caching.
if ($platformsh->hasRelationship('redis') && !InstallerKernel::installationAttempted() && extension_loaded('redis') && class_exists('Drupal\redis\ClientFactory')) {
$redis = $platformsh->credentials('redis');
// Set Redis as the default backend for any cache bin not otherwise specified.
$settings['cache']['default'] = 'cache.backend.redis';
$settings['redis.connection']['host'] = $redis['host'];
$settings['redis.connection']['port'] = $redis['port'];
// Apply changes to the container configuration to better leverage Redis.
// This includes using Redis for the lock and flood control systems, as well
// as the cache tag checksum. Alternatively, copy the contents of that file
// to your project-specific services.yml file, modify as appropriate, and
// remove this line.
$settings['container_yamls'][] = 'modules/contrib/redis/example.services.yml';
// Allow the services to work before the Redis module itself is enabled.
$settings['container_yamls'][] = 'modules/contrib/redis/redis.services.yml';
// Manually add the classloader path, this is required for the container cache bin definition below
// and allows to use it without the redis module being enabled.
$class_loader->addPsr4('Drupal\\redis\\', 'modules/contrib/redis/src');
// Use redis for container cache.
// The container cache is used to load the container definition itself, and
// thus any configuration stored in the container itself is not available
// yet. These lines force the container cache to use Redis rather than the
// default SQL cache.
$settings['bootstrap_container_definition'] = [
'parameters' => [],
'services' => [
'redis.factory' => [
'class' => 'Drupal\redis\ClientFactory',
],
'cache.backend.redis' => [
'class' => 'Drupal\redis\Cache\CacheBackendFactory',
'arguments' => ['@redis.factory', '@cache_tags_provider.container', '@serialization.phpserialize'],
],
'cache.container' => [
'class' => '\Drupal\redis\Cache\PhpRedis',
'factory' => ['@cache.backend.redis', 'get'],
'arguments' => ['container'],
],
'cache_tags_provider.container' => [
'class' => 'Drupal\redis\Cache\RedisCacheTagsChecksum',
'arguments' => ['@redis.factory'],
],
'serialization.phpserialize' => [
'class' => 'Drupal\Component\Serialization\PhpSerialize',
],
],
];
}
if ($platformsh->inRuntime()) {
// Configure private and temporary file paths.
if (!isset($settings['file_private_path'])) {
$settings['file_private_path'] = $platformsh->appDir . '/private';
}
if (!isset($settings['file_temp_path'])) {
$settings['file_temp_path'] = $platformsh->appDir . '/tmp';
}
// Configure the default PhpStorage and Twig template cache directories.
if (!isset($settings['php_storage']['default'])) {
$settings['php_storage']['default']['directory'] = $settings['file_private_path'];
}
if (!isset($settings['php_storage']['twig'])) {
$settings['php_storage']['twig']['directory'] = $settings['file_private_path'];
}
// Set the project-specific entropy value, used for generating one-time
// keys and such.
$settings['hash_salt'] = empty($settings['hash_salt']) ? $platformsh->projectEntropy : $settings['hash_salt'];
// Set the deployment identifier, which is used by some Drupal cache systems.
$settings['deployment_identifier'] = $settings['deployment_identifier'] ?? $platformsh->treeId;
}
// The 'trusted_hosts_pattern' setting allows an admin to restrict the Host header values
// that are considered trusted. If an attacker sends a request with a custom-crafted Host
// header then it can be an injection vector, depending on how the Host header is used.
// However, Platform.sh already replaces the Host header with the route that was used to reach
// Platform.sh, so it is guaranteed to be safe. The following line explicitly allows all
// Host headers, as the only possible Host header is already guaranteed safe.
$settings['trusted_host_patterns'] = ['.*'];
// Import variables prefixed with 'drupalsettings:' into $settings
// and 'drupalconfig:' into $config.
foreach ($platformsh->variables() as $name => $value) {
$parts = explode(':', $name);
list($prefix, $key) = array_pad($parts, 3, null);
switch ($prefix) {
// Variables that begin with `drupalsettings` or `drupal` get mapped
// to the $settings array verbatim, even if the value is an array.
// For example, a variable named drupalsettings:example-setting' with
// value 'foo' becomes $settings['example-setting'] = 'foo';
case 'drupalsettings':
case 'drupal':
$settings[$key] = $value;
break;
// Variables that begin with `drupalconfig` get mapped to the $config
// array. Deeply nested variable names, with colon delimiters,
// get mapped to deeply nested array elements. Array values
// get added to the end just like a scalar. Variables without
// both a config object name and property are skipped.
// Example: Variable `drupalconfig:conf_file:prop` with value `foo` becomes
// $config['conf_file']['prop'] = 'foo';
// Example: Variable `drupalconfig:conf_file:prop:subprop` with value `foo` becomes
// $config['conf_file']['prop']['subprop'] = 'foo';
// Example: Variable `drupalconfig:conf_file:prop:subprop` with value ['foo' => 'bar'] becomes
// $config['conf_file']['prop']['subprop']['foo'] = 'bar';
// Example: Variable `drupalconfig:prop` is ignored.
case 'drupalconfig':
if (count($parts) > 2) {
$temp = &$config[$key];
foreach (array_slice($parts, 2) as $n) {
$prev = &$temp;
$temp = &$temp[$n];
}
$prev[$n] = $value;
}
break;
}
}
```
If you add additional services to your application, such as Solr, Elasticsearch, or RabbitMQ,
you would add configuration for those services to the `settings.platformsh.php` file as well.
###### `.environment`
Platform.sh runs `source .environment` in the [app root](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#root-directory)
when a project starts, before cron commands are run, and when you log into an environment over SSH.
That gives you a place to do extra environment variable setup before the app runs,
including modifying the system `$PATH` and other shell level customizations.
The Drupal template includes a small [`.environment` file](https://github.com/platformsh-templates/drupal10/blob/master/.environment).
This modifies the `$PATH` to include the `vendor/bin` directory,
where command line tools like Drush are stored.
You need the file or one like it if you plan to run `drush` as a command,
such as in a cron task like the one in the [app configuration from the previous step](https://docs.platform.sh/guides/drupal/deploy/configure.md#configure-apps-in-platformappyaml).
If you don't include the file, you get a [command not found error](https://docs.platform.sh/development/troubleshoot.md#command-not-found).
```text {location=".environment"}
# Allow executable app dependencies from Composer to be run from the path.
if [ -n "$PLATFORM_APP_DIR" -a -f "$PLATFORM_APP_DIR"/composer.json ] ; then
bin=$(composer config bin-dir --working-dir="$PLATFORM_APP_DIR" --no-interaction 2>/dev/null)
export PATH="${PLATFORM_APP_DIR}/${bin:-vendor/bin}:${PATH}"
fi
```
###### Drush configuration
Drush requires a YAML file that declares what its URL is.
That value varies depending on the branch you're on, so it can't be included in a static file.
Instead, the `drush` directory includes a [short script](https://github.com/platformsh-templates/drupal10/blob/master/drush/platformsh_generate_drush_yml.php)
that generates that file on each deploy, writing it to `.drush/drush.yml`.
That allows Drush to run successfully on Platform.sh, such as to run cron tasks.
The script contents aren't especially interesting.
For the most part, you can download it from the template,
place it in a `drush` directory in your project so they can be called from the deploy hook, and then forget about it.
#### Deploy Drupal
###### Deployment
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Post-install (new site)
If you are creating a new site, visiting the site in your browser will trigger the Drupal installer.
Run through it as normal, but note that you will not be asked for the database credentials.
The `settings.platformsh.php` file added earlier automatically provides the database credentials
and the installer is smart enough to not ask for them again.
Once the installer is complete you are presented with your new site.
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Drupal has a number of database tables that are useless when migrating
and you’re better off excluding their data.
- If you’re using a database cache backend then you can and should exclude all ``cache_*`` table data.
On Platform.sh we recommend using Redis anyway,
and the template described on the previous pages uses Redis automatically.
- The ``sessions`` table’s data can also be excluded.
While you can trim the data out of these tables post-migration,
that’s wasteful of both time and disk space, so it’s better to exclude that data to begin with.
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your user files to your local `files/user` directory and your public files to `files/public`
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount src/main/resources/files/user --source ./files/user
platform mount:upload --mount src/main/resources/files/public --source ./files/public
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
Go forth and Deploy (even on Friday)!
#### Additional resources
###### Adding modules and themes
3rd party modules and themes can be installed and managed using Composer.
All packages on Drupal.org are registered with Drupal's own Packagist clone.
It should be included in the `composer.json` that comes with Drupal,
but in case it isn't you can add the following block to the file:
```json
"repositories": [
{
"type": "composer",
"url": "https://packages.drupal.org/8"
}
]
```
(Drupal 8 and 9 share the same package repository.)
Once that's there, you can install any module or theme with the following command:
```bash
composer require drupal/devel
```
Replace `devel` with the name of the module or theme you're installing.
Do *not* commit the `web/modules/contrib` directory to Git.
The build process re-downloads the correct version for you based on the `composer.json` and `composer.lock` files, which should be committed to Git.
###### Custom modules and themes
Site-specific custom modules and themes can be written directly in the `web/modules/custom` and `web/themes/custom` directories.
They should be committed to Git as normal.
###### Updating Drupal core and modules
Drupal is fully managed via Composer, which means so are updates to Drupal core itself.
Run `composer update` periodically to get new versions of both Drupal core
and any modules or themes you have installed via Composer.
Commit the resulting changes to your `composer.lock` file and push again.
The [Composer documentation](https://getcomposer.org/doc/) has more information on options to update individual modules or perform other tasks.
Note that updating modules or core through the Drupal UI isn't possible, as the file system is read-only.
All updates should be done through composer to update the lock file, and then pushed to Git.
###### Use Drush aliases
####### Create Drush aliases
[Drush site aliases](https://www.drush.org/latest/site-aliases/) help you manage your development websites.
The Platform.sh CLI can generate Drush aliases for you automatically
when you clone a project using the ``platform get `` command.
To see the aliases that are created, run the following command:
```bash
platform drush-aliases
```
You get output similar to the following:
```bash
Aliases for My Site (tqmd2kvitnoly):
@my-site._local
@my-site.main
@my-site.staging
@my-site.sprint1
```
####### Recreating Drush aliases
To recreate existing aliases or to create a new alias after pushing a new branch via git, run:
```bash
platform drush-aliases -r
```
[Back](https://docs.platform.sh/guides/drupal/deploy/deploy.md)
### Using Elasticsearch with Drupal
##### Requirements
###### Add an Elasticsearch service
####### 1. Configure the service
To define the service, use the `elasticsearch`:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: elasticsearch:
disk: 256
```
If you’re using a [premium version](add-services/elasticsearch.md#supported-versions), use the `elasticsearch-enterprise` type instead.
Note that changing the name of the service replaces it with a brand new service and all existing data is lost.
Back up your data before changing the service.
####### 2. Define the relationship
To define the relationship, use the following configuration:
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services
and matches in both the application and services configuration.
The example above leverages [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
That is, it uses default endpoints behind-the-scenes, providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships)
(the network address a service is accessible from) that is identical to the name of that service.
Depending on your needs, instead of default endpoint configuration,
you can use [explicit endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](https://docs.platform.sh/add-services/elasticsearch.md#2-define-the-relationship) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: elasticsearch
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#2-define-the-relationship) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
###### Example configuration
####### [Service definition](https://docs.platform.sh/add-services.md)
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
elasticsearch:
type: elasticsearch:8.5
disk: 256
```
If you're using a [premium version](add-services/elasticsearch.md#supported-versions),
use the `elasticsearch-enterprise` type in the service definition.
####### [App configuration](https://docs.platform.sh/create-apps.md)
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
elasticsearch:
```
.platform.app.yaml
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service: elasticsearch
endpoint: elasticsearch
```
###### Add the Drupal modules
You need to add the [Search API](https://www.drupal.org/project/search_api) and [Elasticsearch Connector](https://www.drupal.org/project/elasticsearch_connector) modules to your project. If you are using composer, the easiest way to add them is to run:
```bash
composer require drupal/search_api drupal/elasticsearch_connector
```
And then commit the changes to `composer.json` and `composer.lock`.
##### Configuration
Because Drupal defines connection information via the Configuration Management system, you need to first define an Elasticsearch "Cluster" at `admin/config/search/elasticsearch-connector`.
Note the "machine name" the server is given.
Then, paste the following code snippet into your `settings.platformsh.php` file.
**Note**:
If you do not already have the [Config Reader library](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app) installed and referenced at the top of the file, you need to install it with ``composer require platformsh/config-reader`` and then add the following code before the block below:
```php {}
inRuntime()) {
return;
}
```
- Edit the value of `$relationship_name` if you are using a different relationship.
- Edit the value of `$es_server_name` to match the machine name of your cluster in Drupal.
```php
hasRelationship($relationship_name)) {
$platformsh->registerFormatter('drupal-elastic', function($creds) {
return sprintf('http://%s:%s', $creds['host'], $creds['port']);
});
// Set the connector configuration to the appropriate value, as defined by the formatter above.
$config['elasticsearch_connector.cluster.' . $es_cluster_name]['url'] = $platformsh->formattedCredentials($relationship_name, 'drupal-elastic');
}
```
Commit that code and push.
The specified cluster now always points to the Elasticsearch service.
Then configure Search API as normal.
### Using Memcached with Drupal
Platform.sh recommends using Redis for caching with Drupal over Memcached,
as Redis offers better performance when dealing with larger values as Drupal tends to produce.
But Memcached is also available if desired and is fully supported.
##### Requirements
###### Add a Memcached service
###### 1. Configure the service
To define the service, use the `memcached`:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: memcached:
disk: 256
```
Note that changing the name of the service replaces it with a brand new service and all existing data is lost.
Back up your data before changing the service.
###### 2. Define the relationship
To define the relationship, use the following configuration:
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services
and matches in both the application and services configuration.
The example above leverages [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
That is, it uses default endpoints behind-the-scenes, providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships)
(the network address a service is accessible from) that is identical to the name of that service.
Depending on your needs, instead of default endpoint configuration,
you can use [explicit endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has access to the service via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: memcached
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#app-configuration) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
For PHP, enable the [extension](https://docs.platform.sh/languages/php/extensions.md) for the service:
```yaml {location=".platform.app.yaml"}
# PHP extensions.
runtime:
extensions:
- memcached
```
###### Example configuration
###### [Service definition](https://docs.platform.sh/add-services.md)
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
memcached:
type: memcached:1.6
```
####### App configuration
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
memcached:
```
.platform.app.yaml
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
memcached:
service: memcached
endpoint: memcached
```
###### Add the Drupal module
You need to add the [Memcache](https://www.drupal.org/project/memcache) module to your project.
If you're using Composer to manage your Drupal site (which is recommended), run:
```bash
composer require drupal/memcache
```
Then commit the resulting changes to your `composer.json` and `composer.lock` files.
**Note**:
You need to commit and deploy your code before continuing, then enable the module.
The Memcache module must be enabled before it’s configured in the ``settings.platformsh.php`` file.
##### Configuration
The Drupal Memcache module must be configured via `settings.platformsh.php`.
Place the following at the end of `settings.platformsh.php`.
Note the inline comments, as you may wish to customize it further.
Also review the `README.txt` file that comes with the Memcache module,
as it has a more information on possible configuration options.
For instance, you may want to consider using Memcache for locking as well as configuring cache stampede protection.
The example below is intended as a "most common case" and has been tested with version `8.x-2.3` of the Memcache module.
**Note**:
If you don’t already have the [Config Reader library](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app) installed and referenced at the top of the file,
you need to install it with ``composer require platformsh/config-reader`` and then add the following code before the block below:
```php {}
inRuntime()) {
return;
}
```
```php
hasRelationship($relationship_name) && extension_loaded('memcached')) {
$platformsh->registerFormatter('drupal-memcached', function($creds) {
return sprintf("%s:%d", $creds['host'], $creds['port']);
});
// This is the line that tells Drupal to use Memcached as a backend.
// Comment out just this line if you need to disable it for some reason and
// fall back to the default database cache.
$settings['cache']['default'] = 'cache.backend.memcache';
$host = $platformsh->formattedCredentials($relationship_name, 'drupal-memcached');
$settings['memcache']['servers'][$host] = 'default';
// By default Drupal starts the cache_container on the database. The following
// code overrides that.
// Make sure that the $class_load->addPsr4 is pointing to the right location of
// the Memcache module. The value below should be correct if Memcache was installed
// using Drupal Composer.
$memcache_exists = class_exists('Memcache', FALSE);
$memcached_exists = class_exists('Memcached', FALSE);
if ($memcache_exists || $memcached_exists) {
$class_loader->addPsr4('Drupal\\memcache\\', 'modules/contrib/memcache/src');
// If using a multisite configuration, adapt this line to include a site-unique
// value.
$settings['memcache']['key_prefix'] = $platformsh->environment;
// Define custom bootstrap container definition to use Memcache for cache.container.
$settings['bootstrap_container_definition'] = [
'parameters' => [],
'services' => [
'database' => [
'class' => 'Drupal\Core\Database\Connection',
'factory' => 'Drupal\Core\Database\Database::getConnection',
'arguments' => ['default'],
],
'settings' => [
'class' => 'Drupal\Core\Site\Settings',
'factory' => 'Drupal\Core\Site\Settings::getInstance',
],
'memcache.settings' => [
'class' => 'Drupal\memcache\MemcacheSettings',
'arguments' => ['@settings'],
],
'memcache.factory' => [
'class' => 'Drupal\memcache\Driver\MemcacheDriverFactory',
'arguments' => ['@memcache.settings'],
],
'memcache.timestamp.invalidator.bin' => [
'class' => 'Drupal\memcache\Invalidator\MemcacheTimestampInvalidator',
# Adjust tolerance factor as appropriate when not running memcache on localhost.
'arguments' => ['@memcache.factory', 'memcache_bin_timestamps', 0.001],
],
'memcache.backend.cache.container' => [
'class' => 'Drupal\memcache\DrupalMemcacheInterface',
'factory' => ['@memcache.factory', 'get'],
'arguments' => ['container'],
],
'lock.container' => [
'class' => 'Drupal\memcache\Lock\MemcacheLockBackend',
'arguments' => ['container', '@memcache.backend.cache.container'],
],
'cache_tags_provider.container' => [
'class' => 'Drupal\Core\Cache\DatabaseCacheTagsChecksum',
'arguments' => ['@database'],
],
'cache.container' => [
'class' => 'Drupal\memcache\MemcacheBackend',
'arguments' => ['container', '@memcache.backend.cache.container','@cache_tags_provider.container','@memcache.timestamp.invalidator.bin'],
],
],
];
}
}
```
### Multiple Drupal sites in a single Project
Platform.sh supports running [multiple applications](https://docs.platform.sh/learn/bestpractices/oneormany.md) in the same project, and these can be two or more Drupal sites.
But they would be separate Drupal instances: they have their assets separate and live their lives apart, and it would be much better for them not to share the same database (though they could).
##### Multisite Drupal
Platform.sh actively discourages running Drupal in "multisite" mode. Doing so eliminates many of the advantages Platform.sh offers, such as isolation and safe testing.
Additionally, because of the dynamic nature of the domain names that are created for the different environments, the multisite configuration would be complex and fragile.
We recommend running separate projects for separate Drupal sites, or using one of the various "single instance" options available such as [Domain Access](https://www.drupal.org/project/domain), [Organic Groups](https://www.drupal.org/project/og), or [Workbench Access](https://www.drupal.org/project/workbench_access).
The only reason to use multisite Drupal would be to manage a series of nearly identical sites with separate databases.
For that case we have built a [template repository](https://github.com/platformsh-templates/drupal9-multisite) that uses a unified lookup key for a subdomain, database name, and file paths.
Note that it will likely require modification for your specific setup and some configurations may require a different approach.
In particular, this example:
* Defines two MySQL databases.
* Uses a modified `settings.platformsh.php` that accepts a key variable from `settings.php` to specify which database and file system paths to use.
* Extracts the `sites` directory to use from the domain.
### Using Redis with Drupal
Redis is a fast open-source in-memory database and cache, useful for application-level caching. For more information on this service, see the [dedicated Redis page](https://docs.platform.sh/add-services/redis.md) or the [official Redis documentation](https://redis.io/docs/).
Follow the instructions on this page to do one of the following:
- Add and configure Redis for Drupal if you have deployed Drupal manually.
- Fine-tune your existing configuration if you have deployed Drupal using a [Platform.sh template](https://docs.platform.sh/development/templates.md).
##### Before you begin
You need:
- A [Drupal version deployed on Platform.sh](https://docs.platform.sh/guides/drupal/deploy.md)
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli/)
- [Composer](https://getcomposer.org/)
- The [Config Reader library](https://docs.platform.sh/guides/drupal/deploy/customize.md#install-the-config-reader)
You also need a `settings.platformsh.php` file from which you can [manage the configuration of the Redis service](https://docs.platform.sh/guides/drupal/deploy/customize.md#settingsphp).
If you installed Drupal with a template, this file is already present in your project.
**Note**:
By default, Redis is an ephemeral service.
This means that the Redis storage isn’t persistent
and that data can be lost when a container is moved, shut down
or when the service hits its memory limit.
To solve this, Platform.sh recommends that you change the [service type](https://docs.platform.sh/add-services/redis.md#service-types)
to [persistent Redis](https://docs.platform.sh/add-services/redis.md#persistent-redis) (``redis-persistent``).
##### Add a Redis service
###### 1. Configure the service
To define the service, use the `redis-persistent` endpoint:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: redis-persistent:
disk: 256
```
Note that changing the name of the service replaces it with a brand new service and all existing data is lost.
Back up your data before changing the service.
###### 2. Define the relationship
To define the relationship, use the `redis` endpoint :
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services and matches in both the application and services configuration.
The example above leverages [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships. That is, it uses default endpoints behind-the-scenes, providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) (the network address a service is accessible from) that is identical to the name of that service.
Depending on your needs, instead of default endpoint configuration, you can use [explicit endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has access to the service via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: redis
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#2-define-the-relationship) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
For PHP, enable the [extension](https://docs.platform.sh/languages/php/extensions.md) for the service:
```yaml {location=".platform.app.yaml"}
# PHP extensions.
runtime:
extensions:
- redis
```
###### 3. Add the Drupal module
To add the Redis module to your project, run the following command:
```bash
composer require drupal/redis
```
Then commit the resulting changes to your `composer.json`
and `composer.lock` files. Afterwards, you can enable the module with:
```bash
platform drush enable redis
```
##### Configure your Redis service
To configure your Redis service, follow these steps:
1. Add the following code at the top of your `settings.platformsh.php` file:
```php {location="settings.platformsh.php"}
inRuntime()) {
return;
}
```
2. Add the following code at the end of the file:
```php {location="settings.platformsh.php"}
hasRelationship('rediscache') && !InstallerKernel::installationAttempted() && extension_loaded('redis')) {
$redis = $platformsh->credentials('rediscache');
// Set Redis as the default backend for any cache bin not otherwise specified.
$settings['cache']['default'] = 'cache.backend.redis';
$settings['redis.connection']['host'] = $redis['host'];
$settings['redis.connection']['port'] = $redis['port'];
// You can leverage Redis by using it for the lock and flood control systems
// and the cache tag checksum.
// To do so, apply the following changes to the container configuration.
// Alternatively, copy the contents of the modules/contrib/redis/example.services.yml file
// to your project-specific services.yml file.
// Modify the contents to fit your needs and remove the following line.
$settings['container_yamls'][] = 'modules/contrib/redis/example.services.yml';
// Allow the services to work before the Redis module itself is enabled.
$settings['container_yamls'][] = 'modules/contrib/redis/redis.services.yml';
// To use Redis for container cache, add the classloader path manually.
$class_loader->addPsr4('Drupal\\redis\\', 'modules/contrib/redis/src');
// Use Redis for container cache.
// The container cache is used to load the container definition itself.
// This means that any configuration stored in the container isn't available
// until the container definition is fully loaded.
// To ensure that the container cache uses Redis rather than the
// default SQL cache, add the following lines.
$settings['bootstrap_container_definition'] = [
'parameters' => [],
'services' => [
'redis.factory' => [
'class' => 'Drupal\redis\ClientFactory',
],
'cache.backend.redis' => [
'class' => 'Drupal\redis\Cache\CacheBackendFactory',
'arguments' => ['@redis.factory', '@cache_tags_provider.container', '@serialization.phpserialize'],
],
'cache.container' => [
'class' => '\Drupal\redis\Cache\PhpRedis',
'factory' => ['@cache.backend.redis', 'get'],
'arguments' => ['container'],
],
'cache_tags_provider.container' => [
'class' => 'Drupal\redis\Cache\RedisCacheTagsChecksum',
'arguments' => ['@redis.factory'],
],
'serialization.phpserialize' => [
'class' => 'Drupal\Component\Serialization\PhpSerialize',
],
],
];
}
```
You can customize your configuration further
using the inline comments from this example configuration.
For more information on possible configuration options,
see the `README.txt` file delivered with the Redis module
or the [official Redis documentation](https://redis.io/docs/).
##### Verify Redis is running
To verify that Redis is running, run the following command:
```bash
platform redis info
```
The output produces information and statistics about Redis,
showing that the service is up and running.
### Using Valkey with Drupal
[Valkey](https://valkey.io/) is an open source datastore that can be used high-performance data retrieval and key-value storage. For more information on this service, see the [dedicated Valkey page](https://docs.platform.sh../../add-services/valkey.md) or the [official Valkey documentation](https://valkey.io/topics/).
Follow the instructions on this page to do one of the following:
- Add and configure Valkey for Drupal if you have deployed Drupal manually.
- Fine-tune your existing configuration if you have deployed Drupal using a [Platform.sh template](https://docs.platform.sh../../development/templates.md).
##### Before you begin
You need:
- A [Drupal version deployed on Platform.sh](https://docs.platform.sh../drupal/deploy.md)
- The [Platform.sh CLI](https://docs.platform.sh../../administration/cli/)
- [Composer](https://getcomposer.org/)
- The [Config Reader library](https://docs.platform.sh../../guides/drupal/deploy/customize.md#install-the-config-reader)
You also need a `settings.platformsh.php` file from which you can [manage the configuration of the Valkey service](https://docs.platform.sh../drupal/deploy/customize.md#settingsphp).
If you installed Drupal with a template, this file is already present in your project.
**Note**:
By default, Valkey is an ephemeral service.
This means that the Valkey storage isn’t persistent
and that data can be lost when a container is moved, shut down
or when the service hits its memory limit.
To solve this, Platform.sh recommends that you change the [service type](https://docs.platform.sh/add-services/valkey.md#service-types)
to [persistent Valkey](https://docs.platform.sh/add-services/valkey.md#persistent-valkey) (``valkey-persistent``).
##### Add a Valkey service
###### 1. Configure the service
To define the service, use the `valkey-persistent` endpoint:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: valkey-persistent:8.0
```
Note that changing the name of the service replaces it with a brand new service and all existing data is lost.
Back up your data before changing the service.
###### 2. Define the relationship
To define the relationship, use the `valkey` endpoint :
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services and matches in both the application and services configuration.
The example above leverages [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships. That is, it uses default endpoints behind-the-scenes, providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) (the network address a service is accessible from) that is identical to the name of that service.
Depending on your needs, instead of default endpoint configuration, you can use [explicit endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has access to the service via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: valkey
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has access to the service via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
For PHP, enable the [extension](https://docs.platform.sh/languages/php/extensions) for the service:
```yaml {location=".platform.app.yaml"}
# PHP extensions.
runtime:
extensions:
- redis
```
###### 3. Add the Drupal module
[Drupal supports Valkey through the existing redis module](https://www.drupal.org/project/redis/issues/3443819). To add
the Redis module to your project, run the following command:
```bash
composer require drupal/redis
```
Then commit the resulting changes to your `composer.json`
and `composer.lock` files. Afterwards, you can enable the module with:
```bash
platform drush enable redis
```
##### Configure your Valkey service
To configure your Valkey service, follow these steps:
1. Add the following code at the top of your `settings.platformsh.php` file:
```php {location="settings.platformsh.php"}
inRuntime()) {
return;
}
```
2. Add the following code at the end of the file:
```php {location="settings.platformsh.php"}
hasRelationship('valkeycache') && !InstallerKernel::installationAttempted() && extension_loaded('valkey')) {
$valkey = $platformsh->credentials('valkeycache');
// Set Valkey as the default backend for any cache bin not otherwise specified.
$settings['cache']['default'] = 'cache.backend.valkey';
$settings['valkey.connection']['host'] = $valkey['host'];
$settings['valkey.connection']['port'] = $valkey['port'];
// You can leverage Valkey by using it for the lock and flood control systems
// and the cache tag checksum.
// To do so, apply the following changes to the container configuration.
// Alternatively, copy the contents of the modules/contrib/valkey/example.services.yml file
// to your project-specific services.yml file.
// Modify the contents to fit your needs and remove the following line.
$settings['container_yamls'][] = 'modules/contrib/valkey/example.services.yml';
// Allow the services to work before the Valkey module itself is enabled.
$settings['container_yamls'][] = 'modules/contrib/valkey/valkey.services.yml';
// To use Valkey for container cache, add the classloader path manually.
$class_loader->addPsr4('Drupal\\valkey\\', 'modules/contrib/valkey/src');
// Use Valkey for container cache.
// The container cache is used to load the container definition itself.
// This means that any configuration stored in the container isn't available
// until the container definition is fully loaded.
// To ensure that the container cache uses Valkey rather than the
// default SQL cache, add the following lines.
$settings['bootstrap_container_definition'] = [
'parameters' => [],
'services' => [
'valkey.factory' => [
'class' => 'Drupal\valkey\ClientFactory',
],
'cache.backend.valkey' => [
'class' => 'Drupal\valkey\Cache\CacheBackendFactory',
'arguments' => ['@valkey.factory', '@cache_tags_provider.container', '@serialization.phpserialize'],
],
'cache.container' => [
'class' => '\Drupal\valkey\Cache\PhpValkey',
'factory' => ['@cache.backend.valkey', 'get'],
'arguments' => ['container'],
],
'cache_tags_provider.container' => [
'class' => 'Drupal\valkey\Cache\ValkeyCacheTagsChecksum',
'arguments' => ['@valkey.factory'],
],
'serialization.phpserialize' => [
'class' => 'Drupal\Component\Serialization\PhpSerialize',
],
],
];
}
```
You can customize your configuration further
using the inline comments from this example configuration.
For more information on possible configuration options,
see the `README.txt` file delivered with the Valkey module
or the [official Valkey documentation](https://valkey.io/topics/).
##### Verify Valkey is running
To verify that Valkey is running, run the following command:
```bash
platform valkey info
```
The output produces information and statistics about Valkey,showing that the service is up and running.
##### Further resources
###### Documentation
- [Valkey documentation](https://valkey.io/topics/)
- [Platform.sh Valkey Documentation](https://docs.platform.sh/add-services/valkey)
### SimpleSAML
SimpleSAMLphp is a library for authenticating a PHP-based application against a SAML server, such as Shibboleth.
Although Drupal has modules available to authenticate using SimpleSAML some additional setup is required.
The following configuration assumes you are building Drupal using Composer.
If not, you need to download the library manually and adjust some paths accordingly.
##### Download the library and Drupal module
The easiest way to download SimpleSAMLphp is via Composer.
The following command will add both the Drupal module and the PHP library to your `composer.json` file.
```bash
composer require simplesamlphp/simplesamlphp drupal/externalauth drupal/simplesamlphp_auth
```
Once that's run, commit both `composer.json` and `composer.lock` to your repository.
##### Include SimpleSAML cookies in the cache key
The SimpleSAML client uses additional cookies besides the Drupal session cookie that need to be allowed for the cache.
To do so, modify your `.platform/routes.yaml` file for the route that points to your Drupal site and add two additional cookies to the `cache.cookies` line.
It should end up looking approximately like this:
```yaml {location=".platform/routes.yaml"}
"https://{default}/":
type: upstream
upstream: "myapp:http"
cache:
enabled: true
cookies: ['/^SS?ESS/', '/^Drupal.visitor/', 'SimpleSAMLSessionID', 'SimpleSAMLAuthToken']
```
Commit this change to the Git repository.
##### Expose the SimpleSAML endpoint
The SimpleSAML library's `www` directory needs to be publicly accessible.
That can be done by mapping it directly to a path in the Application configuration.
Add the following block to the `web.locations` section of `.platform.app.yaml`:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/simplesaml':
root: 'vendor/simplesamlphp/simplesamlphp/www'
allow: true
scripts: true
index:
- index.php
```
That will map all requests to `example.com/simplesaml/` to the `vendor/simplesamlphp/www` directory, allowing static files there to be served, PHP scripts to execute, and defaulting to index.php.
##### Create a configuration directory
Your SimpleSAMLphp configuration needs to be outside of the `vendor` directory.
The `composer require` downloads a template configuration file to `vendor/simplesamlphp/simplesamlphp/config`.
Rather than modifying that file in place (as it isn't included in Git),
copy the `vendor/simplesamlphp/simplesamlphp/config` directory to `simplesamlphp/config` (in [your app root](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#root-directory)).
It should contain two files, `config.php` and `authsources.php`.
Additionally, create a `simplesamlphp/metadata` directory.
This directory holds your IdP definitions.
Consult the SimpleSAMLphp documentation and see the examples in `vendor/simplesamlphp/simplesamlphp/metadata-templates`.
Next, you need to tell SimpleSAMLphp where to find that directory using an environment variable.
The simplest way to set that is to add the following block to your `.platform.app.yaml` file:
```yaml {location=".platform.app.yaml"}
variables:
env:
SIMPLESAMLPHP_CONFIG_DIR: /app/simplesamlphp/config
```
Commit the whole `simplesamplphp` directory and `.platform.app.yaml` to Git.
##### Configure SimpleSAML to use the database
SimpleSAMLphp is able to store its data either on disk or in the Drupal database.
Platform.sh strongly recommends using the database.
Open the file `simplesamlphp/config/config.php` that you created earlier.
It contains a number of configuration properties that you can adjust as needed.
Some are best edited in-place and the file already includes ample documentation, specifically:
* `auth.adminpassword`
* `technicalcontact_name`
* `technicalcontact_email`
Others are a little more involved.
In the interest of simplicity we recommend pasting the following code snippet at the end of the file, as it will override the default values in the array.
```php {location="simplesamlphp/config/config.php"}
'flatfile', 'directory' => dirname(__DIR__) . '/metadata'],
];
// Setup the database connection for all parts of SimpleSAML.
if (isset($_ENV['PLATFORM_RELATIONSHIPS'])) {
$relationships = json_decode(base64_decode($_ENV['PLATFORM_RELATIONSHIPS']), TRUE);
foreach ($relationships['database'] as $instance) {
if (!empty($instance['query']['is_master'])) {
$dsn = sprintf("%s:host=%s;dbname=%s",
$instance['scheme'],
$instance['host'],
$instance['path']
);
$config['database.dsn'] = $dsn;
$config['database.username'] = $instance['username'];
$config['database.password'] = $instance['password'];
$config['store.type'] = 'sql';
$config['store.sql.dsn'] = $dsn;
$config['store.sql.username'] = $instance['username'];
$config['store.sql.password'] = $instance['password'];
$config['store.sql.prefix'] = 'simplesaml';
}
}
}
// Set the salt value from the Platform.sh entropy value, provided for this purpose.
if (isset($_ENV['PLATFORM_PROJECT_ENTROPY'])) {
$config['secretsalt'] = $_ENV['PLATFORM_PROJECT_ENTROPY'];
}
```
##### Generate SSL certificates (optional)
Depending on your Identity Provider (IdP),
you may need to generate an SSL/TLS certificate to connect to the service provider.
If so, you should generate the certificate locally following the instructions in the [SimpleSAMLphp documentation](https://simplesamlphp.org/docs/stable/index.md).
Your resulting IdP file should be placed in the `simplesamlphp/metadata` directory.
The certificate should be placed in the `simplesamlphp/cert` directory.
(Create it if needed.)
Then add the following line to your `simplesamlphp/config/config.php` file to tell the library where to find the certificate:
```php {location="simplesamlphp/config/config.php"}
`` by ``symfony cloud:`` in all of your commands.
##### Create your Symfony app
To get familiar with Platform.sh, create a new Symfony project from scratch.
The present tutorial uses the [Symfony Demo](https://symfony.com/doc/current/setup.md#the-symfony-demo-application) app as an example :
```bash
symfony new --demo --cloud
cd
```
The `--demo` flag pulls the [Symfony Demo skeleton](https://github.com/symfony/demo).
The `--cloud` flag automatically generates the Platform.sh configuration files.
**Note**:
Alternatively, you can deploy an **existing Symfony project**.
To do so, follow these steps:
- To generate a sensible default Platform.sh configuration,
run the following command from within the project’s directory:
```bash {}
symfony project:init
```
This generates the following set of configuration files: ``.platform.app.yaml``, ``.platform/services.yaml``, ``.platform/routes.yaml``, and ``php.ini``.
- Commit these new files to your repository:
```bash {}
git add .platform.app.yaml .platform/services.yaml .platform/routes.yaml php.ini
git commit -m "Add Platform.sh configuration"
```
Platform.sh manages the entire infrastructure of your project,
from code to services (such as databases, queues, or search engines),
all the way to email sending, [cron jobs](https://docs.platform.sh/guides/symfony/crons.md), and [workers](https://docs.platform.sh/guides/symfony/workers.md).
This infrastructure is described through configuration files stored alongside your code.
##### Create the project
To create the project on Platform.sh, run the following command from within the project's directory:
```bash
symfony cloud:create --title PROJECT_TITLE --set-remote
```
The `--set-remote` flag sets the new project as the remote for this repository.
**Tip**:
You can link any repository to an existing Platform.sh project using the following command:
```bash {}
symfony project:set-remote
```
##### Deploy your project
To deploy your project, run the following command:
```bash
symfony cloud:deploy
```
**Tip**:
During deployment, the logs from the Platform.sh API are displayed in your terminal so you can monitor progress.
To stop the display of the logs **without interrupting the deployment**,
use ``CTRL+C`` in your terminal.
To go back to displaying the logs, run ``symfony cloud:activity:log``.
Congratulations, your first Symfony app has been deployed on Platform.sh!
Now that your app is deployed in production mode,
you can define a custom domain for your live website.
To do so, see how to [set up a custom domain on Platform.sh](https://docs.platform.sh/administration/web/configure-project.md#domains),
or run the following command:
```bash
symfony cloud:domain:add
```
##### Make changes to your project
Now that your project is deployed, you can start making changes to it.
For example, you might want to fix a bug or add a new feature.
In your project, the main branch always represents the production environment.
Other branches are for developing new features, fixing bugs, or updating the infrastructure.
To make changes to your project, follow these steps:
1. Create a new environment (a Git branch) to make changes without impacting production:
```bash
symfony cloud:branch feat-a
```
This command creates a new local `feat-a` Git branch based on the main Git branch
and activates a related environment on Platform.sh.
The new environment inherits the data (service data and assets) of its parent environment (the production environment here).
2. Make changes to your project.
For example, if you created a Symfony Demo app,
edit the `templates/default/homepage.html.twig` template and make the following visual changes:
```html {location="templates/default/homepage.html.twig"}
{% block body %}
- {{ 'title.homepage'|trans|raw }}
+ Welcome to the Platform.sh Demo
```
3. Commit your changes:
```bash
git commit -a -m "Update text"
```
4. Deploy your changes to the `feat-a` environment:
```bash
symfony cloud:deploy
```
Note that each environment has its own domain name.
To view the domain name of your new environment, run the following command:
```bash
symfony cloud:url --primary
```
5. Iterate by changing the code, committing, and deploying.
When satisfied with your changes, merge them to the main branch, deploy,
and remove the feature branch:
```bash
git checkout main
git merge feat-a
symfony environment:delete feat-a
git branch -d feat-a
symfony cloud:deploy
```
**Note**:
Deploying to production was fast because the image built for the ``feat-a`` environment was reused.
For a long running branch, to keep the code up-to-date with the main branch, use `git merge main` or `git rebase main`.
You can also keep the data in sync with the production environment by using `symfony cloud:env:sync`.
##### Use a third-party Git provider
When you choose to use a third-party Git hosting service, the Platform.sh Git
repository becomes a read-only mirror of the third-party repository. All your
changes take place in the third-party repository.
Add an integration to your existing third-party repository:
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
##### Next steps
###### Symfony integration
Learn more about the [Symfony integration](https://docs.platform.sh/guides/symfony/integration.md),
a set of tools and auto-configurations that makes it easier to use Platform.sh for Symfony projects.
###### Environment variables
When you use the Symfony integration,
more [environment variables](https://docs.platform.sh/guides/symfony/environment-variables.md) related to Symfony are defined.
###### Local development
Once Symfony has been deployed on Platform.sh,
you might want to [set up a local development environment](https://docs.platform.sh/guides/symfony/local.md).
###### Symfony CLI tips
You might find the following commands useful when using the Symfony CLI.
- Open the web administration console:
```bash
symfony cloud: web
```
- Open the URL of the current environment:
```bash
symfony cloud: url
```
- Open an SSH connection to your environment:
```bash
symfony cloud: ssh
```
- Initialize a new project using templates:
```bash
symfony project:init
```
- Get a list of all the domains:
```bash
symfony cloud:domains
```
- Create a new environment:
```bash
symfony cloud:branch new-branch
```
- Get a list of all the environments:
```bash
symfony cloud:environments
```
- Push code to the current environment:
```bash
symfony cloud:push
```
- Get a list of all the active projects:
```bash
symfony cloud:projects
```
- Add a user to the project:
```bash
symfony cloud:user:add
```
- List variables:
```bash
symfony cloud:variables
```
You might find the following commands useful when using a database with your Symfony app.
- Create a local dump of the remote database:
```bash
symfony cloud: db:dump --relationship database
```
- Run an SQL query on the remote database:
```bash
symfony cloud: sql 'SHOW TABLES'
```
- Import a local SQL file into a remote database:
```bash
symfony cloud: sql < my_database_backup.sql
```
### Symfony integration
Symfony has a special integration with Platform.sh that makes it easier to use Platform.sh for Symfony projects.
**When using the Symfony integration, you are contributing financially to the Symfony project.**
The Symfony integration is automatically enabled when:
- You run the `symfony new` command with the `--cloud` option;
- You run `symfony project:init` on an existing project to automatically
generate the Platform.sh configuration.
If you already have a Platform.sh configuration without the Symfony
integration, enable it by adding the following configuration:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -x -e
curl -fs https://get.symfony.com/cloud/configurator | bash
# ...
```
The **configurator** enables the following integration:
- It installs some helper scripts that you can use as the [default build and deploy hook scripts](#hooks):
- [`symfony-build`](#symfony-build);
- [`symfony-deploy`](#symfony-deploy);
- [`php-ext-install`](#php-ext-install).
- It adds some [extra tools](#tools);
- It defines [additional infrastructure environment
variables](https://docs.platform.sh/guides/symfony/environment-variables.md#symfony-environment-variables) and
[environment variables for all
services](https://docs.platform.sh/guides/symfony/environment-variables.md#service-environment-variables).
##### Tools
The **configurator** (`curl -fs https://get.symfony.com/cloud/configurator | bash`) is a script specially crafted for Platform.sh.
It ensures that projects are always using the latest version of the following tools:
- [croncape](https://docs.platform.sh/guides/symfony/crons.md#use-croncape) for cron feedback
- [Symfony CLI](https://symfony.com/download)
- [Composer](https://getcomposer.org/download/)
##### Hooks
The `hooks` section defines the scripts that Platform.sh runs at specific times of an application lifecycle:
- The [build hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#build-hook) is run during the build process
- The [deploy hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#deploy-hook) is run during the deployment process
- The [post-deploy hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook) is run after the deploy hook,
once the application container starts accepting connections
Here's the default `hooks` section optimized for Symfony projects:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -x -e
curl -s https://get.symfony.com/cloud/configurator | bash
symfony-build
deploy: |
set -x -e
symfony-deploy
```
**Warning**:
As each hook is executed as a single script, a hook is considered as failed only if the final command fails.
To have your hooks fail on the first failed command, start your scripts with ``set -e``.
For more information, see [Hooks](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md).
To gain a better understanding of how hooks relate to each other when building and deploying an app,
see the [Platform.sh philosophy](https://docs.platform.sh/learn/overview/philosophy.md).
**Tip**:
During the ``deploy`` or ``post_deploy`` hooks, you can execute actions for a specific environment type only.
To do so, in your ``.platform.app.yaml``file,
use the ``PLATFORM_ENVIRONMENT_TYPE`` [environment variable](https://docs.platform.sh/development/variables.md)) in a condition:
.platform.app.yaml
```yaml {}
hooks:
deploy: |
if [ "PLATFORM_ENVIRONMENT_TYPE" != "production" ]; then
symfony console app:dev:anonymize
fi
```
###### symfony-build
**symfony-build** is the script that builds a Symfony app in an optimized way for Platform.sh.
Use it as the main build script in your `build` hook.
**symfony-build** performs the following actions:
- Removes the development frontend file (Symfony <4)
- Installs PHP extensions through the [`php-ext-install` script](#php-ext-install)
- Installs application dependencies using Composer
- Optimizes the autoloader
- Builds the Symfony cache in an optimized way to limit the time it takes to deploy
- Installs the JavaScript dependencies via npm or Yarn
- Builds the production assets using Encore
To override the flags used by Composer, use the `$COMPOSER_FLAGS` environment variable:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -x -e
curl -s https://get.symfony.com/cloud/configurator | bash
COMPOSER_FLAGS="--ignore-platform-reqs" symfony-build
```
When installing dependencies, the script automatically detects if the app is using npm or Yarn.
To disable the JavaScript dependencies and asset building,
set `NO_NPM` or `NO_YARN` to `1` depending on your package manager.
To customize Node/npm/Yarn behaviors,
prefix the `symfony-build` script with the following environment variables:
- ``NODE_VERSION``: to pinpoint the Node version that nvm is going to install.
The default value is ``--lts``.
- ``YARN_FLAGS``: flags to pass to ``yarn install``.
There is no default value.
###### symfony-deploy
Use **symfony-deploy** as the main deploy script in the `deploy` hook.
It only works if you're using the [`symfony-build` script](#symfony-build) in your `build` hook.
**symfony-deploy** performs the following actions:
- Replaces the Symfony cache with the cache generated during the build hook
- Migrates the database when the Doctrine migration bundle is used
###### php-ext-install
You can use the **php-ext-install** script to compile and install PHP extensions
not provided out of the box by Platform.sh,
or when you need a specific version of an extension.
The script is written specifically for Platform.sh to ensure fast and reliable setup during the build step.
**php-ext-install** currently supports three ways of fetching sources:
- From [PECL](https://pecl.php.net/): ``php-ext-install redis 5.3.2``
- From a URL: ``php-ext-install redis https://github.com/phpredis/phpredis/archive/5.3.2.tar.gz``
- From a Git repository: ``php-ext-install redis https://github.com/phpredis/phpredis.git 5.3.2``
To ensure your app can be built properly, run ``php-ext-install`` after the [configurator](#tools)
but before [symfony-build](#symfony-build):
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -x -e
curl -s https://get.symfony.com/cloud/configurator | bash
php-ext-install redis 5.3.2
symfony-build
```
When installing [PECL](https://pecl.php.net/) PHP extensions, you can configure
them directly as *variables* instead:
```yaml {location=".platform.app.yaml"}
variables:
php-ext:
redis: 5.3.2
```
**Note**:
The source code is cached between builds so compilation is skipped if it’s already been done.
Changing the source of downloads or the version invalidates this cache.
###### Advanced Node configuration
If you need to use the Node installation setup by [symfony-build](#symfony-build),
use the following configuration:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -x -e
curl -s https://get.symfony.com/cloud/configurator | bash
symfony-build
# Setup everything to use the Node installation
unset NPM_CONFIG_PREFIX
export NVM_DIR=${PLATFORM_APP_DIR}/.nvm
set +x && . "${NVM_DIR}/nvm.sh" use --lts && set -x
# Starting from here, everything is setup to use the same Node
yarn encore dev
```
If you want to use two different Node versions,
use the following configuration instead:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -x -e
curl -s https://get.symfony.com/cloud/configurator | bash
symfony-build
cd web/js_app
unset NPM_CONFIG_PREFIX
export NVM_DIR=${PLATFORM_APP_DIR}/.nvm
NODE_VERSION=8 yarn-install
# Setup everything to use the Node installation
set +x && . "${NVM_DIR}/nvm.sh" use 8 && set -x
# Starting from here, everything is setup to use Node 8
yarn build --environment=prod
```
### Environment variables
By default, Platform.sh exposes some [environment variables](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
If you're using the [Symfony integration](https://docs.platform.sh/guides/symfony/integration.md),
more [infrastructure environment variables](#symfony-environment-variables) related to Symfony are defined.
As Symfony relies heavily on environment variables to configure application services (such as the database or the mailer DSN),
the Symfony integration automatically defines [environment variables for all the services](#service-environment-variables) connected to your app.
**Tip**:
The code that defines these additional environment variables is part of the open-source [Symfony CLI tool](https://symfony.com/download).
Check the code for [infrastructure](https://github.com/symfony-cli/symfony-cli/blob/main/envs/remote.go#L139)
and [service](https://github.com/symfony-cli/symfony-cli/blob/main/envs/envs.go#L110) environment variables on GitHub.
##### Symfony environment variables
Platform.sh exposes [environment variables](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables)
about the app and its infrastructure.
The Symfony integration exposes more environment variables:
- `APP_ENV` is set to `prod` by default.
You can manually override this value for a preview environment
by setting the `SYMFONY_ENV` environment variable to `dev`, and remove it when done.
- `APP_DEBUG` is set to `0` by default.
You can manually override this value for a preview environment
by setting the `SYMFONY_DEBUG` environment variable to `1`, and remove it when done.
- `APP_SECRET` is set to the value of `PLATFORM_PROJECT_ENTROPY`, which is a random and unique value for all Platform.sh projects.
It overrides the value configured in the `.env` file of your app.
- `MAILFROM` is set to a random value.
This value is used as a `From` header when using [croncape](https://docs.platform.sh/guides/symfony/crons.md#use-croncape).
- `SYMFONY_IS_WORKER` is set to `1` when the container is running in the context of a worker
(instead of the main application container).
- `SYMFONY_CACHE_DIR` (only available during the build hook execution):
The absolute path to a subdirectory of your build cache directory.
Note that the build cache directory is persisted between builds but **isn't** deployed.
It’s a good place to store build artifacts, such as downloaded files that can be reused between builds.
**Tip**:
This directory is shared by **all** builds on **all** branches.
Make sure your [build hook](https://docs.platform.sh/guides/symfony/integration.md#hooks) accounts for that.
If you need to clear the build cache directory, run the `symfony cloud:project:clear-build-cache` command.
- `SYMFONY_PROJECT_DEFAULT_ROUTE_URL` (only defined at **runtime**): The default endpoint serving your project.
Use this variable to avoid hard-coding domains that can be used to reach preview environments.
Parts of the URL are also exposed as their own variables using the following syntax:
`SYMFONY_PROJECT_DEFAULT_ROUTE_` followed by the name of the part (`SCHEME`, `DOMAIN`, `PORT`, and `PATH`).
Guessing the default endpoint can prove difficult for multi-routes or multi-app projects.
In such cases, the following preference order is used:
1. Project-wide route defined only by `{default}` or `{all}` (no path)
2. Project-wide route defined by `www.{default}` or `www.{all}` (no path)
3. Route for the **current application** including `{default}` or `{all}` (might include a path)
4. Route for the **current application** including `www.{default}` or `www.{all}` (might include a path)
5. First route for the current application
6. First route for the whole project
When several routes match a rule, the first one wins, the user order is kept. There's no preference regarding protocols.
**Tip**:
If you have a multi-app project containing several publicly reachable apps,
you might need to determine the current application endpoint (for webhooks for example)
and the project endpoint (to send emails for example).
In this case, you can use an additional ``SYMFONY_APPLICATION_DEFAULT_ROUTE_*`` set of environment variables.
The same rules are applied to determine their value, but only routes matching the current application are evaluated.
##### Service environment variables
When using the [Symfony integration](https://docs.platform.sh/guides/symfony/integration.md), information about services
are exposed via environment variables.
To list all of the exposed environment variables, run the following command:
```bash
symfony ssh -- symfony var:export --multiline
```
Each exposed environment variable is prefixed by the relationship name.
For example, if you have the following [relationships](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) in your configuration:
```yaml
relationships:
database:
service: securitydb
endpoint: postgresql
```
The environment variables for the database service is prefixed by `DATABASE_`
which is the upper-cased version of the key defined in the relationship.
For example, you could have a `DATABASE_URL` environment variable.
Most environment variable names are derived from the relationship and service names.
But some are defined based on Symfony conventions, such as [`MAILER_DSN`](#emails).
**Note**:
Environment variables aren’t exposed when the build hook script is running
as services aren’t available during the [build process](https://docs.platform.sh/learn/overview/build-deploy.md#the-build).
###### Emails
The configuration is exposed via the following environment variables:
- `MAILER_ENABLED`: 1 if outgoing emails are enabled, 0 otherwise
- `MAILER_DSN`/`MAILER_URL`: The Symfony-compatible mailer URL
- `MAILER_HOST`: The SMTP server host
- `MAILER_PORT`: The SMTP server port
- `MAILER_TRANSPORT`: The SMTP transport mode (`smtp`)
- `MAILER_AUTH_MODE`: The SMTP auth mode (`plain`)
- `MAILER_USER`: The SMTP server user
- `MAILER_PASSWORD`: The SMTP server password
Symfony Mailer automatically uses the value of `MAILER_DSN`.
###### HTTP
If your project has multiple apps,
the configuration is exposed via the following environment variables
(where `SOME_SERVICE` is the upper-cased version of the key defined in the relationship):
- `SOME_SERVICE_URL`: The full URL of the service
- `SOME_SERVICE_IP`: The HTTP service IP
- `SOME_SERVICE_PORT`: The HTTP service port
- `SOME_SERVICE_SCHEME`: The HTTP service scheme
- `SOME_SERVICE_HOST`: The HTTP service host
###### MySQL/MariaDB
The [MySQL/MariaDB](https://docs.platform.sh/add-services/mysql.md) configuration is exposed via the following environment variables
(where `DATABASE` is the upper-cased version of the key defined in the relationship above):
- `DATABASE_URL`: The database URL (in PHP or Go format depending on your app)
- `DATABASE_SERVER`: The database server
- `DATABASE_DRIVER`: The database driver
- `DATABASE_VERSION`: The database version
- `DATABASE_HOST`: The database host
- `DATABASE_PORT`: The database port
- `DATABASE_NAME`: The database name
- `DATABASE_DATABASE`: Alias for `DATABASE_NAME`
- `DATABASE_USERNAME`: The database username
- `DATABASE_PASSWORD`: The database password
**Tip**:
The database version and a default charset are included in the database URL.
To override them, use the ``DATABASE_VERSION`` and ``DATABASE_CHARSET`` environment variables respectively.
###### PostgreSQL
The [PostgreSQL](https://docs.platform.sh/add-services/postgresql.md) configuration is exposed via the following environment variables
(where `DATABASE` is the upper-cased version of the key defined in the relationship):
- `DATABASE_URL`: The database URL (in PHP or Go format depending on your app)
- `DATABASE_SERVER`: The database server
- `DATABASE_DRIVER`: The database driver
- `DATABASE_VERSION`: The database version
- `DATABASE_HOST`: The database host
- `DATABASE_PORT`: The database port
- `DATABASE_NAME`: The database name
- `DATABASE_DATABASE`: Alias for `DATABASE_NAME`
- `DATABASE_USERNAME`: The database username
- `DATABASE_PASSWORD`: The database password
**Tip**:
The database version and a default charset are included in the database URL.
To override them, use the ``DATABASE_VERSION`` and ``DATABASE_CHARSET`` environment variables respectively.
###### Redis
The [Redis](https://docs.platform.sh/add-services/redis.md) configuration is exposed via the following environment variables
(where `REDIS` is the upper-cased version of the key defined in the relationship):
- `REDIS_URL`: The Redis URL
- `REDIS_HOST`: The Redis host
- `REDIS_PORT`: The Redis port
- `REDIS_SCHEME`: The Redis scheme
###### Memcached
The [Memcached](https://docs.platform.sh/add-services/memcached.md) configuration is exposed via the following environment variables
(where `CACHE` is the upper-cased version of the key defined in the relationship):
- `CACHE_HOST`
- `CACHE_PORT`
- `CACHE_IP`
###### Elasticsearch
The [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md) configuration is exposed via the following environment variables
(where `ELASTICSEARCH` is the upper-cased version of the key defined in the relationship):
- `ELASTICSEARCH_URL`: The full URL of the Elasticsearch service
- `ELASTICSEARCH_HOST`: The Elasticsearch host
- `ELASTICSEARCH_PORT`: The Elasticsearch port
- `ELASTICSEARCH_SCHEME`: The Elasticsearch protocol scheme (`http` or `https`)
###### Solr
The [Apache Solr](https://docs.platform.sh/add-services/solr.md) configuration is exposed via the following environment variables
(where `SOLR` is the upper-cased version of the key defined in the relationship):
- `SOLR_HOST`: The Solr host
- `SOLR_PORT`: The Solr port
- `SOLR_NAME`: The Solr name
- `SOLR_DATABASE`: An alias for `SOLR_NAME`
###### RabbitMQ
The [RabbitMQ](https://docs.platform.sh/add-services/rabbitmq.md) configuration is exposed via the following environment variables
(where `RABBITMQ` is the upper-cased version of the key defined in the relationship):
- `RABBITMQ_URL`: The RabbitMQ standardized URL
- `RABBITMQ_SERVER`: The RabbitMQ server
- `RABBITMQ_HOST`: The RabbitMQ host
- `RABBITMQ_PORT`: The RabbitMQ port
- `RABBITMQ_SCHEME`: The RabbitMQ scheme
- `RABBITMQ_USER`: The RabbitMQ username
- `RABBITMQ_USERNAME`: The RabbitMQ username
- `RABBITMQ_PASSWORD`: The RabbitMQ password
###### MongoDB
The [MongoDB](https://docs.platform.sh/add-services/mongodb.md) configuration is exposed via the following environment variables
(where `MONGODB` is the upper-cased version of the key defined in the relationship):
- `MONGODB_SERVER`
- `MONGODB_HOST`
- `MONGODB_PORT`
- `MONGODB_SCHEME`
- `MONGODB_NAME`
- `MONGODB_DATABASE`
- `MONGODB_USER`
- `MONGODB_USERNAME`
- `MONGODB_PASSWORD`
###### InfluxDB
The [InfluxDB](https://docs.platform.sh/add-services/influxdb.md) configuration is exposed via the following environment variables
(where `TIMEDB` is the upper-cased version of the key defined in the relationship):
- `TIMEDB_SCHEME`
- `TIMEDB_HOST`
- `TIMEDB_PORT`
- `TIMEDB_IP`
###### Kafka
The [Apache Kafka](https://docs.platform.sh/add-services/kafka.md) configuration is exposed via the following environment variables
(where `KAFKA` is the upper-cased version of the key defined in the relationship):
- `KAFKA_URL`
- `KAFKA_SCHEME`
- `KAFKA_HOST`
- `KAFKA_PORT`
- `KAFKA_IP`
### Workers
Workers (or consumers) are a great way to off-load processing in the background
to make an app as fast as possible.
You can implement workers in Symfony smoothly thanks to the [Messenger component](https://symfony.com/doc/current/components/messenger.md).
To deploy a worker, add an entry under the ``workers`` section [in your app configuration](https://docs.platform.sh/create-apps/_index.md):
```yaml {location=".platform.app.yaml"}
workers:
mails:
commands:
start: symfony console messenger:consume --time-limit=60 --memory-limit=128M
```
Note that the `symfony` binary is available when you use the [Symfony
integration](https://docs.platform.sh/guides/symfony/integration.md) in your Platform.sh app configuration.
On Platform.sh, worker containers run the exact same code as the web container.
The container image is built only once and deployed multiple times in its own container alongside the web container.
The *build* hook and dependencies might not vary but,
as these containers are independent, they can be customized the same way using common properties.
The values defined for the main container are used as default values.
**Tip**:
When the container is running in the context of a worker, the
``SYMFONY_IS_WORKER`` environment variable is defined and set to ``1``.
The ``commands.start`` key is required.
It specifies the command you can use to launch the application worker.
If the command specified by the ``start`` key terminates, it's restarted automatically.
For more information, see [Workers](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#workers).
**Warning**:
Web and worker containers don’t share mounts targets.
So you can’t share files between those containers using the filesystem.
To share data between containers, use [services](https://docs.platform.sh/add-services.md).
### Cron Jobs
Cron jobs allow you to run scheduled tasks at specified times or intervals.
To set up a cron job, add a configuration similar to the following:
```yaml {location=".platform.app.yaml"}
crons:
snapshot:
spec: 0 5 * * *
commands:
start: croncape symfony ...
```
To run a command in a cron hook for specific environment types,
use the `PLATFORM_ENVIRONMENT_TYPE` environment variable:
```yaml {location=".platform.app.yaml"}
crons:
snapshot:
spec: 0 5 * * *
commands:
start: |
# only run for the production environment, aka main branch
if [ "$PLATFORM_ENVIRONMENT_TYPE" = "production" ]; then
croncape symfony ...
fi
```
##### Use croncape
When using the [Symfony integration](https://docs.platform.sh/guides/symfony/integration),
you can use `croncape` to get feedback through emails when something goes wrong.
To specify which email address `croncape` must send the feedback emails to,
add a `MAILTO` environment variable.
To do so, run the following command:
```bash
symfony var:create -y --level=project --name=env:MAILTO --value=sysadmin@example.com
```
To ensure better reliability, `croncape` sends the emails using:
- `project-id@cron.noreply.platformsh.site` as the sender address (`project-id+branch@cron.noreply.platformsh.site` for non-main environments)
- the provided [Platform.sh SMTP service](https://docs.platform.sh/guides/symfony/environment-variables.md#emails), even if you define your own `MAILER_*` environment variables
To use a custom SMTP and/or custom sender address, follow these steps:
1. To specify a sender address, define a [`MAILFROM` environment variable](https://docs.platform.sh/guides/symfony/environment-variables.md#symfony-environment-variables).
2. Define the mandatory [environment variables to use your own email service](https://docs.platform.sh/guides/symfony/environment-variables.md#emails).
Note that only SMTP connections are supported.
3. To disable the provided SMTP service, run `symfony cloud:env:info enable_smtp false`.
**Note**:
To use ``croncape``, SMTP must be enabled on the environment, where the [PLATFORM_SMTP_HOST](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) environment variable is accessible.
This variable is available, and SMTP enabled, by default on all production environments.
This is not the case for preview (non-production) environments, where it must be enabled with the command ``symfony cloud:env:info enable_smtp true``.
### Continous Observability with Blackfire
[Blackfire.io](https://docs.platform.sh/increase-observability/integrate-observability/blackfire.md) is the recommended solution
for monitoring and profiling web sites and apps.
Blackfire works seamlessly with any app built with Symfony.
Blackfire PHP SDK provides the following [integrations with
Symfony](https://blackfire.io/docs/php/integrations/symfony/index):
- [Symfony HTTPClient](https://blackfire.io/docs/php/integrations/symfony/http-client)
- [Symfony Messenger](https://blackfire.io/docs/php/integrations/symfony/messenger)
- [Symfony CLI Commands Monitoring](https://blackfire.io/docs/php/integrations/symfony/cli-commands-monitoring)
- [Symfony Functional Tests Production](https://blackfire.io/docs/php/integrations/symfony/functional-tests)
A `.blackfire.yaml` file is provided within the [Symfony Templates](https://github.com/symfonycorp/platformsh-symfony-template/blob/7.2/.blackfire.yaml)
to help you bootstrap the writing of custom [performance tests](https://blackfire.io/docs/testing-cookbooks/index)
and automated [builds](https://blackfire.io/docs/builds-cookbooks/index).
### Local development
When you develop a Symfony project, a significant amount of work takes place
locally rather than on an active Platform.sh environment. You want to ensure
that the process of local development is as close as possible to a deployed
environment.
You can achieve this through various approaches. For example, you can use
Symfony Server with tethered data
To do so, when testing changes locally, you can connect your locally running
Symfony Server to service containers on an active Platform.sh environment.
This methodology has several advantages:
- It avoids installing anything on your local machine but PHP;
- It ensures that you are using the same versions of all services on your local
machine and in production.
**Warning**:
Never use this method on the **main** environment as changes made on your local
machine will impact production data.
##### Before you begin
You need:
- A local copy of the repository for a project running on Platform.sh.
You can clone an integrated source repository and set the remote branch.
To do so, run ``symfony cloud:project:set-remote
``.
- The [Symfony CLI](https://symfony.com/download)
##### 1. Start your Symfony Server
To start your [Symfony
Server](https://symfony.com/doc/current/setup/symfony_server.html) locally and
display your Symfony app, run the following command:
```bash
symfony server:start -d
symfony open:local
```
This starts the Symfony Server and opens the app in your local browser.
##### 2. Create the tethered connection
1. Create a new environment off of production:
```bash
symfony branch new-feature main
```
2. Open an SSH tunnel to the new environment's services:
```bash
symfony tunnel:open
````
This command returns the addresses for SSH tunnels to all of your services:
```bash
symfony tunnel:open
SSH tunnel opened to rediscache at: redis://127.0.0.1:30000
SSH tunnel opened to database at: pgsql://main:main@127.0.0.1:30001/main
Logs are written to: /Users/acmeUser/.platformsh/tunnels.log
List tunnels with: symfony tunnels
View tunnel details with: symfony tunnel:info
Close tunnels with: symfony tunnel:close
Save encoded tunnel details to the PLATFORM_RELATIONSHIPS variable using:
export PLATFORM_RELATIONSHIPS="$(symfony tunnel:info --encode)"
```
3. To expose Platform.sh services to your Symfony app, run the following
command:
```bash
symfony var:expose-from-tunnel
```
This automatically configures your local Symfony app to use all your
remote Platform.sh services (remote database, remote Redis component, etc.).
To check that you're now using remote data and components from Platform.sh,
reload your local app within your browser.
4. When you've finished your work,
close the tunnels to your services by running the following command:
```bash
symfony var:expose-from-tunnel --off
symfony tunnel:close --all -y
```
### FAQ
##### Why is `DATABASE_URL` not defined during the build hook?
During the build hook, services are not available to avoid breaking the
application that is still live. That is why the Symfony integration does not
expose environment variables during the build hook.
The `cache:clear` command does not need to connect to the database by default,
except if you are using the Doctrine ORM and the database engine version is not
set in your configuration.
The version information can be set in your `.env` file or in the
`doctrine.yaml` configuration file. The only important pieces of information there are
the database engine and the version; everything else will be ignored.
Note that the environment variables are available in the deploy hook.
##### How can I access my application logs?
To display the application log file (`/var/log/app.log` file), run the following command:
```bash
symfony log app --tail
```
All the log messages generated by your app are sent to this `app.log` file.
This includes language errors such as PHP errors, warnings, notices,
as well as uncaught exceptions.
The file also contains your application logs if you log on `stderr`.
Note that Platform.sh manages the `app.log` file for you.
This is to prevent disks from getting filled and using very fast local drives instead of slower network disks.
Make sure your apps always output their logs to `stderr`.
If you use Monolog, add the following configuration to your `config/packages/prod/monolog.yaml` file:
```gitignore
--- a/config/packages/prod/monolog.yaml
+++ b/config/packages/prod/monolog.yaml
@@ -11,7 +11,7 @@ monolog:
members: [nested, buffer]
nested:
type: stream
- path: "%kernel.logs_dir%/%kernel.environment%.log"
+ path: php://stderr
level: debug
buffer:
type: buffer
```
**Warning**:
If you log deprecations, make sure you **also** log them on ``stderr``.
##### What's this "Oops! An Error Occurred" message about?
The *Oops! An Error Occurred* message comes from your app and is automatically generated based on the Symfony error template.
###### The server returned a "500 Internal Server Error"

If your app's working as expected locally but you see the previous error message on Platform.sh,
it usually means you have a configuration error or a missing dependency.
To fix this issue, search your application logs.
They likely contain an error message describing the root cause:
```bash
symfony logs all
[app] [14-Aug-2020 10:52:27 UTC] [critical] Uncaught PHP Exception Exception: [...]
[app]
[php.access] 2020-08-14T10:52:27Z GET 500 2.386 ms 2048 kB 419.11% /
[access] 78.247.136.119 - - [14/Aug/2020:10:52:27 +0000] "GET / HTTP/1.1" 500 843 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36"
```
If the error occurs on a preview environment,
or on the main environment of a non-production project,
you can also enable Symfony's dev/debug mode to inspect the cause of the error:
```bash
# Enable debug mode
symfony env:debug
# Disable debug mode
symfony env:debug --off
```
###### The server returned a "404 Not Found"
By default, new Symfony apps come without controllers, which means there's no homepage to show.
As a result, when you run your project locally, the following welcome page is displayed:

But when you run your project on Platform.sh, the following error is displayed instead:

This is because Platform.sh runs in production mode, leading Symfony to show a generic 404 error.
To fix this issue, [create your first Symfony page](https://symfony.com/doc/current/page_creation.md).
If you've already created a custom homepage, make sure you perform the following actions:
1. Commit all your files.
2. Run the `symfony deploy` command and check that the deployment is successful.
##### Other issues
For other issues unrelated to Symfony, see [Troubleshoot development](https://docs.platform.sh/development/troubleshoot.md).
### Deploy Laravel on Platform.sh
[Laravel](https://laravel.com) is an open-source PHP Framework.
To get Laravel running on Platform.sh, you have two potential starting places:
- You already have a Laravel site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic Laravel site.
- Use a ready-made [Laravel template](https://github.com/platformsh-templates/laravel).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Laravel template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure Laravel](https://docs.platform.sh/guides/laravel/deploy/configure.md)
#### Configure Laravel for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml && touch .platform.app.yaml
```
Now that you've added these files to your project,
configure each one for Laravel in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Laravel requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
```yaml {location=".platform.app.yaml"}
# This file describes an application. You can have multiple applications
# in the same project.
# The name of this app. Must be unique within a project.
name: app
# The type of the application to build.
type: php:8.0
dependencies:
php:
composer/composer: '^2'
runtime:
extensions:
- redis
# - blackfire # https://docs.platform.sh/integrations/observability/blackfire.
build:
flavor: composer
variables:
env:
N_PREFIX: /app/.global
# The hooks that will be performed when the package is deployed.
hooks:
build: |
set -e
# install a specific NodeJS version https://github.com/platformsh/snippets/
# -v requested version
# -y install Yarn
# curl -fsS https://raw.githubusercontent.com/platformsh/snippets/main/src/install_node.sh | { bash /dev/fd/3 -v 17.5 -y; } 3<&0
# uncomment next line to build assets deploying
# npm install && npm run production
deploy: |
set -e
php artisan optimize:clear
php artisan optimize
php artisan view:cache
php artisan migrate --force
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
relationships:
database: "db:mysql"
rediscache: "cache:redis"
redissession: "cache:redis"
# The size of the persistent disk of the application (in MB).
disk: 2048
# The mounts that will be performed when the package is deployed.
mounts:
"storage/app/public":
source: local
source_path: "public"
"storage/framework/views":
source: local
source_path: "views"
"storage/framework/sessions":
source: local
source_path: "sessions"
"storage/framework/cache":
source: local
source_path: "cache"
"storage/logs":
source: local
source_path: "logs"
"bootstrap/cache":
source: local
source_path: "cache"
"/.config":
source: local
source_path: "config"
# The configuration of app when it is exposed to the web.
web:
locations:
"/":
root: "public"
index:
- index.php
allow: true
passthru: "/index.php"
"/storage":
root: "storage/app/public"
scripts: false
# Note that use of workers require a Medium plan or larger.
workers:
queue:
size: S
commands:
# To minimize leakage, the queue worker will stop every hour
# and get restarted automatically.
start: |
php artisan queue:work --max-time=3600
# set the worker's disk to the minimum amount
disk: 256
scheduler:
size: S
commands:
start: php artisan schedule:work
# set the worker's disk to the minimum amount
disk: 256
source:
operations:
auto-update:
command: |
curl -fsS https://raw.githubusercontent.com/platformsh/source-operations/main/setup.sh | { bash /dev/fd/3 sop-autoupdate; } 3<&0
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure to use those services once they're enabled.
Each service entry has a name (`db` and `cache` in the example)
and a `type` that specifies the service and version to use.
Services that store persistent data have a `disk` key, to specify the amount of storage.
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Laravel app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://www.{default}/":
type: upstream
upstream: "app:http"
"https://{default}/":
type: redirect
to: "https://www.{default}/"
```
Now that you have Laravel configured, connect it with Laravel Bridge.
#### Laravel Bridge
Connect your Laravel-based app to Platform.sh with the `platformsh/laravel-bridge` library.
Laravel expects all configuration to come in through environment variables with specific names in a specific format.
Platform.sh provides configuration information as environment variables in a different specific format.
This library handles mapping the Platform.sh variables to the format Laravel expects for common values.
###### Usage
Require this package using Composer.
When Composer's autoload is included, this library is activated and the environment variables set.
``` bash
composer require platformsh/laravel-bridge
```
Make sure to clear the cache on relevant Platform.sh environments afterwards.
``` bash
php artisan optimize:clear
```
###### What is mapped
* If a Platform.sh relationship named `database` is defined,
it is taken as an SQL database and mapped to the `DB_*` environment variables for Laravel.
* If a Platform.sh relationship named `rediscache` is defined,
it is mapped to the `REDIS_*` environment variables for Laravel.
The `CACHE_DRIVER` variable is also set to `redis` to activate it automatically.
* If a Platform.sh relationship named `redissession` is defined,
the `SESSION_DRIVER` is set to `redis` and the `REDIS_*` variables set based on that relationship.
NOTE: This means you _*must*_ set 2 relationships to the same Redis service and endpoint,
as Laravel reuses the same backend connection.
* The Laravel `APP_KEY` is set based on the `PLATFORM_PROJECT_ENTROPY` variable,
which is provided for exactly this purpose.
* The Laravel `APP_URL` variable is set based on the current route, when possible.
* The `SESSION_SECURE_COOKIE` variable is set to `true` if it's not already defined.
A Platform.sh environment is by default encrypted-always,
so there's no reason to allow unencrypted cookies.
Overwrite this by setting the Platform.sh variable `env:SESSION_SECURE_COOKIE` to 0.
* The `MAIL_DRIVER`, `MAIL_HOST`, and `MAIL_PORT` variables are set
to support sending email through the Platform.sh mail gateway.
The `MAIL_ENCRYPTION` value is also set to `0` to disable TLS,
as it isn't needed or supported within Platform.sh's network.
Note that doing so is only supported on Laravel 6.0.4 and later.
On earlier versions, you *must* manually modify `mail.php` and set `encryption` to `null`:
```php
'encryption' => null,
```
###### Common environment variables not set
Laravel provides reasonable defaults for many environment variables already
and this library doesn't override those.
Customize them by setting a Platform.sh variable named `env:ENV_NAME`.
(Note the `env:` prefix.)
The variables you are most likely to want to override are:
* `env:APP_NAME`: The human-friendly name of the app.
* `env:APP_ENV`: Whether the app is in `production` or `development` mode.
* `env:APP_DEBUG`: Set `true` to enable verbose error messages.
Now that your Laravel app is connected to Platform.sh, deploy it to see it in action.
#### Workers, cron jobs, and task scheduling
**Note**:
The use of workers requires a [Medium plan](https://docs.platform.sh/administration/pricing.md#multiple-apps-in-a-single-project)
or greater.
Laravel offers a very convenient and flexible way of scheduling tasks. A large set of [helper functions](https://laravel.com/docs/scheduling#schedule-frequency-options) help you schedule commands and jobs.
Once the scheduled tasks are defined, they need to be effectively executed at the right time and pace.
The recommended way is a cron configuration entry running the `artisan schedule:run` command schedule for every minute.
However, on Platform.sh the [minimum time between cron jobs](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#cron-job-timing)
depends on your plan. Task scheduling may then be contradicted by the cron minimum frequency. Schedules outside the
specified cron frequency are ignored and the related tasks aren't triggered.
Due to this conflict, we suggest utilizing [workers](https://docs.platform.sh/create-apps/workers.md) to run both the scheduler and the queue
systems (the [Laravel template](https://github.com/platformsh-templates/laravel) utilizes this method). In order to have
enough resources to support these workers as well as services (e.g. MariaDB, Redis, etc), a
**[Medium plan](https://docs.platform.sh/administration/pricing.md#multiple-apps-in-a-single-project) _or greater_ is required**.
To use workers to handle scheduling and queues add the following to your .platform.app.yaml file:
```yaml {location=".platform.app.yaml"}
workers:
queue:
size: S
commands:
# To minimize leakage, the queue worker will stop every hour
# and get restarted automatically.
start: |
php artisan queue:work --max-time=3600
disk: 256
scheduler:
size: S
commands:
start: php artisan schedule:work
disk: 256
```
**Note**:
By default, [workers inherit all top level properties](https://docs.platform.sh/create-apps/workers.md#inheritance) from the parent application.
You may need to override certain properties in the worker configuration above depending on your application.
#### Continous observability with Blackfire
[Blackfire.io](https://docs.platform.sh/increase-observability/integrate-observability/blackfire.md) is the recommended solution for monitoring and profiling web sites and applications. Blackfire works seamlessly with any application built with Laravel, like any PHP application.
For advanced cases, the Blackfire PHP SDK provides the following integrations with Laravel:
- [Laravel Artisan](https://blackfire.io/docs/php/integrations/laravel/artisan)
- [Laravel Horizon and other queue services](https://blackfire.io/docs/php/integrations/laravel/horizon)
- [Laravel Tests](https://blackfire.io/docs/php/integrations/laravel/tests)
A `.blackfire.yaml` file is provided within the [Laravel Template](https://github.com/platformsh-templates/laravel/blob/master/.blackfire.yaml) to help you bootstrap the writing of custom [performance tests](https://blackfire.io/docs/testing-cookbooks/index) and automated [builds](https://blackfire.io/docs/builds-cookbooks/index).
#### Laravel Octane
[Laravel Octane](https://laravel.com/docs/octane) aims at improving the performance of Laravel applications by serving them using high-powered application servers, including [Swoole](https://github.com/swoole/swoole-src), [Open Swoole](https://openswoole.com/), and [RoadRunner](https://roadrunner.dev/).
**Note**:
Laravel Octane requires PHP 8.0+.
###### Install
Install the PHP extension for Swoole or Open Swoole during the build.
Take advantage of an [installation script](https://raw.githubusercontent.com/platformsh/snippets/main/src/install_swoole.sh).
You need to pass 2 parameters:
* Which Swoole project to use: `openswoole` or `swoole`
* Which version to install
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -e
...
curl -fsS https://raw.githubusercontent.com/platformsh/snippets/main/src/install_swoole.sh | { bash /dev/fd/3 openswoole 4.11.0 ; } 3<&0
```
###### Use
Require Laravel Octane using Composer.
``` bash
composer require laravel/octane
```
Then make sure to clear the cache on all relevant Platform.sh environments.
``` bash
php artisan optimize:clear
```
Override the default web server with a [custom start command](https://docs.platform.sh/languages/php.md#alternate-start-commands).
Octane should listen on a TCP socket.
```yaml {location=".platform.app.yaml"}
web:
upstream:
socket_family: tcp
protocol: http
commands:
start: php artisan octane:start --server=swoole --host=0.0.0.0 --port=$PORT
locations:
"/":
passthru: true
scripts: false
allow: false
```
#### Deploy Laravel
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your user files to your local `files/user` directory and your public files to `files/public`
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount src/main/resources/files/user --source ./files/user
platform mount:upload --mount src/main/resources/files/public --source ./files/public
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
Go forth and deploy (even on Friday)!
[Back](https://docs.platform.sh/guides/laravel/deploy/octane.md)
### Run a Laravel app on your local machine
Platform.sh provides support for locally running a Laravel app
that has been deployed on Platform.sh, including its services.
Once you've downloaded the code of the Laravel app you deployed on Platform.sh,
you can make changes to the project without pushing to Platform.sh each time to test them.
You can build your app locally using the Platform.sh CLI,
even when the app functionality depends on a number of services.
You can run your Laravel app locally with all of its services
by following the steps for your chosen development platform:
#### Develop locally with DDEV
[DDEV](https://ddev.com/) is a tool for local PHP development environments based on Docker containers.
To learn more about how to run your Laravel app in a local DDEV-managed environment,
see the [official integration documentation](https://ddev.readthedocs.io/en/stable/users/providers/platform/).
#### Develop locally with Lando
[Lando](https://lando.dev/) is a development tool based on Docker containers,
which dramatically simplifies local development.
To learn more about how to run your Laravel app in a local Lando-managed environment,
see the [official integration documentation](https://docs.lando.dev/platformsh/).
### Deploy TYPO3 on Platform.sh
TYPO3 is an Open Source Enterprise PHP-based CMS framework. The recommended way to deploy TYPO3 on Platform.sh is by using Composer, the PHP package management suite.
This guide assumes you are using the well-supported Composer flavor of TYPO3.
**Note**:
If you have a TYPO3 site that’s not using Composer,
there’s a useful guide in the TYPO3 documentation for [migrating a TYPO3 project to composer](https://docs.typo3.org/m/typo3/guide-installation/master/en-us/MigrateToComposer/Index.md).
To get TYPO3 running on Platform.sh, you have two potential starting places:
- You already have a [Composer-flavored TYPO3](https://github.com/TYPO3/TYPO3.CMS.BaseDistribution) site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic [Composer-flavored TYPO3](https://github.com/TYPO3/TYPO3.CMS.BaseDistribution) site.
See an example for doing this under initializing a project.
- Use a ready-made [TYPO3 template](https://github.com/platformsh-templates/typo3).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a TYPO3 template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
If you don’t have code, create a new TYPO3 project from scratch.
The following commands create a brand new TYPO3 project using Composer.
```bash {}
composer create-project typo3/cms-base-distribution ^10
cd
git init
git add . && git commit -m "Init TYPO3 from upstream."
```
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/typo3/deploy/configure.md)
#### Configure TYPO3 for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml && touch .platform.app.yaml
```
Now that you've added these files to your project,
configure each one for TYPO3 in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why TYPO3 requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
Note that the command ``php vendor/bin/typo3cms install:generatepackagestate`` is run during the build hook.
The command ensures all installed extensions are enabled.
```yaml {location=".platform.app.yaml"}
# This file describes an application. You can have multiple applications
# in the same project.
#
# See https://docs.platform.sh/configuration/app.html
# The name of this app. Must be unique within a project.
name: app
# The runtime the application uses.
type: php:7.4
dependencies:
php:
composer/composer: '^2'
runtime:
# Enable the redis extension so TYPO3 can communicate with the Redis cache.
extensions:
- redis
# Composer build tasks run prior to build hook, which runs
# composer --no-ansi --no-interaction install --no-progress --prefer-dist --optimize-autoloader
# if composer.json is detected.
build:
flavor: composer
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
#
# NOTE: Be sure to update database and Redis configuration in `public/typo3conf/PlatformshConfiguration.php`
# if you rename the relationships here.
relationships:
# MariaDB/MySQL will then be accessible to the app from 'database' relationship.
# The service name `db` must match the top-level attribute in `.platform/services.yaml`.
database: 'db:mysql'
# Redis will then be accessible to the app from 'rediscache' relationship.
# The service name `cache` must match the top-level attribute in `.platform/services.yaml`.
rediscache: 'cache:redis'
# The configuration of app when it is exposed to the web.
web:
# How the application container responds to incoming requests.
locations:
# All requests not otherwise specified follow these rules.
'/':
# The folder from which to serve static assets, for this location.
# This is a filesystem path, relative to the application root.
root: 'public'
# Redirect any incoming request to TYPO3's front controller.
passthru: '/index.php'
# File to consider first when serving requests for a directory.
index:
- 'index.php'
# Deny access to all static files, except those specifically allowed below.
allow: false
# Rules for specific URI patterns.
rules:
# Allow access to common static files.
'\.(jpe?g|png|gif|svgz?|css|js|map|ico|bmp|eot|woff2?|otf|ttf)$':
allow: true
'^/robots\.txt$':
allow: true
'^/sitemap\.xml$':
allow: true
# Default Storage location where TYPO3 expects media resources to be located.
# Writable at runtime with the mount `public/fileadmin`.
'/fileadmin':
root: 'public/fileadmin'
# Do not execute PHP scripts from the writeable mount.
scripts: false
allow: true
passthru: '/index.php'
# Directory for temporary files that should be publicly available (e.g. generated images).
# Writable at runtime with the mount `publi/typo3temp`.
'/typo3temp/assets':
root: 'public/typo3temp/assets'
# Do not execute PHP scripts from the writeable mount.
scripts: false
allow: true
passthru: '/index.php'
# Local TYPO3 installation settings.
'/typo3conf/LocalConfiguration.php':
allow: false
# Additional TYPO3 installation settings.
'/typo3conf/AdditionalConfiguration.php':
allow: false
# The size of the persistent disk of the application (in MB).
disk: 2048
# The 'mounts' describe writable, persistent filesystem mounts in the application.
mounts:
# Directory for temporary files. It contains subdirectories (see below) for
# temporary files of extensions and TYPO3 components.
"public/typo3temp":
source: local
source_path: "typo3temp"
# Default Storage location where TYPO3 expects media resources to be located.
"public/fileadmin":
source: local
source_path: "fileadmin"
# Contains system files, like caches, logs, sessions
"var":
source: local
source_path: "var"
# The hooks that will be performed when the package is deployed.
hooks:
# The build hook runs after Composer to finish preparing up your code.
# No services are available but the disk is writeable.
build: |
# Exit hook immediately if a command exits with a non-zero status.
set -e
# Start the installation with no interaction or extension setup, using `SetupConfiguration.yaml`.
if [ ! -f var/platformsh.installed ]; then
php vendor/bin/typo3cms install:setup --install-steps-config=src/SetupConfiguration.yaml --no-interaction --skip-extension-setup
fi;
# Generates the `PackageStates.php` file from the `composer.json` configuration
php vendor/bin/typo3cms install:generatepackagestates
# Enable the install tool for 60mins after deployment.
touch public/typo3conf/ENABLE_INSTALL_TOOL
# Keep the checked-in LocalConfiguration available, but make the actual file writable later-on
# by creating a symlink which will be accesible below.
if [ -f public/typo3conf/LocalConfiguration.php ]; then
mv public/typo3conf/LocalConfiguration.php public/typo3conf/LocalConfiguration.FromSource.php
ln -sf ../../var/LocalConfiguration.php public/typo3conf/LocalConfiguration.php
fi;
# Clean up the FIRST_INSTALL file, that was created.
if [ -f public/FIRST_INSTALL ]; then
rm public/FIRST_INSTALL
fi;
# initial activation of Introduction package will fail if it is unable to write to this images directory.
# if it exists, we'll move its contents out to a temp space, remove the original, and symlink to a writable mount
if [ -d public/typo3conf/ext/introduction/Initialisation/Files/images/ ]; then
if [ ! -d imagestemp ]; then
# create our temp images directory
mkdir -p imagestemp
# copy the image files out of the real location into our temp space
cp -r public/typo3conf/ext/introduction/Initialisation/Files/images/. imagestemp/
fi
#now create the symlink for the images
#remove the original directory
rm -rf public/typo3conf/ext/introduction/Initialisation/Files/images/
# now create a symlink
ln -sf "$PLATFORM_APP_DIR/var/images" public/typo3conf/ext/introduction/Initialisation/Files/images
fi
# The deploy hook runs after your application has been deployed and started.
# Code cannot be modified at this point but the database is available.
# The site is not accepting requests while this script runs so keep it
# fast.
deploy: |
# Exit hook immediately if a command exits with a non-zero status.
set -e
# if the images location existed in the build hook, it was converted to a symlink. we now to need to make sure
# the target of the symlink exists, and then rsync any new files to the writable location
if [ -L public/typo3conf/ext/introduction/Initialisation/Files/images ]; then
#make sure our images directory exists in var mount
if [ ! -d var/images ]; then
mkdir -p var/images
echo "This directory is symlinked to public/typo3conf/ext/introduction/Initialisation/Files/images/. Do not delete." >> var/images/readme.txt
fi
#rsync any new files from imagestemp into var/images
rsync -a --ignore-existing imagestemp/ var/images
fi
# Set TYPO3 site defaults on first deploy.
if [ ! -f var/platformsh.installed ]; then
# Copy the created LocalConfiguration into the writable location.
cp public/typo3conf/LocalConfiguration.FromSource.php var/LocalConfiguration.php
# On first install, create an inital admin user with a default password.
# *CHANGE THIS VALUE IMMEDIATELY AFTER INSTALLATION*
php vendor/bin/typo3cms install:setup \
--install-steps-config=src/SetupDatabase.yaml \
--site-setup-type=no \
\
--admin-user-name=admin \
--admin-password=password \
--skip-extension-setup \
--no-interaction
# Sets up all extensions that are marked as active in the system.
php vendor/bin/typo3cms extension:setupactive || true
# Create file that indicates first deploy and installation has been completed.
touch var/platformsh.installed
fi;
crons:
# Run TYPO3's Scheduler tasks every 5 minutes.
typo3:
spec: "*/5 * * * *"
commands:
start: "vendor/bin/typo3 scheduler:run"
source:
operations:
auto-update:
command: |
curl -fsS https://raw.githubusercontent.com/platformsh/source-operations/main/setup.sh | { bash /dev/fd/3 sop-autoupdate; } 3<&0
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
We recommend the latest [MariaDB](https://docs.platform.sh/add-services/mysql.md) version for TYPO3,
although you can also use Oracle MySQL or [PostgreSQL](https://docs.platform.sh/add-services/postgresql.md) if you prefer.
We also strongly recommend using [Redis](https://docs.platform.sh/add-services/redis.md) for TYPO3 caching.
Our TYPO3 template comes [pre-configured to use Redis](https://github.com/platformsh-templates/typo3#user-content-customizations) for caching.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure TYPO3 to use those services once they're enabled.
Each service entry has a name (`db` and `cache` in the example)
and a `type` that specifies the service and version to use.
Services that store persistent data have a `disk` key, to specify the amount of storage.
```yaml {location=".platform/services.yaml"}
# This file describes an application's services. You can define as many services as your
# application requires, subject to your plan's resource restrictions.
#
# See https://docs.platform.sh/configuration/services.html.
# MariaDB/MySQL 10.4 service with 2048MB of allocated disk.
# The service name `db` is used in defining the `database` relationship in the
# `.platform.app.yaml` file.
#
# See https://docs.platform.sh/configuration/services/mysql.html.
db:
type: mysql:10.4
disk: 2048
# Redis 5.0 service definition.
# The service name `cache` is used in defining the `rediscache` relationship in the
# `.platform.app.yaml` file.
#
# See https://docs.platform.sh/configuration/services/redis.html.
cache:
type: redis:5.0
```
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
Generally, you want the user session cookie, which is included in the example for TYPO3.
You may need to add other cookies depending on what additional modules you have installed.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a TYPO3 app:
```bash {location=".platform/routes.yaml"}
# This file describes an application's routes. You can define as many routes as your
# application requires.
#
# See https://docs.platform.sh/configuration/routes.html
# URL template for the main route, where `{default}` is replaced by
# the Platform.sh generated environment URL or the configured domain.
"https://{default}/":
# This route serves an application (upstream).
type: upstream
# Defines the upstream according to the form `:http`,
# where the `name` attribute from `.platform.app.yaml` is used.
upstream: "app:http"
# Optional route identifier; constant across all environments.
#
# For TYPO3, the id "main" is used within `public/typo3conf/PlatformshConfig.php`
# to set the `base` attribute for the site (in `config/sites/main/config.yaml`) from the
# Platform.sh environment variable `PLATFORM_ROUTES`.
id: "main"
# HTTP cache configuration.
cache:
# Enabled (default `true`, but only if `cache` attribute is unspecified).
enabled: true
# List of allowed cookie names, all others are ignored.
cookies:
# Used to identify a backend session when Backend User logged in.
- 'be_typo_user'
# Used to identify session ID when logged into TYPO3 Frontend.
- 'fe_typo_user'
# Default PHP session cookie.
- 'PHPSESSID'
# Validates sessions for System Maintenance Area.
- 'Typo3InstallTool'
```
#### Customize TYPO3 for Platform.sh
Now that your code contains all of the configuration to deploy on Platform.sh,
it’s time to make your TYPO3 site itself ready to run on a Platform.sh environment.
There are a number of additional steps that are either required or recommended,
depending on how well you want to optimize your site.
###### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
The following examples use it, so install it through Composer if you haven't already.
```bash
composer require platformsh/config-reader
```
###### Avoiding deadlock with the Local Page Error Handler
A default TYPO3 installation has a risk of deadlocks when run on low-worker PHP-FPM configurations.
Specifically, TYPO3 handles 403 and 404 error pages by issuing a full HTTP request back to itself with no timeout,
which can lead to process starvation.
There are two required steps to avoid this problem.
First, you need to install the [Local Page Error Handler](https://extensions.typo3.org/extension/pxa_lpeh/) extension for TYPO3 with the command:
```bash
composer require pixelant/pxa-lpeh
```
Second, you need to add a timeout that sets an HTTP timeout of at least 3 seconds instead of the default several minutes to a new `public/typo3conf/PlatformshConfiguration.php`.
You can see this line in context of the full file in the [configuration](#environment) section below.
```php
` subdirectories.
For the purposes of this guide, you need to set the `base` attribute to an environment variable called `PLATFORM_ROUTES_MAIN`.
You can also add the definition to your existing `baseVariant` attribute for production if desired.
```yaml
# TYPO3 Site Handling configuration YAML.
#
# See https://docs.typo3.org/m/typo3/reference-coreapi/9.5/en-us/ApiOverview/SiteHandling/Basics.html.
rootPageId: 1
# The base domain used to run the TYPO3 site. Here, the environment variable `PLATFORM_ROUTES_MAIN` set in
# `public/typo3/conf/PlatformshConfiguration.php` is used.
base: '%env(PLATFORM_ROUTES_MAIN)%'
# Site's available languages configuration.
#
# See https://docs.typo3.org/m/typo3/reference-coreapi/9.5/en-us/ApiOverview/SiteHandling/AddLanguages.html#sitehandling-addinglanguages
languages:
-
languageId: '0'
title: English
navigationTitle: English
base: '/'
locale: en_US.UTF8
iso-639-1: en
hreflang: en-US
direction: ltr
typo3Language: default
flag: us
enabled: true
-
languageId: '2'
title: German
navigationTitle: Deutsch
base: '/de/'
locale: de_DE.UTF8
iso-639-1: de
hreflang: de-DE
direction: ltr
typo3Language: de
flag: de
fallbackType: fallback
fallbacks: '0'
enabled: true
-
languageId: '1'
title: Dansk
navigationTitle: Dansk
base: '/da/'
locale: da_DK.UTF-8
iso-639-1: da
hreflang: da-DK
direction: ltr
typo3Language: default
flag: dk
fallbackType: fallback
fallbacks: '0'
enabled: true
# Configuration for how to handle error codes for the TYPO3 site.
#
# See https://docs.typo3.org/m/typo3/reference-coreapi/9.5/en-us/ApiOverview/SiteHandling/Basics.html.
errorHandling:
-
errorCode: '404'
errorHandler: Page
errorContentSource: 't3://page?uid=5'
# Environment-specific `base` configuration.
#
# See https://docs.typo3.org/m/typo3/reference-coreapi/9.5/en-us/ApiOverview/SiteHandling/BaseVariants.html.
baseVariants: { }
# Adding static routes for the TYPO3 site.
#
# See https://docs.typo3.org/m/typo3/reference-coreapi/9.5/en-us/ApiOverview/SiteHandling/StaticRoutes.html#sitehandling-staticroutes.
routes:
-
route: robots.txt
type: staticText
content: "User-agent: *\r\nDisallow: /typo3/"
```
You define this environment variable in the next section,
but its purpose is to retrieve the root domain
(since you haven't yet registered a domain name on the Platform.sh project,
this is a hashed placeholder domain generated from the environment)
from the environment variable `PLATFORM_ROUTES`.
**Note**:
The above ``base`` configuration only includes the production case (running on Platform.sh)
or at least exporting a ``PLATFORM_ROUTES_MAIN`` environment variable to match during local development.
Alternatively, you can place the above definition within a ``baseVariant`` definition for the production environment
alongside another development environment ``condition`` for local.
```yaml {}
baseVariants:
-
base: '%env(VIRTUAL_HOST)%'
condition: 'applicationContext == "Development/local"'
-
base: '%env(PLATFORM_ROUTES_MAIN)%'
condition: 'applicationContext == "Production"'
```
###### Environment
Finally, you can start using the Platform.sh Configuration Reader library
to starting reading from the environment from within your application.
In a `public/typo3conf/PlatformshConfiguration.php` file, you can use the library to:
- Verify the deployment is occurring on a Platform.sh project (`if (!$platformConfig->isValidPlatform())`)
- Verify that it's not running during build,
when services aren't yet available (`if ($platformConfig->inBuild())`)
- Set the `PLATFORM_ROUTES_MAIN` environment variable used in `config/sites/main/config.yaml`)
- Configure TYPO3's database (`TYPO3_CONF_VARS.DB.Connections.Default`) using credentials from the `database` relationship
(`$databaseConfig = $platformConfig->credentials('database')`)
- Configure TYPO3's `cacheConfigurations` to use Redis via your `rediscache` relationship
- Configure the HTTP timeout to 3 seconds
to avoid the PHP-FPM-related [deadlock described above](#avoiding-deadlock-with-the-local-page-error-handler).
```php
isValidPlatform()) {
return;
}
// Ensures script does not run during builds, when relationships
// are not available.
if ($platformConfig->inBuild()) {
return;
}
// Workaround to set the proper env variable for the main route (found in config/sites/main/config.yaml)
// Relies on the `id: "main"` configuration set in `.platform/routes.yaml`.
putenv('PLATFORM_ROUTES_MAIN=' . $platformConfig->getRoute('main')['url']);
// Configure the database for `doctrine-dbal` for TYPO3 based on the Platform.sh relationships.
//
// See https://docs.typo3.org/m/typo3/reference-coreapi/9.5/en-us/ApiOverview/Database/Configuration/Index.html.
//
// These lines depend on the database relationship being named `database`. If updating the name to
// something else below, be sure to update `.platform.app.yaml` to match.
if ($platformConfig->hasRelationship('database')) {
$databaseConfig = $platformConfig->credentials('database');
$GLOBALS['TYPO3_CONF_VARS']['DB']['Connections']['Default']['driver'] = 'mysqli';
$GLOBALS['TYPO3_CONF_VARS']['DB']['Connections']['Default']['host'] = $databaseConfig['host'];
$GLOBALS['TYPO3_CONF_VARS']['DB']['Connections']['Default']['port'] = $databaseConfig['port'];
$GLOBALS['TYPO3_CONF_VARS']['DB']['Connections']['Default']['dbname'] = $databaseConfig['path'];
$GLOBALS['TYPO3_CONF_VARS']['DB']['Connections']['Default']['user'] = $databaseConfig['username'];
$GLOBALS['TYPO3_CONF_VARS']['DB']['Connections']['Default']['password'] = $databaseConfig['password'];
}
// Configure Redis as the cache backend if available. These lines depend on the Redis relationship
// being named `rediscache`. If updating the name to something else below, be sure to update `.platform.app.yaml` to match.
if ($platformConfig->hasRelationship('rediscache')) {
$redisConfig = $platformConfig->credentials('rediscache');
$redisHost = $redisConfig['host'];
$redisPort = $redisConfig['port'];
$list = [
'pages' => 3600 * 24 * 7,
'pagesection' => 3600 * 24 * 7,
'rootline' => 3600 * 24 * 7,
'hash' => 3600 * 24 * 7,
'extbase' => 3600 * 24 * 7,
];
$counter = 1;
foreach ($list as $key => $lifetime) {
$GLOBALS['TYPO3_CONF_VARS']['SYS']['caching']['cacheConfigurations'][$key]['backend'] = \TYPO3\CMS\Core\Cache\Backend\RedisBackend::class;
$GLOBALS['TYPO3_CONF_VARS']['SYS']['caching']['cacheConfigurations'][$key]['options'] = [
'database' => $counter++,
'hostname' => $redisHost,
'port' => $redisPort,
'defaultLifetime' => $lifetime
];
}
}
// Ensure that HTTP requests have a timeout set, to avoid sites locking up due to slow
// outgoing HTTP requests.
$GLOBALS['TYPO3_CONF_VARS']['HTTP']['timeout'] = 3;
// Add additional Platform.sh-specific configuration here, such as a search backend.
```
Then include the `require_once()` function within your `public/typo3conf/AdditionalConfiguration.php` file to load the Platform.sh-specific configuration into the site if present.
```php
Password to update.
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your user files to your local `files/user` directory and your public files to `files/public`
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount src/main/resources/files/user --source ./files/user
platform mount:upload --mount src/main/resources/files/public --source ./files/public
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
Go forth and Deploy (even on Friday)!
#### Additional resources
###### Adding extensions
All TYPO3 extensions can be installed and managed using Composer. Install them locally to update and commit changes to your `composer-lock.json` file. The build process will download the correct version on the committed `composer.json` and `composer.lock` files, which should be committed to Git.
```bash
composer require friendsoftypo3/headless
```
###### Updating TYPO3 and extensions
Since TYPO3 is fully managed via Composer, you can run `composer update` periodically to get new versions of both TYPO3 and any extensions you have installed via Composer.
Commit the resulting changes to your `composer.lock` file and push again.
The [Composer documentation](https://getcomposer.org/doc/) has more information on options to update individual modules or perform other tasks.
Note that updating modules or core through the TYPO3 backend isn't possible, as the file system is read-only.
All updates should be done through composer to update the lock file, and then pushed to Git.
###### Why are there warnings in the install tool?
The TYPO3 install tool doesn't yet fully understand when you are working on a cloud environment and may warn you that some folders aren't writable.
Don't worry, your TYPO3 installation is fully functional.
[Back](https://docs.platform.sh/guides/typo3/deploy/deploy.md)
### Deploy WordPress on Platform.sh
WordPress is a popular Content Management System written in PHP. The recommended way to deploy WordPress on Platform.sh is by using Composer, the PHP package management suite. The most popular and supported way to do so is with the [John Bloch](https://github.com/johnpbloch/wordpress) Composer fork script. This guide assumes from the beginning that you're migrating a Composer-flavored WordPress repository.
**Note**:
With some caveats, it’s possible to deploy WordPress to Platform.sh without using Composer, [though not recommended](https://docs.platform.sh/guides/wordpress/composer.md). You can consult the [“WordPress without Composer on Platform.sh”](https://docs.platform.sh/guides/wordpress/vanilla.md) guide to set that up, but do consider [upgrading to use Composer](https://docs.platform.sh/guides/wordpress/composer/migrate.md).
To get WordPress running on Platform.sh, you have two potential starting places:
- You already have a [Composer-flavored WordPress](https://github.com/johnpbloch/wordpress) site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic [Composer-flavored WordPress](https://github.com/johnpbloch/wordpress) site.
See an example for doing this under initializing a project.
- Use a ready-made [WordPress template](https://github.com/platformsh-templates/wordpress-composer).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a WordPress template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
**Note**:
All of the examples in this deployment guide use the [wordpress-composer](https://github.com/platformsh-templates/wordpress-composer) template maintained by the Platform.sh team. That template is built using the [John Bloch Composer fork](https://github.com/johnpbloch/wordpress) of WordPress, which is meant to facilitate managing WordPress with Composer, but the template comes with its own assumptions. One is that WordPress core is downloaded by default into a ``wordpress`` subdirectory when installed, but other teams would rather specify another subdirectory along with many more assumptions.
An alternative approach is shown in Platform.sh’s [Bedrock template](https://github.com/platformsh-templates/wordpress-bedrock), which installs core into ``web/wp``, exports environment customization to a separate ``config/environments`` directory, and largely depends on setting environment variables to configure the database. Your are free to follow that template as an example with this guide, though there are slight differences. For its ease of use, the Bedrock approach is often used as a substitute starting point in some of the other WordPress guides in this documentation.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
If you don’t have code, create a new WordPress project from scratch.
The following command creates a brand new WordPress project.
```bash {}
git clone https://github.com/johnpbloch/wordpress && cd wordpress
```
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/wordpress/deploy/configure.md)
#### Configure WordPress for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml && touch .platform.app.yaml
```
Now that you've added these files to your project,
configure each one for WordPress in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why WordPress requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
Notice that the build ``flavor`` is set to ``composer``, which will automatically download WordPress core, as well as your plugins, themes, and dependencies during the build step as defined in your ``composer.json`` file. Since WordPress’s caching and uploads require write access at runtime, they’ve been given corresponding [mounts](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts) defined for them at the bottom of the file. MariaDB is accessible to WordPress internally at ``database.internal`` thanks to the relationship definition ``database``. The [WordPress CLI](https://packagist.org/packages/wp-cli/wp-cli) is added as a build dependency, but we will still need to add some additional dependencies in the next step so that it can be used by the application and via SSH.
```yaml {location=".platform.app.yaml"}
# Complete list of all available properties: https://docs.platform.sh/create-apps/app-reference.html
# A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated
# with the app.
name: app
# The runtime the application uses.
# Complete list of available runtimes: https://docs.platform.sh/create-apps/app-reference.html#types
type: 'php:8.1'
# Specifies a default set of build tasks to run. Flavors are language-specific.
# More information: https://docs.platform.sh/create-apps/app-reference.html#build
build:
flavor: composer
# Installs global dependencies as part of the build process. They’re independent of your app’s dependencies and
# are available in the PATH during the build process and in the runtime environment. They’re installed before
# the build hook runs using a package manager for the language.
# More information: https://docs.platform.sh/create-apps/app-reference.html#dependencies
dependencies:
php:
composer/composer: '^2'
wp-cli/wp-cli-bundle: "^2.4.0"
# Hooks allow you to customize your code/environment as the project moves through the build and deploy stages
# More info:
hooks:
# The build hook is run after any build flavor.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#build-hook
build: |
set -e
# Copy manually-provided plugins into the plugins directory.
# This allows manually-provided and composer-provided plugins to coexist.
rsync -a plugins/* wordpress/wp-content/plugins/
# The deploy hook is run after the app container has been started, but before it has started accepting requests.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#deploy-hook
deploy: |
# Flushes the object cache which might have changed between current production and newly deployed changes
wp cache flush
# Runs the WordPress database update procedure in case core is being updated with the newly deployed changes
wp core update-db
# Runs all cron events that are due now and may have come due during the build+deploy procedure
wp cron event run --due-now
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
# More information: https://docs.platform.sh/create-apps/app-reference.html#relationships
relationships:
database: "db:mysql"
# The web key configures the web server running in front of your app.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web
web:
# Each key in locations is a path on your site with a leading /.
# More information: https://docs.platform.sh/create-apps/app-reference.html#locations
locations:
"/":
# The public directory of the app, relative to its root.
root: "wordpress"
# The front-controller script to send non-static requests to.
passthru: "/index.php"
# Wordpress has multiple roots (wp-admin) so the following is required
index:
- "index.php"
# The number of seconds whitelisted (static) content should be cached.
expires: 600
scripts: true
allow: true
# The key of each item in rules is a regular expression to match paths exactly. If an incoming request
# matches the rule, it’s handled by the properties under the rule, overriding any conflicting rules from the
# rest of the locations properties.
# More information: https://docs.platform.sh/create-apps/app-reference.html#rules
rules:
^/composer\.json:
allow: false
^/license\.txt$:
allow: false
^/readme\.html$:
allow: false
"/wp-content/cache":
root: "wordpress/wp-content/cache"
scripts: false
allow: false
"/wp-content/uploads":
root: "wordpress/wp-content/uploads"
scripts: false
allow: false
rules:
# Allow access to common static files.
'(?:http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a WordPress app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
# More information: https://docs.platform.sh/define-routes.html
"https://{default}/":
type: upstream
upstream: "app:http"
# Platform.sh supports HTTP caching at the server level. Caching is enabled by default, but is only applied to
# GET and HEAD requests.
# More information: https://docs.platform.sh/define-routes/cache.html
cache:
# All possible cache configuration options: https://docs.platform.sh/define-routes/cache.html#cache-configuration-properties
enabled: true
# Base the cache on the session cookies. Ignore all other cookies.
cookies:
- '/^wordpress_logged_in_/'
- '/^wordpress_sec_/'
- 'wordpress_test_cookie'
- '/^wp-settings-/'
- '/^wp-postpass/'
- '/^wp-resetpass-/'
# A basic redirect definition
# More information: https://docs.platform.sh/define-routes.html#basic-redirect-definition
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
#### Customize WordPress for Platform.sh
Now that your code contains all of the configuration to deploy on Platform.sh, it’s time to make your WordPress site itself ready to run on a Platform.sh environment.
###### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
The following examples use it, so install it through Composer if you haven't already.
```bash
composer require platformsh/config-reader
```
###### `wp-config.php`
With the Configuration Reader library installed, add or update a `wp-config.php` file in the root of your repository to match the code below. In this file, the library's `Config` object is used to:
- Retrieve connection credentials for MariaDB through the `database` relationship to configure the WordPress database. This will set up the database automatically and avoid you having to set the connection yourself during the installer.
- Use the project's [routes](https://docs.platform.sh/define-routes.md) to set `WP_HOME` and `WP_SITEURL` settings.
- Set all of WordPress's security and authentication keys to the Platform.sh-provided `PLATFORM_PROJECT_ENTROPY` - a hashed variable specific to your repository consistent across environments.
Many other WordPress settings are pre-defined in this file for you, so consult the inline comments for more information.
```php
isValidPlatform()) {
if ($config->hasRelationship('database')) {
// This is where we get the relationships of our application dynamically
// from Platform.sh.
// Avoid PHP notices on CLI requests.
if (php_sapi_name() === 'cli') {
session_save_path("/tmp");
}
// Get the database credentials
$credentials = $config->credentials('database');
// We are using the first relationship called "database" found in your
// relationships. Note that you can call this relationship as you wish
// in your `.platform.app.yaml` file, but 'database' is a good name.
define( 'DB_NAME', $credentials['path']);
define( 'DB_USER', $credentials['username']);
define( 'DB_PASSWORD', $credentials['password']);
define( 'DB_HOST', $credentials['host']);
define( 'DB_CHARSET', 'utf8' );
define( 'DB_COLLATE', '' );
// Check whether a route is defined for this application in the Platform.sh
// routes. Use it as the site hostname if so (it is not ideal to trust HTTP_HOST).
if ($config->routes()) {
$routes = $config->routes();
foreach ($routes as $url => $route) {
if ($route['type'] === 'upstream' && $route['upstream'] === $config->applicationName) {
// Pick the first hostname, or the first HTTPS hostname if one exists.
$host = parse_url($url, PHP_URL_HOST);
$scheme = parse_url($url, PHP_URL_SCHEME);
if ($host !== false && (!isset($site_host) || ($site_scheme === 'http' && $scheme === 'https'))) {
$site_host = $host;
$site_scheme = $scheme ?: 'http';
}
}
}
}
// Debug mode should be disabled on Platform.sh. Set this constant to true
// in a wp-config-local.php file to skip this setting on local development.
if (!defined( 'WP_DEBUG' )) {
define( 'WP_DEBUG', false );
}
// Set all of the necessary keys to unique values, based on the Platform.sh
// entropy value.
if ($config->projectEntropy) {
$keys = [
'AUTH_KEY',
'SECURE_AUTH_KEY',
'LOGGED_IN_KEY',
'NONCE_KEY',
'AUTH_SALT',
'SECURE_AUTH_SALT',
'LOGGED_IN_SALT',
'NONCE_SALT',
];
$entropy = $config->projectEntropy;
foreach ($keys as $key) {
if (!defined($key)) {
define( $key, $entropy . $key );
}
}
}
}
}
else {
// Local configuration file should be in project root.
if (file_exists(dirname(__FILE__, 2) . '/wp-config-local.php')) {
include(dirname(__FILE__, 2) . '/wp-config-local.php');
}
}
// Do not put a slash "/" at the end.
// https://codex.wordpress.org/Editing_wp-config.php#WP_HOME
define( 'WP_HOME', $site_scheme . '://' . $site_host );
// Do not put a slash "/" at the end.
// https://codex.wordpress.org/Editing_wp-config.php#WP_SITEURL
define( 'WP_SITEURL', WP_HOME );
define( 'WP_CONTENT_DIR', dirname( __FILE__ ) . '/wp-content' );
define( 'WP_CONTENT_URL', WP_HOME . '/wp-content' );
// Disable WordPress from running automatic updates
define( 'WP_AUTO_UPDATE_CORE', false );
// Since you can have multiple installations in one database, you need a unique
// prefix.
$table_prefix = 'wp_';
// Default PHP settings.
ini_set('session.gc_probability', 1);
ini_set('session.gc_divisor', 100);
ini_set('session.gc_maxlifetime', 200000);
ini_set('session.cookie_lifetime', 2000000);
ini_set('pcre.backtrack_limit', 200000);
ini_set('pcre.recursion_limit', 200000);
/** Absolute path to the WordPress directory. */
if ( ! defined( 'ABSPATH' ) ) {
define( 'ABSPATH', dirname( __FILE__ ) . '/' );
}
/** Sets up WordPress vars and included files. */
require_once(ABSPATH . 'wp-settings.php');
```
###### Setting up Composer
Through this guide you will set up your WordPress repository to install everything during it's build using Composer. That includes themes, plugins, and even WordPress Core itself. Any new plugins you want to use or migrate from your existing application can be committed as dependencies using Composer, but there are a few changes we need to make to the `composer.json` file to prepare it for the final Platform.sh environment.
First, the John Bloch script has a default `wordpress` installation directory, so the `composer.json` file needs to know that all new themes and plugins have a destination within that subdirectory.
```json
"extra": {
"installer-paths": {
"wordpress/wp-content/plugins/{$name}": [
"type:wordpress-plugin"
],
"wordpress/wp-content/themes/{$name}": [
"type:wordpress-theme"
],
"wordpress/wp-content/mu-plugins/{$name}": [
"type:wordpress-muplugin"
]
}
}
```
Next, having placed `wp-config.php` in the root of your repository, you need to add a `post-install-cmd` to move the file into `wordpress` after `composer install` has finished.
```json
"scripts": {
"copywpconfig": [
"cp wp-config.php wordpress/"
],
"post-install-cmd": "@copywpconfig"
},
```
Since you're likely using [WPPackagist](https://wpackagist.org/) to download plugins and themes with Composer, you also need to add `wpackagist.org` as a repository in `composer.json`.
```json
"repositories": [
{
"type": "composer",
"url": "https://wpackagist.org"
}
]
```
Lastly, to prevent committing WordPress Core when it is installed via Composer, and to otherwise setup your local development environment, make sure that your `.gitignore` file includes everything in `wordpress`, as [shown in the template](https://github.com/platformsh-templates/wordpress-composer/blob/master/.gitignore).
###### Additional packages
Finally, install `wp-cli` and `psy/psysh` using Composer.
With these packages included, the WordPress CLI is available when you SSH into the application container.
```bash
composer require wp-cli/wp-cli-bundle psy/psysh --ignore-platform-reqs
```
If you've installed the WordPress CLI as a dependency as in the [previous step](https://docs.platform.sh/guides/wordpress/deploy/configure.md#configure-apps-in-platformappyaml),
you can use it directly.
(As long as you have only `wp-cli/wp-cli-bundle` as a dependency and not `wp-cli/wp-cli`.)
Otherwise, commit the changes from composer and push.
Then you can use the WordPress CLI within an application container from the `vendor` directory:
```bash
./vendor/bin/wp plugin list
```
If you receive an error stating `This doesn't seem to be a WordPress installation.`,
try providing the `--path` flag and point to your WordPress install path.
#### Deploy WordPress
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your uploaded files to your local `wordpress/wp-content/uploads` directory
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount wordpress/wp-content/uploads --source ./wordpress/wp-content/uploads
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
Go forth and Deploy (even on Friday)!
#### Additional resources
###### Adding plugins and themes without Composer
As previously mentioned, Composer is strongly recommended,
but it's possible to use some non-Composer plugins and themes in your site,
provided that they don't require write access at runtime.
In your build hook, include:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
rsync -a plugins/* wordpress/wp-content/plugins/
```
Here, you can commit plugins to the repository in a `plugins` subdirectory,
which are placed into the WordPress installation during the build.
It's assumed that these packages stick to best practices and don't write to the file system at runtime and when enabling them.
You can get around this issue by defining a [mount](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts) where a plugin requires write access,
but you need to remember that the contents at that mount location are wiped when deployment begins,
so you need to copy and re-copy accordingly.
###### Adding public plugins and themes via Composer
Adding a plugin or theme from WPPackagist is the same as downloading a package through Composer:
```bash
# Plugin
$ composer require wpackagist-plugin/cache-control
# Theme
$ composer require wpackagist-theme/neve
```
This updates your `composer.json` and `composer.lock` files.
Once you push the change to Platform.sh, the package is downloaded during the WordPress build.
All that's left is to sign in to the administration dashboard on your deployed site
and enable plugins and themes from the Plugins and Appearance settings, respectively.
###### Set up a WooCommerce site
Platform.sh maintains a [WooCommerce template](https://github.com/platformsh-templates/wordpress-woocommerce)
that you can deploy quickly from the button in its README,
but using Composer you can quickly install WooCommerce yourself:
```bash
composer require woocommerce/woocommerce
```
Push those changes on a new environment and configure your store through the administration panel.
###### Adding private plugins and themes via Composer
If your plugins aren't accessible from WPPackagist or Packagist, but are still valid packages,
you can use them in your project by defining local `repositories` for them in your `composer.json` file.
```json
"repositories":[
{
"type":"composer",
"url":"https://wpackagist.org"
},
{
"type": "path",
"url": "custom/themes/*",
"options": {
"symlink": false
}
},
{
"type": "path",
"url": "custom/plugins/*",
"options": {
"symlink": false
}
}
]
```
In the snippet above, other packages can still be downloaded from WPPackagist,
but now two custom `path` repositories have been defined from `/custom/[themes|plugins]` locally.
Adding packages from these sources then only requires `composer require author/custom_plugin`
to ensure that the plugin at `/custom/plugin/author/custom_plugin` is installed by Platform.sh when WordPress is built.
###### Updating WordPress, plugins, and themes
Your WordPress site is fully managed by Composer,
which means so are updates to WordPress core itself.
Run `composer update` periodically to get new versions of WordPress core, as well as any plugins or themes your have installed.
Commit the resulting changes to your `composer.lock` file and push again to Platform.sh.
The [Composer documentation](https://getcomposer.org/doc/) has more information on options to update individual modules or perform other tasks.
Note that updating modules or core through the WordPress UI isn't possible, as the file system is read-only.
All updates should be done through Composer to update the lock file, and then push to Git.
###### Local development with Lando
[Lando](https://github.com/lando/lando) is a local development tool.
Lando can read your Platform.sh configuration files for WordPress
and produce an approximately equivalent configuration using Docker
See a guide on [using Lando with Platform.sh](https://docs.platform.sh/development/local/lando.md).
Templates come configured for use already with a base [Landofile](https://docs.lando.dev/landofile/),
as in the following example.
It can be helpful getting started with Lando without the need to have a project on Platform.sh.
This file sets up good defaults for Lando and Platform.sh-configured codebases,
most notably through the `recipe` attribute.
This Landofile is also where you can configure access to tools
that would normally be available within a Platform.sh app container (such as the WordPress CLI)
and that you also want to access locally.
You can replicate this file or follow the guide on [using Lando with Platform.sh](https://docs.platform.sh/development/local/lando.md).
Once you have completed the configuration, you can start your local environment by running:
```bash
lando start
```
[Back](https://docs.platform.sh/guides/wordpress/deploy/deploy.md)
### Why you should manage WordPress with Composer
Using Composer isn't traditionally the norm for WordPress development, but it is strongly recommended when deploying on Platform.sh. This guide is intended to provide an overview of why using Composer - including adding modules and themes locally as packages, as well as updating WordPress itself - is recommended.
##### Why use Composer
Like any other application, your WordPress site is most secure when you can ensure repeatable builds and committable updates for both your code and its dependencies. This is a priority at Platform.sh, and that's why you can control your infrastructure in the same way. Your infrastructure is committed through a set of configuration files that specify which version of PHP and MariaDB you want to use, because that's the best way to ensure that your project remains reproducible when developing new features.
WordPress core, as well as its themes and plugins, should ideally work the same way, but very often this isn't the case. WordPress's administration panel provides one-click buttons to update all of these components when they're out of date, or otherwise expects write access to the file system to make configuration changes at runtime. Developing this way has its consequences, however.
First off, you aren't always going to have write access to the file system at runtime (which is the case for Platform.sh), so depending on this mechanism for updates and configuration changes is entirely restricted for many hosting solutions. On the other hand, if you *do* have write access at runtime where you're hosting currently, installing a new module or theme presents a nontrivial security risk when the source is unknown.
But, perhaps most importantly, updating WordPress at runtime decouples the state of your site from the code in your repository. A colleague working on a new feature on their local clone of the project could very well be a full major version behind the live site, introducing bugs with unknown (and more importantly, untested) consequences completely as a result of this workflow.
##### Advantages of using Composer
Given the points raised above, managing your WordPress site with Composer has clear advantages. First, it allows you to explicitly define your dependencies in a committed file (`composer.lock`). This lock file is generated from a more descriptive list of dependency constraints (`composer.json`) when your dependencies are installed, and it becomes a part of your project's commit history. From then on, any new branch will work from the identical collection of dependencies, down to the exact commit hash. It doesn't matter at that point who contributes to the project or even where it is deployed - it's the same code for everyone everywhere.
Composer also removes the need to commit lots of external code to your repository. In the case of WordPress, *not* using Composer often requires you to commit all of the code for a theme, and even for WordPress core itself, to your own project. Besides making the repository unnecessarily large and slow to clone, updating these copies becomes a juggling act that nobody needs to deal with.
Through Composer you can add and update dependencies to your project, and then lock their exact versions so that each new branch gets that same update. Had the update been performed on the deployed site at runtime, you would have to remember to `git pull` first.
###### Adding themes and modules with Composer
Through Composer, themes and modules are then treated the same as any other PHP dependency. You can, for example, add the [Neve](https://wordpress.org/themes/neve/) theme to your project by using `composer require`
```bash
composer require wpackagist-theme/neve
```
or add the [cache-control](https://wordpress.org/plugins/cache-control-by-cacholong/) plugin:
```bash
composer require wpackagist-plugin/cache-control
```
These commands will add the packages to your `composer.json` file, and then lock the exact version to `composer.lock`. Just push those updates to your project on Platform.sh, and enable them through the administration panel as you would normally.
**Note**:
Typically, Composer dependencies install to a ``vendor`` directory in the project root, but themes and plugins need to install to ``wp-content`` instead. There is an ``installer-paths`` attribute that is added to ``composer.json`` to accomplish this, which is explained in more detail in the [How to Deploy WordPress on Platform.sh](https://docs.platform.sh/guides/wordpress/deploy.md) guide (which uses Composer from the start), as well as the [How to update your WordPress site to use Composer](https://docs.platform.sh/guides/wordpress/composer/migrate.md) guide.
For more information, see the following Platform.sh community post: [How to install custom/private WordPress plugins and themes with Composer](https://support.platform.sh/hc/en-us/community/posts/16439636140306).
###### Installing WordPress core with Composer
In the same way, using Composer makes it unnecessary for you to commit all of WordPress to your repository, since you can add it as a dependency. There are several ways to do this (i.e. [Bedrock](https://github.com/platformsh-templates/wordpress-bedrock)) depending on how many assumptions you want to be made for your configuration and project structure. The simplest one uses the [John Bloch Composer fork](https://github.com/johnpbloch/wordpress) to add an installer to your builds for WordPress:
```bash
composer require johnpbloch/wordpress-core-installer
composer require johnpbloch/wordpress-core
```
###### Updates
Now that WordPress core, your themes and your plugins have been added as dependencies with Composer, updates become easier.
```bash
composer update
```
This command will update everything in your project locally, after which you can push to Platform.sh on a new environment. After you are satisfied with the changes merge into your production site.
##### Resources
Platform.sh has written several guides for WordPress alongside the Composer recommendation:
- [How to Deploy WordPress on Platform.sh](https://docs.platform.sh/guides/wordpress/deploy/_index.md): From here, you can create a Composer-based version of WordPress from scratch and deploy to Platform.sh.
- [How to update your WordPress site to use Composer](https://docs.platform.sh/guides/wordpress/composer/migrate.md): This guide will take you through the steps of updating your fully committed *vanilla* WordPress repository into one that uses Composer and deploy it to Platform.sh.
- [Redis](https://docs.platform.sh/guides/wordpress/redis.md): This guide will show you how to add a Redis container to your configuration and add it to your deployed WordPress site.
- [How to Deploy WordPress without Composer on Platform.sh](https://docs.platform.sh/guides/wordpress/vanilla/_index.md): If you do not want to switch to using Composer and you are willing to work around some of Platform.sh runtime constraints, this guide will show you how to deploy a fully committed *vanilla* WordPress site to Platform.sh
#### Upgrade your WordPress site to use Composer
Composer helps you declare, manage, and install all the dependencies needed to run your project.
It allows you to make your WordPress site [more stable, more secure, and easier to maintain](https://docs.platform.sh/guides/wordpress/composer.md).
With Composer, you don't need to commit all of WordPress core, its themes and plugins to your project's Git repository.
You also don't need to manage any of these elements as Git submodules.
###### Before you begin
To update your WordPress site to use Composer, check that:
- You already have a [vanilla version of WordPress installed locally](https://docs.platform.sh/guides/wordpress/vanilla.md).
- Your project has been set up for deployment on Platform.sh.
If you don't have Platform.sh configuration files in your repository,
[deploy WordPress without Composer](https://docs.platform.sh/guides/wordpress/vanilla.md) before upgrading to a Composer-based site.
- You have [downloaded and installed Composer](https://getcomposer.org/download/).
###### 1. Install WordPress with Composer
To install WordPress with Composer, complete the following steps:
1. Switch to a new Git branch.
To safely make changes to your repository and Platform.sh environment, run the following command:
```bash
$ git checkout -b composer
```
2. Turn your repository into a Composer repository.
To use Composer, you need:
- A `composer.json` file listing all the dependencies needed for your project to run
(WordPress itself, its plugins, and its themes).
- A `composer.lock` file listing the exact versions of all the dependencies installed on your project.
Generated from the `composer.json` file, it ensures repeatable builds until you update.
To turn your repository into a Composer repository and generate those files, run the following command:
```bash
$ composer init
```
When prompted, set metadata attributes for your project,
such as its name and license information.
When you get to the part about installing dependencies, type `no`,
as you add them in step 5.
3. Clean up WordPress core.
If you've been managing WordPress and its dependencies as Git submodules, [remove the submodules](https://docs.platform.sh/development/submodules.md#removing-submodules).
Otherwise, your existing installation of WordPress core is assumed to be in a subdirectory of your repository (often named `wordpress`).
For Composer to manage WordPress, remove this subdirectory:
```bash
$ rm -rf wordpress
```
Then, at the end of your existing `.gitignore` file,
add the content of Platform.sh’s [template `.gitignore` file](https://github.com/platformsh-templates/wordpress-composer/blob/master/.gitignore).
This adds the `wordpress` subdirectory to the resulting `.gitignore` file.
This way, after Composer reinstalls WordPress, the `wordpress` subdirectory is ignored in commits.
Now remove WordPress from the repository:
```bash
$ git rm -rf --cached wordpress && rm -rf wordpress
$ git add . && git commit -m "Remove WordPress"
```
4. Launch the installation of WordPress with Composer.
Now that you have made your WordPress site into a Composer project, you can download packages via Composer.
To download WordPress itself, run the following commands:
```bash
$ composer require johnpbloch/wordpress-core-installer
$ composer require johnpbloch/wordpress-core
```
The two dependencies are now listed in your `composer.json` file:
```json
{
"require": {
"johnpbloch/wordpress-core-installer": "^2.0",
"johnpbloch/wordpress-core": "^6.0"
}
}
```
5. Complete the installation:
```bash
$ composer install
```
Composer reinstalls WordPress into the `wordpress` subdirectory.
###### 2. Install WordPress themes and plugins with Composer
Just like with WordPress core, you can install themes and plugins with the `composer require` command.
To do so, complete the following steps:
1. Configure the WPackagist repository.
By default, when you download dependencies using Composer, you retrieve them through [Packagist](https://packagist.org),
which is the primary Composer repository for public PHP packages.
Some themes and plugins for WordPress are also on Packagist,
but most of them are accessible through a similar service specific to WordPress called [WPackagist](https://wpackagist.org).
To allow Composer to download packages from the WPackagist repository, run the following command:
```bash
$ composer config repositories.wppackagist composer https://wpackagist.org
```
WPackagist is now listed in your `composer.json` file:
```json
{
"repositories": {
"wppackagist": {
"type": "composer",
"url": "https://wpackagist.org"
}
}
}
```
2. Optional: Configure theme and plugin destination.
By default, Composer places installed dependencies in a `vendor` subdirectory.
You can configure a different destination for your themes and plugins.
For instance, to install them into `wp-content`, add the following configuration:
```json {location="composer.json"}
"extra": {
"installer-paths": {
"wordpress/wp-content/plugins/{$name}": [
"type:wordpress-plugin"
],
"wordpress/wp-content/themes/{$name}": [
"type:wordpress-theme"
],
"wordpress/wp-content/mu-plugins/{$name}": [
"type:wordpress-muplugin"
]
}
}
```
Make sure you add the new destination subdirectories to your `.gitignore` file.
After inspecting package metadata, Composer now installs plugins with a `type` of `wordpress-plugin` into `wordpress/wp-content/plugins/` instead of `vendor`.
And similarly for themes and must-use plugins.
3. Launch the installation of plugins and themes with Composer.
To search for themes and plugins in [WPackagist](https://wpackagist.org) and install them through Composer, run a `composer require` command:
```bash
# Plugin
$ composer require wpackagist-plugin/wordpress-seo
# Theme
$ composer require wpackagist-theme/hueman
```
The two dependencies are now listed in your `composer.json` file.
4. Complete the installation:
```bash
$ composer install
````
Each dependency is now installed.
###### 3. Deploy to Platform.sh
Switching to a Composer-based installation doesn't require any modifications to the Platform.sh configuration files
created when [you deployed your vanilla version](https://docs.platform.sh/guides/wordpress/vanilla.md).
Make sure that your project contains those three files.
You can then commit all your changes
and deploy your new Composer-based WordPress site to Platform.sh:
```bash
git add . && git commit -m "Composerify plugins and themes."
git push platform composer
```
###### 4. Update your Composer-based WordPress site
####### Perform a standard update with Composer
Updating WordPress, your themes and plugins becomes a lot simpler with Composer.
When a new version becomes available, create a new branch and launch the update:
```bash
git checkout -b updates
composer update
```
####### Automate your updates with a source operation
**Tier availability**
This feature is available for
**Elite and Enterprise** customers. [Compare the tiers](https://platform.sh/pricing/) on our pricing page, or [contact our sales team](https://platform.sh/contact/) for more information.
[Source operations](https://docs.platform.sh/create-apps/source-operations.md) allow you to automate the maintenance of your Composer-based WordPress site.
For instance, you can [update all the dependencies in your project with a single command](https://docs.platform.sh/learn/tutorials/dependency-updates.md).
### How to Deploy WordPress without Composer on Platform.sh
WordPress is a popular Content Management System written in PHP. The recommended way to deploy WordPress on Platform.sh is by using [Composer](https://docs.platform.sh/guides/wordpress/deploy.md), the PHP package management suite. This guide will take you through the steps of setting up "vanilla" WordPress - that is, WordPress not managed through Composer, but rather by either fully committing WordPress, themes, and plugins or defining them with submodules - on Platform.sh. It should be noted that this approach comes with certain limitations based on the way Platform.sh works, and for this reason is [not recommended](https://docs.platform.sh/guides/wordpress/composer.md). Instead, consider using the ["Upgrade to use Composer"](https://docs.platform.sh/guides/wordpress/composer/migrate.md) guide to modify your project into one that uses Composer.
To get WordPress running on Platform.sh, you have two potential starting places:
- You already have a WordPress site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic WordPress site.
See an example for doing this under initializing a project.
- Use a ready-made [WordPress template](https://github.com/platformsh-templates/wordpress-vanilla).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a WordPress template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
If you don’t have code, create a new WordPress project from scratch.
It’s best to place WordPress core into a subdirectory rather than at the project root.
The following commands create a fresh Git repository with WordPress as a subdirectory:
```bash {}
mkdir wordpress-psh && cd wordpress-psh
git clone https://github.com/WordPress/WordPress.git wordpress && rm -rf wordpress/.git
git init
```
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/wordpress/vanilla/configure.md)
#### Configure WordPress for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml && touch .platform.app.yaml
```
Now that you've added these files to your project,
configure each one for WordPress in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why WordPress requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
There are a few things to notice in this file specific to running non-Composer variants of WordPress on Platform.sh. Defined in the ``dependencies`` block, all of the packages needed to run the WordPress CLI in both the application container and via SSH are installed in the first stages of the build process using Composer. Also, the ``web.locations`` block will expose ``wordpress/index.php`` under the primary route.
```yaml {location=".platform.app.yaml"}
# This file describes an application. You can have multiple applications
# in the same project.
# The name of this app. Must be unique within a project.
name: app
# The runtime the application uses.
type: "php:8.1"
dependencies:
php:
wp-cli/wp-cli-bundle: "^2.4"
psy/psysh: "^0.10.4"
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
relationships:
database: "db:mysql"
variables:
php:
session.gc_maxlifetime: '200000'
session.cookie_lifetime: '2000000'
pcre.backtrack_limit: '200000'
pcre.recursion_limit: '200000'
# The configuration of app when it is exposed to the web.
web:
locations:
"/":
# The public directory of the app, relative to its root.
root: "wordpress"
# The front-controller script to send non-static requests to.
passthru: "/index.php"
# Wordpress has multiple roots (wp-admin) so the following is required
index:
- "index.php"
# The number of seconds whitelisted (static) content should be cached.
expires: 600
scripts: true
allow: true
rules:
^/composer\.json:
allow: false
^/license\.txt$:
allow: false
^/readme\.html$:
allow: false
"/wp-content/cache":
root: "wordpress/wp-content/cache"
scripts: false
allow: false
"/wp-content/uploads":
root: "wordpress/wp-content/uploads"
scripts: false
allow: false
rules:
# Allow access to common static files.
'(?:http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a WordPress app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://{default}/":
type: upstream
upstream: "app:http"
cache:
enabled: true
# Base the cache on the session cookies. Ignore all other cookies.
cookies:
- '/^wordpress_logged_in_/'
- '/^wordpress_sec_/'
- 'wordpress_test_cookie'
- '/^wp-settings-/'
- '/^wp-postpass/'
- '/^wp-resetpass-/'
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
[Customize WordPress](https://docs.platform.sh/guides/wordpress/vanilla/customize.md)
#### Customize WordPress for Platform.sh
Deploying WordPress without Composer on Platform.sh isn't recommended,
but should you wish to do so there are a few additional modifications you need to make to your repository.
###### Place WordPress core into a subdirectory
**Note**:
If starting from scratch, you can skip to the section covering [wp-config.php](#wp-configphp) below.
Keeping WordPress core up-to-date is made much easier when it resides in a subdirectory of your repository
and it makes the recommended transition to using Composer simpler.
It also makes defining WordPress as a submodule possible if you choose to do so.
Place all code for WordPress core into a subdirectory called `wordpress`, including your `wp-config.php` file.
**Note**:
You can name the WordPress core subdirectory whatever you would like - the most common being ``wp``, ``web``, and ``wordpress``. ``wordpress`` has been chosen for Platform.sh templates and guides because it is often the default install location for [composer-flavored versions of WordPress](https://docs.platform.sh/guides/wordpress/deploy.md), and naming it ``wordpress`` now in your project will make [migrating to use Composer](https://docs.platform.sh/guides/wordpress/composer/migrate.md) later on straightforward. If naming the directory something other than ``wordpress``, make sure to update the ``web.locations["/"].root`` attribute to match in your ``.platform.app.yaml`` file, as well as any other ``root`` attribute there.
####### Core, themes, and plugins can also be submodules
Platform.sh validates and retrieves submodules in the first stages of its build process,
so it's possible to manage your code entirely this way.
This modifies the update steps from what's listed below,
so visit the [Git submodules](https://docs.platform.sh/development/submodules.md) documentation for more information.
###### `.environment`
Platform.sh provides multiple *environments* for your projects, that can be customized (with different values for staging and development), but that inherit features from the production environment. One clear case where this can be useful is environment variables. Each environment on Platform.sh comes with a set of [pre-defined variables](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) that provide information about the branch you are working on, the application's configuration, and the credentials to connect to each service defined in `.platform/services.yaml`.
Service credentials reside in a base64 encoded JSON object variable called `PLATFORM_RELATIONSHIPS`,
which you can use to define your database connection to the MariaDB container.
To make each property (username, password, and so on) more accessible to `wp-config.php`,
you can use the pre-installed `jq` package to clean the object into individual variables.
```text
# .environment
export DB_NAME=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".database[0].path")
export DB_HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".database[0].host")
export DB_PORT=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".database[0].port")
export DB_USER=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".database[0].username")
export DB_PASSWORD=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".database[0].password")
export WP_HOME=$(echo $PLATFORM_ROUTES | base64 --decode | jq -r 'to_entries[] | select(.value.primary == true) | .key')
export WP_SITEURL="${WP_HOME}wp"
export WP_DEBUG_LOG=/var/log/app.log
if [ "$PLATFORM_ENVIRONMENT_TYPE" != production ] ; then
export WP_ENV='development'
else
export WP_ENV='production'
fi
```
As you can see above, you can define a number of environment-specific or project-wide variable settings in this file
that are applied when deployed on Platform.sh but not locally.
###### `wp-config.php`
Now that your database credentials have been cleaned up and `WP_HOME` defined, you can pull these values into `wp-config.php` to configure WordPress for deployment on a Platform.sh environment.
Below is the `wp-config.php` file from the [WordPress template](https://github.com/platformsh-templates/wordpress-vanilla) using the variables defined in the previous section. Many other WordPress settings are pre-defined in this file for you, so consult the inline comments for more information.
```php
hasRelationship('redis') && extension_loaded('redis')) {
$credentials = $config->credentials('redis');
$redis_server = array(
'host' => $credentials['host'],
'port' => $credentials['port'],
'auth' => $credentials['password'],
);
}
```
wp-config.php
```php {}
hasRelationship('redis') && extension_loaded('redis')) {
$credentials = $config->credentials('redis');
define('WP_REDIS_CLIENT', 'phpredis');
define('WP_REDIS_HOST', $credentials['host']);
define('WP_REDIS_PORT', $credentials['port']);
}
```
These sections set up the parameters the plugins look for to connect to the Redis server.
If you used a different name for the relationship above, change it accordingly.
This code has no impact when run on a local development environment.
Once you have committed the above changes and pushed, you need to activate the plugins.
###### Verifying Redis is running
Run this command in a SSH session in your environment: `platform redis info`.
You should run it before you push all this new code to your repository.
This should give you a baseline of activity on your Redis installation.
There should be very little memory allocated to the Redis cache.
After you push this code, you should run the command and notice that allocated memory starts jumping.
To verify the plugins are working, add a `redis` command to the WP CLI tool.
While in a SSH session in your environment,
you can run `wp help redis` to see the available commands your chosen plugin has added.
### Deploy Gatsby on Platform.sh
[Gatsby](https://www.gatsbyjs.com/) is an open source framework based on React that specializes in generating static websites from a variety of content sources.
To get Gatsby running on Platform.sh, you have two potential starting places:
- You already have a Gatsby site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic Gatsby site.
- Use a ready-made [Gatsby template](https://github.com/platformsh-templates/gatsby).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Gatsby template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/gatsby/deploy/configure.md)
#### Configure Gatsby for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml
```
Now that you've added these files to your project,
configure each one for Gatsby in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Gatsby requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
In the template, ``yarn`` is run during the build hook to install all of Gatsby’s dependencies, and then ``yarn build`` is run to build the site and output to the ``public`` subdirectory. If you would rather use ``npm`` to manage your dependencies, you can:
- delete ``yarn`` from the build hook
- update ``yarn build`` to ``npm run build`` in the build hook
- delete the ``build.flavor`` block, which tells Platform.sh to rely solely on the build hook to define the build process for your project when set to ``none``. By default, Node.js containers run ``npm install`` prior to the build hook, so this block can be removed entirely from the configuration.
- delete the ``dependencies`` block, which includes ``yarn``, since it is no longer needed.
All traffic is then directed to the ``public`` subdirectory once the deployment has completed via the ``web.locations`` section.
```yaml {location=".platform.app.yaml"}
# Complete list of all available properties: https://docs.platform.sh/create-apps/app-reference.html
# A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated
# with the app.
name: 'app'
# The runtime the application uses.
# Complete list of available runtimes: https://docs.platform.sh/create-apps/app-reference.html#types
type: 'nodejs:18'
# The size of the persistent disk of the application (in MB). Minimum value is 128.
disk: 5120
# The web key configures the web server running in front of your app.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web
web:
# Each key in locations is a path on your site with a leading /.
# More information: https://docs.platform.sh/create-apps/app-reference.html#locations
locations:
'/':
# The directory to serve static assets for this location relative to the app’s root directory. Must be an
# actual directory inside the root directory.
root: 'public'
# Files to consider when serving a request for a directory.
index: [ 'index.html' ]
# Whether to allow serving files which don’t match a rule.
allow: true
# Specifies a default set of build tasks to run. Flavors are language-specific.
# More information: https://docs.platform.sh/create-apps/app-reference.html#build
build:
flavor: none
# Installs global dependencies as part of the build process. They’re independent of your app’s dependencies and
# are available in the PATH during the build process and in the runtime environment. They’re installed before
# the build hook runs using a package manager for the language.
# More information: https://docs.platform.sh/create-apps/app-reference.html#dependencies
dependencies:
nodejs:
yarn: "1.22.5"
# Hooks allow you to customize your code/environment as the project moves through the build and deploy stages
# More information: https://docs.platform.sh/create-apps/app-reference.html#hooks
hooks:
# The build hook is run after any build flavor.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#build-hook
build: |
yarn
yarn build
# Information on the app's source code and operations that can be run on it.
# More information: https://docs.platform.sh/create-apps/app-reference.html#source
source:
######################################################################################################################
## ##
## This source operation is part of the Platform.sh process of updating and maintaining our collection of ##
## templates. For more information see https://docs.platform.sh/create-apps/source-operations.html and ##
## https://github.com/platformsh/source-operations ##
## ##
## YOU CAN SAFELY DELETE THIS COMMENT AND THE LINES BENEATH IT ##
## ##
######################################################################################################################
operations:
auto-update:
command: |
curl -fsS https://raw.githubusercontent.com/platformsh/source-operations/main/setup.sh | { bash /dev/fd/3 sop-autoupdate; } 3<&0
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
Gatsby doesn't require services to deploy, so you don't need a `.platform/services.yaml` file for now.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure Gatsby to use those services once they're enabled.
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Gatsby app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
# More information: https://docs.platform.sh/define-routes.html
"https://{default}/":
type: upstream
upstream: "app:http"
```
#### Deploy Gatsby
###### Deployment
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Additional changes
A standard Gatsby site - either one created interactively through npm (`npm init gatsby`) or through a starter such as the [Blog starter](https://github.com/gatsbyjs/gatsby-starter-blog) used in the Platform.sh template - will generate a static site without the use of any external services. If this is your starting point you have all of the configuration necessary to deploy your project, but below are a few modifications that may help you develop your site more efficiently going forward.
####### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
Install the package with your preferred package manager:
```bash
npm install platformsh-config
# Or for Yarn
yarn add platformsh-config
```
Go forth and Deploy (even on Friday)!
#### Additional resources
Platform.sh supports [multi-app configuration](https://docs.platform.sh/create-apps/multi-app.md) on projects - that is, including code for two separate sites that are deployed on their own containers within a single project cluster.
These days, an increasingly common pattern is to decouple content resources from a frontend Gatsby site. Decoupled sites use Gatsby's source plugin ecosystem to pull external content resources into the build, where those resources (a headless CMS, for example) are typically located on a server elsewhere.
Platform.sh's multi-app configuration gets around this, placing both frontend and backend sites on the same server by keeping the code for both sites in the same repository. Gatsby would reside in a subdirectory alongside another that contains the code for the backend resource. For example, a Gatsby site pulling content from a Drupal site could be kept in a single repository that looks like the snippet below:
```bash
.
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── drupal
│ ├──
│ └── .platform.app.yaml
├── gatsby
│ ├──
│ └── .platform.app.yaml
├── CHANGELOG.md
├── LICENSE.md
└── README.md
```
This pattern can be replicated for a number of backend applications, and you can consult the [Gatsby Headless](https://docs.platform.sh/guides/gatsby/headless.md) guide for some common examples.
[Back](https://docs.platform.sh/guides/gatsby/deploy/deploy.md)
### Gatsby multi-app projects
##### Background
A common pattern for Gatsby sites is to decouple services from the main site, pulling in external data at build time. Supported by Gatsby's source plugin ecosystem, data from conventional (or headless) content management systems can be collected into a common [Data Layer](https://www.gatsbyjs.com/docs/reference/graphql-data-layer/), with that CMS typically located on a server elsewhere, and that data then used to fill out content on the frontend.
The location of an external CMS is usually hard coded into Gatsby's configuration, so when you're developing your site every branch points to the same backend resource. Should the location of that resource change, you would need to commit the new URL to update the configuration.
The decoupled pattern can work differently on Platform.sh due to support for [multi-app configuration](https://docs.platform.sh/create-apps/multi-app.md) on your projects. Consider the following project structure:
```bash
.
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── drupal
│ ├──
│ └── .platform.app.yaml
├── gatsby
│ ├──
│ └── .platform.app.yaml
└── README.md
```
Above is the repository structure for a Decoupled Drupal (Gatsby sourcing Drupal content) project on Platform.sh. Here, Gatsby and Drupal reside in their own subdirectories within the same repository. They are deployed to the same project from separate application containers, and from this cluster Gatsby can read data from Drupal internally. Their commit histories are tied together, such that each new pull request environment can test changes to either the frontend or backend freely from the same place.
Drupal is just one example of a backend CMS that can be used with this pattern, and at the bottom of this page are a few additional guides for alternatives that work well on Platform.sh.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Signing up
In each of the backend guides below, there is a "Deploy on Platform.sh" button that will not only deploy the guide's project for you, but also sign you up for a trial account. If you are planning on deploying a template and following along with these guides for greater context, feel free to move onto the next section.
If however you are planning on using the templates and guides to deploy your existing codebase to Platform.sh,
you first need to [register for a trial Platform.sh account](https://auth.api.platform.sh/register).
If you don't want to sign up initially with your e-mail address,
you can sign up using an existing GitHub, Bitbucket, or Google account.
If you choose one of these options, you can set a password for your Platform.sh account later.
After creating an account, you are prompted to create your first project. Since you're providing your own code, use the "Blank project" option. You can give the project a title and choose a region closest to the visitors of your site. You also have the option to select more resources for your project. This is especially important with multi-application projects, so make sure to consult the [**Plan size**](#plan-size) note below for more details.
##### Plan size
There are a few important points you need to keep in mind when deploying this pattern if you have already [deployed Gatsby by itself](https://docs.platform.sh/guides/gatsby/deploy.md) on Platform.sh, which are relevant to each backend example. After following the steps below, you may find that Gatsby fails to bundle assets during its build on projects of the "Development" plan size. This is a factor of both the size and number of Gatsby's dependencies on the frontend, as well as the amount of data being pulled from the backend.
Multi-application projects generally require more resources to run on Platform.sh, and so the trial's default `development` plan may not be enough to run your existing site. You are free to either proceed with a smaller plan to test or increase the resources at this point for the project. Otherwise, it may be best to initially deploy the templates listed in each backend guide to start out, and later modify that project to include your own code with more resources as you get used to developing on Platform.sh.
##### Headless backends
Platform.sh maintains a number of [multi-application templates](https://github.com/platformsh-templates/?q=gatsby&type=&language=) for Gatsby, that generally have very similar configuration changes on the Gatsby side. Below are a few of those written as short guides for different backend content management systems.
#### How to deploy Gatsby with Drupal (Decoupled Drupal) on Platform.sh
Platform.sh maintains a [template](https://github.com/platformsh-templates/gatsby-drupal) that you can quickly deploy, and then use this guide as a reference for the Platform.sh specific changes that have been made to Gatsby and Drupal to make it work. Click the button below to sign up for a free trial account and deploy the project.

###### Shared configuration
Your local clone of the template has the following project structure:
```bash
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── drupal
│ ├── # App code
│ └── .platform.app.yaml
├── gatsby
│ ├── # App code
│ └── .platform.app.yaml
└── README.md
```
From this repository, you deploy a Gatsby app and a Drupal app.
The code for each of them resides in their own directories.
When deploying a single app project [such as Gatsby](https://docs.platform.sh/guides/gatsby/deploy.md),
the repository needs three configuration files that describe its infrastructure, described below in detail.
For [multi-app projects](https://docs.platform.sh/create-apps/multi-app.md),
two of those files remain in the project root and are shared between Gatsby and Drupal.
Each app keeps its own app configuration file (`.platform.app.yaml`) in its subdirectory.
####### Service configuration
This file describes which [service containers](https://docs.platform.sh/add-services.md) (such as a database) your project should include.
Gatsby does not require services to deploy, but Drupal does.
So the following examples shows these service configurations:
```yaml {}
# The services of the project.
#
# Each service listed will be deployed
# to power your Platform.sh project.
db:
type: mariadb:10.4
disk: 2048
cache:
type: redis:5.0
files:
type: network-storage:1.0
disk: 256
```
####### Routes configuration
This [`.platform/routes.yaml`](https://docs.platform.sh/define-routes.md) file defines how requests are handled by Platform.sh.
The following example shows Gatsby being served from the primary domain
and Drupal being accessible from the `backend` subdomain.
```yaml {}
https://api.{default}/:
type: upstream
upstream: "drupal:http"
id: "api"
cache:
enabled: true
cookies: ['/^SS?ESS/', '/^Drupal.visitor/']
https://www.api.{default}/:
type: redirect
to: "https://api.{default}/"
"https://www.{default}/":
type: upstream
upstream: "gatsby:http"
primary: true
"https://{default}/":
type: redirect
to: "https://www.{default}/"
```
###### Drupal
The multi-app template has a single modification to Platform.sh's [standard Drupal template](https://github.com/platformsh-templates/drupal9):
the `name` attribute in Drupal's `.platform/services.yaml` has been updated to `drupal`.
This value is used to define the [relationship between Gatsby and Drupal](#gatsby)
and in the [routes configuration](#routes-configuration).
The only setup required to prepare the backend is to install a few additional modules that will configure the JSON API for consumption. In your Drupal directory, add the following dependencies.
```bash
composer require drupal/gatsby drupal/jsonapi_extras drupal/pathauto
```
The [Pathauto](https://www.drupal.org/project/pathauto) module helps you assign alias paths for each piece of content on your Drupal site that can then be replicated on the frontend Gatsby site. For example, the Drupal alias `/article/some-new-article` is the same path you find that article at on Gatsby.
###### Gatsby
The frontend Gatsby app has a slightly different configuration from the basic [Gatsby deployment](https://docs.platform.sh/guides/gatsby/deploy.md).
Below is the `gatsby/.platform.app.yaml` file that configures the app.
```yaml {}
# The name of this app. Must be unique within a project.
name: gatsby
type: 'nodejs:14'
variables:
env:
NODE_OPTIONS: --max-old-space-size=1536
GENERATED_VARS: 'deploy/platformsh.environment'
size: L
resources:
base_memory: 1024
memory_ratio: 1024
dependencies:
nodejs:
# yarn: "1.22.17"
pm2: "5.2.0"
hooks:
post_deploy: |
# Verify the connection to the backend can be made with those variables.
if [ -f "$GENERATED_VARS" ]; then
# Source environment variables, build the frontend, and start the server.
. $GENERATED_VARS
else
printf "In %s, %s is not available, therefore I could not source" "web:commands:start" "${GENERATED_VARS}"
fi
# Gatsby clean on a RO-filesystem
rm -rf .cache/* && rm -rf public/*
npm run build -- --no-color
web:
commands:
start: |
# npm run serve -- -p $PORT --no-color
if [ -f "$GENERATED_VARS" ]; then
# Source environment variables, build the frontend, and start the server.
. $GENERATED_VARS
else
printf "In %s, %s is not available, therefore I could not source" "web:commands:start" "${GENERATED_VARS}"
fi
APP=$(cat package.json | jq -r '.name')
pm2 start npm --no-daemon --watch --name $APP -- run serve -- -p $PORT --no-color
#pm2 start npm --no-daemon --watch --name $APP -- run develop -- -p $PORT --no-color
# Maybe since we're foregoing the first deploy, yarn start is good enough.
# if [ -f "$GENERATED_VARS" ]; then
# # Source environment variables, build the frontend, and start the server.
# # . $GENERATED_VARS
# npm run clean
# npm run build
# npm run serve
# # APP=$(cat package.json | jq -r '.name')
# # pm2 start npm --no-daemon --watch --name $APP -- preview -- -p $PORT
# else
# # On the first deploy, display next steps page.
# node first_deploy.js
# fi
disk: 512
mounts:
/.cache:
source: local
source_path: 'cache'
/.config:
source: local
source_path: 'config'
/.pm2:
source: local
source_path: 'pm2'
public:
source: local
source_path: 'public'
deploy:
source: service
service: files
source_path: deploy
```
In particular, notice:
- `relationships`
Access to another service or app container in the cluster is given through [`relationships`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#relationships).
In this case, one has been defined to the backend Drupal container using it's `name`.
- `post_deploy`
Platform.sh containers reside in separate build containers at build time,
before their images are moved to the final app container at deploy time.
These build containers are isolated and so Gatsby can't access Drupal during the build hook,
where you would normally run the [`gatsby build` command](https://github.com/platformsh-templates/gatsby/blob/master/.platform.app.yaml#L21).
Drupal isn't available until after the deploy hook.
So the Gatsby build is postponed until the [`post_deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook).
To run `gatsby build` on-demand, or to trigger a rebuild from the backend when content is updated,
define a [runtime operation](https://docs.platform.sh/create-apps/runtime-operations.md#build-your-app-when-using-a-static-site-generator).
- `mounts`
There are consequences to postponing the Gatsby build,
as you don't generally have write access to the container this late in the pipeline.
To allow Gatsby to write to `public`, that directory has been defined as a [mount](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#mounts).
Additionally, there has been a change to Gatsby’s start command,``web.commands.start``. In the generic Gatsby template, the static files in ``public`` are served via the [web.locations](https://github.com/platformsh-templates/gatsby/blob/c764ed717752eacc3c3f3322b7e5415e276d02df/.platform.app.yaml#L29), but that attribute is removed in the file below. Instead, two separate start commands are defined depending on which branch you are developing on. This has been included to support [Live Preview and Incremental Builds](https://www.drupal.org/project/gatsby). It isn’t required, but you can consult the [section below](#live-preview-and-incremental-builds) for more information about enabling it.
You can then modify [gatsby-config.js](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-config/) to read from the backend Drupal container through the ``drupal`` relationship defined above to configure the ``baseUrl`` attribute for ``gatsby-source-drupal``.
This is facilitated by Platform.sh's [Config Reader library](https://github.com/platformsh/config-reader-nodejs).
So be sure to install this to the Gatsby dependencies first when replicating.
When used, Gatsby pulls the information to communicate with the Drupal container *on the current branch*.
Lastly, the Gatsby app itself needs to include [GraphQL queries](https://www.gatsbyjs.com/docs/reference/graphql-data-layer/)
to handle the data coming from Drupal and create content pages.
The most important files in the template you should consult are:
- [`gatsby/gatsby-node.js`](https://github.com/platformsh-templates/gatsby-drupal/blob/master/client/gatsby-node.js)
Dynamically creates individual pages from the data source using Gatsby's [Node API](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-node/). It retrieves all of Drupal's articles (see [post-install below](#deploy-and-post-install)) using the GraphQL query `allNodeArticle`. A page is created (`createPage`) with formatting described by the template file `article.js` below (`component`). A `path` is also defined for each article, in this case using an `alias` you will define within Drupal using the Pathauto module.
- [`gatsby/src/templates/article.js`](https://github.com/platformsh-templates/gatsby-drupal/blob/master/client/src/templates/article.js)
The template file that defines how a single Drupal article should be formatted on Gatsby, retrieving the data from that article using the `nodeArticle` GraphQL query.
- [`gatsby/src/pages/articles.js`](https://github.com/platformsh-templates/gatsby-drupal/blob/master/client/src/components/articlePreview.js)
Generates previews of articles at `/articles` on the Gatsby site using the `allNodeArticle` GraphQL query.
###### Deploy and post-install
When you first deploy the template, the frontend Gatsby site will fail with a 403 error.
Visit the `backend` subdomain of your site and finish the installation of Drupal.
You don't need to set database credentials as they're already provided.
After you have completed the installation, you need to enable the JSON API and Gatsby related modules
and then set up aliases for your articles using ``pathauto``.
For detailed instructions, see the template’s [post-installation instructions](https://github.com/platformsh-templates/gatsby-drupal#user-content-post-install).
Once you've finished, redeploy the project with the CLI command `platform redeploy` to view your Gatsby site,
It's now pulling its content from a backend Drupal container in the same project.
###### Next steps
With Gatsby now deployed and pulling content from a backend Drupal application, there are a few things you may wish to change about your project going forward.
####### Shared application configuration
You can optionally combine the application configuration (`.platform/services.yaml`) for Gatsby
and Drupal into a [single configuration file](https://docs.platform.sh/create-apps/multi-app/project-structure.md#unified-app-configuration).
Like `.platform/services.yaml` and `.platform/routes.yaml`, this file is shared across the project and resides in the `.platform` subdirectory.
You need to explicitly define the source of each application.
####### Multiple content sources
Gatsby supports pulling multiple sources into its build.
This includes external services like Stripe and additional backend CMSs for different sets of content.
As in this example with Drupal,
you can branch off your repository and add an additional directory that contains the codebase for [another backend](https://docs.platform.sh/guides/gatsby/headless.md#headless-backends).
Then add the source plugin for that backend to `gatsby-config.js`.
####### Plan size
As mentioned previously, you should have at least a Medium
plan for your multi-app projects.
This size gives the project enough resources for all of your containers
as well as the memory necessary to actually pull content from Drupal into Gatsby during its build.
Keep in mind that the increased plan size applies only to your production environment,
and not to preview environments (which default to Standard
).
As you continue to work with Gatsby and a backend headless CMS,
you may want to [upsize your preview environments](https://docs.platform.sh/administration/pricing.md#preview-environments).
####### Live preview and incremental builds
If you replicate the `web.commands.start` block in Gatsby's `.platform.app.yaml` file above, you can enable incremental builds on your projects. Once you save an update to a piece of Drupal content on a preview branch, Drupal places a request to a dedicated `/__refresh` endpoint on Gatsby. Since Gatsby is running a development server on this non-production environment, this call causes Gatsby to retrieve content from Drupal once again, resulting in a near instantly updated article on the frontend.
To see how to enable this feature, consult the [template's README](https://github.com/platformsh-templates/gatsby-drupal#user-content-enabling-gatsby-live-preview-manual-configuration).
#### How to deploy Gatsby with Strapi on Platform.sh
Platform.sh maintains a [template](https://github.com/platformsh-templates/gatsby-strapi) that you can quickly deploy, and then use this guide as a reference for the Platform.sh specific changes that have been made to Gatsby and Strapi to make it work. Click the button below to sign up for a free trial account and deploy the project.

###### Shared configuration
Your local clone of the template has the following project structure:
```bash
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── strapi
│ ├── # App code
│ └── .platform.app.yaml
├── gatsby
│ ├── # App code
│ └── .platform.app.yaml
└── README.md
```
From this repository, you deploy a Gatsby app and a Strapi app.
The code for each of them resides in their own directories.
When deploying a single app project [such as Gatsby](https://docs.platform.sh/guides/gatsby/deploy.md),
the repository needs three configuration files that describe its infrastructure, described below in detail.
For [multi-app projects](https://docs.platform.sh/create-apps/multi-app.md),
two of those files remain in the project root and are shared between Gatsby and Strapi.
Each app keeps its own app configuration file (`.platform.app.yaml`) in its subdirectory.
####### Service configuration
This file describes which [service containers](https://docs.platform.sh/add-services.md) (such as a database) your project should include.
Gatsby does not require services to deploy, but Strapi does.
So the following examples shows these service configurations:
```yaml {}
# The services of the project.
#
# Each service listed will be deployed
# to power your Platform.sh project.
dbpostgres:
type: postgresql:12
disk: 256
```
####### Routes configuration
This [`.platform/routes.yaml`](https://docs.platform.sh/define-routes.md) file defines how requests are handled by Platform.sh.
The following example shows Gatsby being served from the primary domain
and Strapi being accessible from the `backend` subdomain.
```yaml {}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://www.{default}/":
type: upstream
upstream: "gatsby:http"
"https://{default}/":
type: redirect
to: "https://www.{default}/"
"https://www.backend.{default}/":
type: upstream
upstream: "strapi:http"
"https://backend.{default}/":
type: redirect
id: 'strapi'
to: "https://www.backend.{default}/"
```
###### Strapi
The multi-app template has a single modification to Platform.sh's [standard Strapi template](https://github.com/platformsh-templates/strapi):
the `name` attribute in Strapi's `.platform/services.yaml` has been updated to `strapi`.
This value is used to define the [relationship between Gatsby and Strapi](#gatsby)
and in the [routes configuration](#routes-configuration).
The only additional setup required to prepare the backend is to install a package that will enable GraphQL on Strapi. In your Strapi directory, add the dependency:
```bash
yarn add strapi-plugin-graphql
```
###### Gatsby
The frontend Gatsby app has a slightly different configuration from the basic [Gatsby deployment](https://docs.platform.sh/guides/gatsby/deploy.md).
Below is the `gatsby/.platform.app.yaml` file that configures the app.
```yaml {}
# .platform.app.yaml
# The name of this application, which must be unique within a project.
name: gatsby
# The type key specifies the language and version for your application.
type: 'nodejs:14'
# The hooks that will be triggered when the package is deployed.
hooks:
# Build hooks can modify the application files on disk but not access any services like databases.
post_deploy: |
npm run build
# The size of the persistent disk of the application (in MB).
disk: 1024
relationships:
strapi: "strapi:http"
# The configuration of the application when it is exposed to the web.
web:
locations:
'/':
# The public directory of the application relative to its root.
root: 'public'
index: ['index.html']
scripts: false
allow: true
mounts:
'/.cache':
source: local
source_path: cache
'/.config':
source: local
source_path: config
'public':
source: local
source_path: public
```
In particular, notice:
- `relationships`
Access to another service or app container in the cluster is given through [`relationships`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#relationships).
In this case, one has been defined to the backend Strapi container using it's `name`.
- `post_deploy`
Platform.sh containers reside in separate build containers at build time,
before their images are moved to the final app container at deploy time.
These build containers are isolated and so Gatsby can't access Strapi during the build hook,
where you would normally run the [`gatsby build` command](https://github.com/platformsh-templates/gatsby/blob/master/.platform.app.yaml#L21).
Strapi isn't available until after the deploy hook.
So the Gatsby build is postponed until the [`post_deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook).
To run `gatsby build` on-demand, or to trigger a rebuild from the backend when content is updated,
define a [runtime operation](https://docs.platform.sh/create-apps/runtime-operations.md#build-your-app-when-using-a-static-site-generator).
- `mounts`
There are consequences to postponing the Gatsby build,
as you don't generally have write access to the container this late in the pipeline.
To allow Gatsby to write to `public`, that directory has been defined as a [mount](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#mounts).
You can then modify [gatsby-config.js](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-config/)
to read from the backend Strapi container through the ``strapi`` relationship defined above
to configure the ``apiURL`` attribute for ``gatsby-source-strapi``.
Note that the source plugin requires that you explicitly define the ``contentTypes`` to retrieve from Strapi.
At this point, you haven’t yet built out the API.
So the ``article`` and ``category`` content types are included for what you need to do [after installing](https://github.com/platformsh-templates/gatsby-strapi#user-content-post-install).
If you’re migrating an existing Strapi repository, adjust these values to fit your current API.
This is facilitated by Platform.sh's [Config Reader library](https://github.com/platformsh/config-reader-nodejs).
So be sure to install this to the Gatsby dependencies first when replicating.
When used, Gatsby pulls the information to communicate with the Strapi container *on the current branch*.
Lastly, the Gatsby app itself needs to include [GraphQL queries](https://www.gatsbyjs.com/docs/reference/graphql-data-layer/)
to handle the data coming from Strapi and create content pages.
The most important files in the template you should consult are:
- [`gatsby/gatsby-node.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/gatsby-node.js)
Dynamically creates individual pages from the data source using Gatsby's [Node API](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-node/). It retrieves all of Strapi's articles and categories (see [post-install below](#deploy-and-post-install)) using the GraphQL queries `allStrapiArticle` and `allStrapiCategory` respectively. For each, a page is created (`createPage`) with an assigned `path` and formatting described by one of the template files below (`component`).
- [`gatsby/src/templates/article.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/src/templates/article.js)
The template file that defines how a single Strapi article should be formatted on Gatsby, retrieving the data from that article using the `strapiArticle` GraphQL query.
- [`gatsby/src/templates/category.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/src/templates/category.js)
The template file that defines how a list of articles that belong to a single Category are formatted by Gatsby. It uses the `Category` query, and then filters a specific category `id` on `allStrapiArticle`.
- [`gatsby/src/pages/index.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/src/pages/index.js)
Retrieves all of Strapi's content to generate a list of articles on the homepage using the `allStrapiArticle` GraphQL query.
###### Deploy and post-install
When you first deploy the template, the frontend Gatsby site will fail with a 403 error.
Visit the `backend` subdomain of your site and finish the installation of Strapi.
You don't need to set database credentials as they're already provided.
After you have deployed, you need to set up Strapi’s Admin Panel and some initial content endpoints for the Gatsby frontend to consume. Create your admin user at the ``backend`` subdomain for Strapi. You can then follow the [template’s post-install instructions](https://github.com/platformsh-templates/gatsby-strapi#user-content-post-install) to setup up some initial ``Article`` and ``Category`` content endpoints. The API you develop there is only accessible by admins by default, so be sure to adjust the permissions to public so Gatsby can access it.
Once you've finished, redeploy the project with the CLI command `platform redeploy` to view your Gatsby site,
It's now pulling its content from a backend Strapi container in the same project.
###### Next steps
With Gatsby now deployed and pulling content from a backend Strapi application, there are a few things you may wish to change about your project going forward.
####### Shared application configuration
You can optionally combine the application configuration (`.platform/services.yaml`) for Gatsby
and Strapi into a [single configuration file](https://docs.platform.sh/create-apps/multi-app/project-structure.md#unified-app-configuration).
Like `.platform/services.yaml` and `.platform/routes.yaml`, this file is shared across the project and resides in the `.platform` subdirectory.
You need to explicitly define the source of each application.
####### Multiple content sources
Gatsby supports pulling multiple sources into its build.
This includes external services like Stripe and additional backend CMSs for different sets of content.
As in this example with Strapi,
you can branch off your repository and add an additional directory that contains the codebase for [another backend](https://docs.platform.sh/guides/gatsby/headless.md#headless-backends).
Then add the source plugin for that backend to `gatsby-config.js`.
####### Plan size
As mentioned previously, you should have at least a Medium
plan for your multi-app projects.
This size gives the project enough resources for all of your containers
as well as the memory necessary to actually pull content from Strapi into Gatsby during its build.
Keep in mind that the increased plan size applies only to your production environment,
and not to preview environments (which default to Standard
).
As you continue to work with Gatsby and a backend headless CMS,
you may want to [upsize your preview environments](https://docs.platform.sh/administration/pricing.md#preview-environments).
#### How to deploy Gatsby with WordPress on Platform.sh
Platform.sh maintains a [template](https://github.com/platformsh-templates/gatsby-wordpress) that you can quickly deploy, and then use this guide as a reference for the Platform.sh specific changes that have been made to Gatsby and WordPress to make it work. Click the button below to sign up for a free trial account and deploy the project.

###### Shared configuration
Your local clone of the template has the following project structure:
```bash
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── wordpress
│ ├── # App code
│ └── .platform.app.yaml
├── gatsby
│ ├── # App code
│ └── .platform.app.yaml
└── README.md
```
From this repository, you deploy a Gatsby app and a WordPress app.
The code for each of them resides in their own directories.
When deploying a single app project [such as Gatsby](https://docs.platform.sh/guides/gatsby/deploy.md),
the repository needs three configuration files that describe its infrastructure, described below in detail.
For [multi-app projects](https://docs.platform.sh/create-apps/multi-app.md),
two of those files remain in the project root and are shared between Gatsby and WordPress.
Each app keeps its own app configuration file (`.platform.app.yaml`) in its subdirectory.
####### Service configuration
This file describes which [service containers](https://docs.platform.sh/add-services.md) (such as a database) your project should include.
Gatsby does not require services to deploy, but WordPress does.
So the following examples shows these service configurations:
```yaml {}
db:
type: mariadb:10.4
disk: 512
```
####### Routes configuration
This [`.platform/routes.yaml`](https://docs.platform.sh/define-routes.md) file defines how requests are handled by Platform.sh.
The following example shows Gatsby being served from the primary domain
and WordPress being accessible from the `backend` subdomain.
```yaml {}
"https://www.{default}/":
type: upstream
upstream: "gatsby:http"
"https://{default}/":
type: redirect
to: "https://www.{default}/"
"https://backend.{default}/":
type: upstream
upstream: "wordpress:http"
cache:
enabled: true
# Base the cache on the session cookies. Ignore all other cookies.
cookies:
- '/^wordpress_logged_in_/'
- '/^wordpress_sec_/'
- 'wordpress_test_cookie'
- '/^wp-settings-/'
- '/^wp-postpass/'
- '/^wp-resetpass-/'
```
###### WordPress
The multi-app template has a single modification to Platform.sh's [standard WordPress template](https://github.com/platformsh-templates/wordpress):
the `name` attribute in WordPress's `.platform/services.yaml` has been updated to `wordpress`.
This value is used to define the [relationship between Gatsby and WordPress](#gatsby)
and in the [routes configuration](#routes-configuration).
###### Gatsby
The frontend Gatsby app has a slightly different configuration from the basic [Gatsby deployment](https://docs.platform.sh/guides/gatsby/deploy.md).
Below is the `gatsby/.platform.app.yaml` file that configures the app.
```yaml {}
# .platform.app.yaml
# The name of this application, which must be unique within a project.
name: 'gatsby'
# The type key specifies the language and version for your application.
type: 'nodejs:14'
# Restrict Yarn memory use when running during post deploy hook.
variables:
env:
NODE_OPTIONS: --max_old_space_size=1536
# The hooks that will be triggered when the package is deployed.
hooks:
# Post deploy hook builds Gatsby frontend now that backend content is available.
post_deploy: |
npm run build
relationships:
wordpress: "wordpress:http"
# The size of the persistent disk of the application (in MB).
disk: 1280
# The configuration of the application when it is exposed to the web.
web:
locations:
'/':
# The public directory of the application relative to its root.
root: 'public'
index: ['index.html']
scripts: false
allow: true
mounts:
'/.cache':
source: local
source_path: cache
'/.config':
source: local
source_path: config
'public':
source: local
source_path: public
```
In particular, notice:
- `relationships`
Access to another service or app container in the cluster is given through [`relationships`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#relationships).
In this case, one has been defined to the backend WordPress container using it's `name`.
- `post_deploy`
Platform.sh containers reside in separate build containers at build time,
before their images are moved to the final app container at deploy time.
These build containers are isolated and so Gatsby can't access WordPress during the build hook,
where you would normally run the [`gatsby build` command](https://github.com/platformsh-templates/gatsby/blob/master/.platform.app.yaml#L21).
WordPress isn't available until after the deploy hook.
So the Gatsby build is postponed until the [`post_deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook).
To run `gatsby build` on-demand, or to trigger a rebuild from the backend when content is updated,
define a [runtime operation](https://docs.platform.sh/create-apps/runtime-operations.md#build-your-app-when-using-a-static-site-generator).
- `mounts`
There are consequences to postponing the Gatsby build,
as you don't generally have write access to the container this late in the pipeline.
To allow Gatsby to write to `public`, that directory has been defined as a [mount](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#mounts).
You can then modify [gatsby-config.js](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-config/)
to read from the backend WordPress container through the ``wordpress`` relationship defined above
to configure the ``baseUrl`` attribute for ``gatsby-source-wordpress``.
The plugin requires you to define the ``protocol``,
which in this case is ``http`` because WordPress content is retrieved through an internal request to the backend container.
Also, you need to declare ``hostingWPCOM: false`` as you don’t pull data from a WordPress site hosted at wordpress.com.
This is facilitated by Platform.sh's [Config Reader library](https://github.com/platformsh/config-reader-nodejs).
So be sure to install this to the Gatsby dependencies first when replicating.
When used, Gatsby pulls the information to communicate with the WordPress container *on the current branch*.
Lastly, the Gatsby app itself needs to include [GraphQL queries](https://www.gatsbyjs.com/docs/reference/graphql-data-layer/)
to handle the data coming from WordPress and create content pages.
The most important files in the template you should consult are:
- [`gatsby/gatsby-node.js`](https://github.com/platformsh-templates/gatsby-wordpress/blob/master/gatsby/gatsby-node.js)
Dynamically creates individual pages from the data source using Gatsby's [Node API](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-node/). It retrieves all of WordPress's posts using the GraphQL query `allWordpressPost`. A page is created (`createPage`) with an assigned `path` and formatting described by the `blog-post.js` template file below (`component`).
- [`gatsby/src/templates/blog-post.js`](https://github.com/platformsh-templates/gatsby-wordpress/blob/master/gatsby/src/templates/blog-post.js)
The template file that defines how a single WordPress post should be formatted on Gatsby, retrieving the data from that post using the `allWordpressPost` GraphQL query and filtering for its `slug`.
- [`gatsby/src/pages/index.js`](https://github.com/platformsh-templates/gatsby-wordpress/blob/master/gatsby/src/pages/index.js)
Retrieves all of WordPress's content to generate a list of posts on the homepage using the `allWordpressPost` GraphQL query.
###### Deploy and post-install
When you first deploy the template, the frontend Gatsby site will fail with a 403 error.
Visit the `backend` subdomain of your site and finish the installation of WordPress.
You don't need to set database credentials as they're already provided.
WordPress comes with an initial “Hello world” article, and it isn’t necessary to add any more content to the site.
Once you've finished, redeploy the project with the CLI command `platform redeploy` to view your Gatsby site,
It's now pulling its content from a backend WordPress container in the same project.
###### Next steps
With Gatsby now deployed and pulling content from a backend WordPress application, there are a few things you may wish to change about your project going forward.
####### Shared application configuration
You can optionally combine the application configuration (`.platform/services.yaml`) for Gatsby
and WordPress into a [single configuration file](https://docs.platform.sh/create-apps/multi-app/project-structure.md#unified-app-configuration).
Like `.platform/services.yaml` and `.platform/routes.yaml`, this file is shared across the project and resides in the `.platform` subdirectory.
You need to explicitly define the source of each application.
####### Multiple content sources
Gatsby supports pulling multiple sources into its build.
This includes external services like Stripe and additional backend CMSs for different sets of content.
As in this example with WordPress,
you can branch off your repository and add an additional directory that contains the codebase for [another backend](https://docs.platform.sh/guides/gatsby/headless.md#headless-backends).
Then add the source plugin for that backend to `gatsby-config.js`.
####### Plan size
As mentioned previously, you should have at least a Medium
plan for your multi-app projects.
This size gives the project enough resources for all of your containers
as well as the memory necessary to actually pull content from WordPress into Gatsby during its build.
Keep in mind that the increased plan size applies only to your production environment,
and not to preview environments (which default to Standard
).
As you continue to work with Gatsby and a backend headless CMS,
you may want to [upsize your preview environments](https://docs.platform.sh/administration/pricing.md#preview-environments).
### Deploy Next.js on Platform.sh
[Next.js](https://nextjs.org/) is a React framework for building websites and web apps,
with server-side rendering and static site generation.
See an example Next.js project in the official [Platform.sh Next.js template](https://github.com/platformsh-templates/nextjs).
You can use it as a starting point for your own project.
If you already have a Next.js project ready to deploy,
see the template's [example app configuration](https://github.com/platformsh-templates/nextjs/blob/master/.platform.app.yaml)
and other [example Platform.sh files](https://github.com/platformsh-templates/nextjs/tree/master/.platform).
These files let you [configure your app](https://docs.platform.sh/create-apps.md),
[add services](https://docs.platform.sh/add-services.md), and [define routes](https://docs.platform.sh/define-routes.md).
### Deploy Strapi on Platform.sh
[Strapi](https://strapi.io) is an open-source headless CMS for building fast and manageable APIs written in JavaScript.
To get Strapi running on Platform.sh, you have two potential starting places:
- You already have a Strapi site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic Strapi site.
- Use a ready-made [Strapi template](https://github.com/platformsh-templates/strapi4).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Strapi template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure Strapi](https://docs.platform.sh/guides/strapi/deploy/configure.md)
#### Configure Strapi for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml && touch .platform.app.yaml
```
Now that you've added these files to your project,
configure each one for Strapi in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Strapi requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
In the Strapi template, ``yarn`` is run during the build hook to install all of Strapi’s dependencies, and then ``yarn build`` is run to build the site.
If you would rather use npm to manage your dependencies, you can:
- Delete ``yarn`` from the build hook.
- Replace ``yarn build`` in the build hook with ``npm run build``.
- Delete the ``build.flavor`` block.
When this is set to ``none``, Platform.sh to rely solely on the build hook to define the build process.
By default, Node.js containers run ``npm install`` prior to the build hook,
so this block can be removed entirely from the configuration.
- Delete the ``dependencies`` block, which includes yarn.
The relationships block is responsible for providing access to the data sources (services) that the Strapi application needs.
Since Platform.sh is read-only during build, mainly for security purposes, certain folders need to be mounted.
Platform.sh allows you to mount directories that need write access during the deploy phase with the ``mounts`` key.
In this case, the following folders are mounted for Strapi.
- ``.cache`` file
- ``.tmp`` file
- ``database`` folder
- ``extensions`` folder
- ``uploads`` folder in the ``public`` directory
```yaml {location=".platform.app.yaml"}
# Complete list of all available properties: https://docs.platform.sh/create-apps/app-reference.html
# A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated
# with the app.
name: app
# The runtime the application uses.
# Complete list of available runtimes: https://docs.platform.sh/create-apps/app-reference.html#types
type: nodejs:18
# The relationships of the application with services or other applications.
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
# More information: https://docs.platform.sh/create-apps/app-reference.html#relationships
relationships:
postgresdatabase: "dbpostgres:postgresql"
# The size of the persistent disk of the application (in MB). Minimum value is 128.
disk: 1024
# Mounts define directories that are writable after the build is complete. If set as a local source, disk property is required.
# More information: https://docs.platform.sh/create-apps/app-reference.html#mounts
mounts:
# Strapi's cache directory.
"/.cache":
source: local
source_path: cache
# Mount .tmp file in the app folder for strapi
".tmp":
source: local
source_path: app
# Mount database folder for strapi
"database":
source: local
source_path: database
# Give write access for extension configuration JSONs.
"extensions":
source: local
source_path: extensions
# Allow for media uploads at runtime.
"public/uploads":
source: local
source_path: uploads
# The web key configures the web server running in front of your app.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web
web:
# Commands are run once after deployment to start the application process.
# More information: https://docs.platform.sh/create-apps/app-reference.html#web-commands
commands:
# The command to launch your app. If it terminates, it’s restarted immediately.
start: |
yarn start
# Variables to control the environment. More information: https://docs.platform.sh/create-apps/app-reference.html#variables
variables:
env:
NODE_ENV: 'production'
# Specifies a default set of build tasks to run. Flavors are language-specific.
# More information: https://docs.platform.sh/create-apps/app-reference.html#build
build:
# Use Yarn instead of npm.
flavor: none
# Installs global dependencies as part of the build process. They’re independent of your app’s dependencies and
# are available in the PATH during the build process and in the runtime environment. They’re installed before
# the build hook runs using a package manager for the language.
# More information: https://docs.platform.sh/create-apps/app-reference.html#dependencies
dependencies:
nodejs:
yarn: "1.22.5"
# Hooks allow you to customize your code/environment as the project moves through the build and deploy stages
# More information: https://docs.platform.sh/create-apps/app-reference.html#hooks
hooks:
# The build hook is run after any build flavor.
# More information: https://docs.platform.sh/create-apps/hooks/hooks-comparison.html#build-hook
build: |
# Download dependencies and build Strapi.
yarn --frozen-lockfile
yarn build
# Information on the app's source code and operations that can be run on it.
# More information: https://docs.platform.sh/create-apps/app-reference.html#source
source:
######################################################################################################################
## ##
## This source operation is part of the Platform.sh process of updating and maintaining our collection of ##
## templates. For more information see https://docs.platform.sh/create-apps/source-operations.html and ##
## https://github.com/platformsh/source-operations ##
## ##
## YOU CAN SAFELY DELETE THIS COMMENT AND THE LINES BENEATH IT ##
## ##
######################################################################################################################
operations:
auto-update:
command: |
curl -fsS https://raw.githubusercontent.com/platformsh/source-operations/main/setup.sh | { bash /dev/fd/3 sop-autoupdate; } 3<&0
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
Strapi requires a database to deploy.
By default, it uses a SQLite database but other database types are also supported.
These other database types are Oracle MySQL, PostgreSQL, or MongoDB (available only in Strapi v3 and below).
The Strapi template defines a PostgreSQL database service.
To use another service, replace ``postgresql:12`` in the example below with the name and version of the database you want.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure to use those services once they're enabled.
Each service entry has a name (`db` in the example)
and a `type` that specifies the service and version to use.
Services that store persistent data have a `disk` key, to specify the amount of storage.
```yaml {location=".platform/services.yaml"}
# The services of the project.
# Each service listed is deployed
# to power your Platform.sh project.
db:
type: postgresql:12
disk: 256
# Uncomment the line below to use a MySQL database
# dbmysql:
# type: oracle-mysql:8.0
# disk: 256
```
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Strapi app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
# More information: https://docs.platform.sh/define-routes.html
"https://www.{default}/":
type: upstream
upstream: "app:http"
# A basic redirect definition
# More information: https://docs.platform.sh/define-routes.html#basic-redirect-definition
"https://{default}/":
type: redirect
to: "https://www.{default}/"
```
#### Deploy Strapi
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Additional changes
A standard Strapi site
(one created either interactively through `npx create-strapi-app@latest my-project` or through a template)
generates a basic Strapi instance with access to the admin panel without any external services.
If this is your starting point, you have all of the configuration necessary to deploy your project.
Below are a few modifications that may help you develop your site more efficiently going forward.
####### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
Install the package with your preferred package manager:
```bash
npm install platformsh-config
# Or for Yarn
yarn add platformsh-config
```
Go forth and deploy (even on Friday)!
[Back](https://docs.platform.sh/guides/strapi/deploy/configure.md)
### Configuring Database Services for Strapi on Platform.sh
Strapi requires a database in order for it to run successfully. It currently has support for the following database types:
- SQLite
- PostgreSQL
- Oracle MySQL/MariaDB
- MongoDB (only Strapi v3)
#### Configure SQLite for Strapi on Platform.sh
Strapi uses SQLite database by default when it's run on a local machine.
When you create a new Strapi project, you can use SQLite or a custom database installation (PostgreSQL, MongoDB, or MySQL).
Since Strapi uses SQLite by default, you don't need much configuration, just follow these steps:
1. In your Strapi project, install the [config reader](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
```bash
npm install platformsh-config
# or for Yarn
yarn add platformsh-config
```
1. Create a new Strapi project and select Quickstart as the installation type.
This automatically configures Strapi for SQLite
```bash
npx create-strapi-app
```
1. In the `config` folder, locate the `database.js` file, and replace its content with the following:
```js
const config = require("platformsh-config").config();
const path = require("path");
let dbRelationship = "pg";
// Strapi default sqlite settings.
let pool = {};
let connection = {
connection: {
client: 'sqlite',
connection: {
filename: path.join(\_\_dirname, '..', process.env.DATABASE_FILENAME || '.tmp/data.db'),
},
useNullAsDefault: true,
},
};
if (config.isValidPlatform() && !config.inBuild()) {
// Platform.sh database configuration.
try {
const credentials = config.credentials(dbRelationship);
console.log(`Using Platform.sh configuration with relationship ${dbRelationship}.`);
pool = {
min: 0,
max: 10,
acquireTimeoutMillis: 600000,
createTimeoutMillis: 30000,
idleTimeoutMillis: 20000,
reapIntervalMillis: 20000,
createRetryIntervalMillis: 200,
};
connection = {
connection: {
client: "postgres",
connection: {
host: credentials.ip,
port: credentials.port,
database: credentials.path,
user: credentials.username,
password: credentials.password,
ssl: false
},
debug: false,
pool
},
};
}
catch (e) {
// Do nothing if 'pg' relationship isn't found.
// Database configuration falls back on the SQLite defaults.
}
} else {
if (config.isValidPlatform()) {
// Build hook configuration message.
console.log('Using default configuration during Platform.sh build hook until relationships are available.');
} else {
// Strapi default local configuration.
console.log('Not in a Platform.sh Environment. Using default local sqlite configuration.');
}
}
// strapi-api/config/database.js
module.exports = ({ env }) => ( connection );
```
This setting deploys your Strapi application with an SQLite database.
#### Configure PostgreSQL for Strapi on Platform.sh
Strapi can be configured to use PostgreSQL as its default database.
You can choose PostgreSQL when installing your app by selecting custom and PostgreSQL when asked for the installation type
or you can just configure your existing Strapi application to use PostgreSQL.
To configure a PostgreSQL database for Strapi on Platform.sh, follow these steps.
1. Install [PostgreSQL](https://www.postgresql.org/download/) on your machine
and [pg](https://www.npmjs.com/package/pg) in your Strapi project.
Pg comes installed with a fresh Strapi installation.
1. In your `.platform/services.yaml` file, add the following:
```yaml {location=".platform/services.yaml"}
postgres:
type: postgresql:13
disk: 512
```
1. In your `.platform.app.yaml` file, replace the relationship name to match the PostgreSQL database you added:
```yaml {location=".platform.app.yaml"}
relationships:
postgresdatabase: "postgres:postgresql"
```
1. In the `config` folder, locate the `database.js` file, and replace its content with the following:
```js
const path = require("path");
const config = require("platformsh-config").config();
let dbRelationship = "postgresdatabase";
// Strapi default sqlite settings.
let connection = {
connection: {
client: "sqlite",
connection: {
filename: path.join(
__dirname,
"..",
process.env.DATABASE_FILENAME || ".tmp/data.db"
),
},
useNullAsDefault: true,
},
};
if (config.isValidPlatform() && !config.inBuild()) {
// Platform.sh database configuration.
const credentials = config.credentials(dbRelationship);
console.log(
`Using Platform.sh configuration with relationship ${dbRelationship}.`
);
let pool = {
min: 0,
max: 10,
acquireTimeoutMillis: 600000,
createTimeoutMillis: 30000,
idleTimeoutMillis: 20000,
reapIntervalMillis: 20000,
createRetryIntervalMillis: 200,
};
connection = {
connection: {
client: "postgres",
connection: {
host: credentials.ip,
port: credentials.port,
database: credentials.path,
user: credentials.username,
password: credentials.password,
ssl: false,
},
debug: false,
pool,
},
};
} else {
if (config.isValidPlatform()) {
// Build hook configuration message.
console.log(
"Using default configuration during Platform.sh build hook until relationships are available."
);
} else {
// Strapi default local configuration.
console.log(
"Not in a Platform.sh Environment. Using default local sqlite configuration."
);
}
}
console.log(connection);
// export strapi database connection
module.exports = ({ env }) => connection;
```
This setting deploys your Strapi application with a PostgreSQL database.
If you don't specify a PostgreSQL service in your `.platform/services.yaml` file or the Strapi application is run on a local machine
the default SQLite database is used.
#### Configure MySQL for Strapi on Platform.sh
Strapi can be configured to use MySQL as its default database.
You can choose MySQL when installing your app by selecting custom and MySQL when asked for the installation type.
Or you can just configure your existing Strapi application to use MySQL.
To configure a MySQL database for Strapi on Platform.sh, follow these steps.
1. Install the Node.js [MySQL driver](https://yarnpkg.com/package/mysql)
```bash
yarn add mysql
```
2. Replace the PostgreSQL configuration in your `.platform/services.yaml` file with the following:
```yaml {location=".platform/services.yaml"}
mysql:
type: oracle-mysql:8.0
disk: 256
```
**_Note that the minimum disk size for MySQL/Oracle MySQL is 256MB._**
3. In your `.platform.app.yaml` file, replace the relationship name to match the MySQL database you added:
```yaml {location=".platform.app.yaml"}
relationships:
mysqldatabase:
service: "mysql"
endpoint: "mysql"
```
4. In the `config` folder, locate the `database.js` file, and replace its content with the following:
```js
const config = require("platformsh-config").config();
const path = require("path");
let dbRelationship = "mysqldatabase";
// Strapi default sqlite settings.
let pool = {};
let connection = {
connection: {
client: "sqlite",
connection: {
filename: path.join(
__dirname,
"..",
process.env.DATABASE_FILENAME || ".tmp/data.db"
),
},
useNullAsDefault: true,
},
};
if (config.isValidPlatform() && !config.inBuild()) {
// Platform.sh database configuration.
try {
const credentials = config.credentials(dbRelationship);
console.log(
`Using Platform.sh configuration with relationship ${dbRelationship}.`
);
pool = {
min: 0,
max: 10,
acquireTimeoutMillis: 600000,
createTimeoutMillis: 30000,
idleTimeoutMillis: 20000,
reapIntervalMillis: 20000,
createRetryIntervalMillis: 200,
};
connection = {
connection: {
client: "mysql",
connection: {
host: credentials.ip,
port: credentials.port,
database: credentials.path,
user: credentials.username,
password: credentials.password,
ssl: false,
},
debug: false,
pool,
},
};
} catch (e) {
// Do nothing if 'pg' relationship isn't found.
// Database configuration will fall back on the SQLite defaults.
}
} else {
if (config.isValidPlatform()) {
// Build hook configuration message.
console.log(
"Using default configuration during Platform.sh build hook until relationships are available."
);
} else {
// Strapi default local configuration.
console.log(
"Not in a Platform.sh Environment. Using default local sqlite configuration."
);
}
}
// strapi-api/config/database.js
module.exports = ({ env }) => connection;
```
This setting deploys your Strapi application with a MySQL database.
If you don't specify a MySQL service in your `.platform/services.yaml` file or the Strapi application is run on a local machine
the default SQLite database is used.
#### Configure MongoDB for Strapi on Platform.sh
Strapi can also be configured to use MongoDB as its default database,
although due to compatibility issues this database type is only available in Strapi v3 and [not supported in Strapi v4](https://forum.strapi.io/t/mongodb-compatibility-delayed-on-v4/4549).
To use MongoDB with a Strapi v3 application on Platform.sh, follow these steps.
1. Install the [Strapi mongoose connector](https://yarnpkg.com/package/strapi-connector-mongoose)
```bash
yarn add strapi-connector-mongoose
```
1. Replace the PostgreSQL configuration in your `.platform/services.yaml` file with the following:
```yaml {location=".platform/services.yaml"}
mongodb:
type: mongodb:3.6
disk: 512
```
**_Note that the minimum disk size for MongoDB is 512MB._**
1. In your `.platform.app.yaml` file, replace the relationship name to match the MongoDB database you added:
```yaml {location=".platform.app.yaml"}
relationships:
mongodatabase:
service: "mongodb"
endpoint: "mongodb"
```
1. In the `config` folder, locate the `database.js` file, and replace its content with the following:
```js
const config = require("platformsh-config").config();
let dbRelationshipMongo = "mongodatabase";
// Strapi default sqlite settings.
let settings = {
client: "sqlite",
filename: process.env.DATABASE_FILENAME || ".tmp/data.db",
};
let options = {
useNullAsDefault: true,
};
if (config.isValidPlatform() && !config.inBuild()) {
// Platform.sh database configuration.
const credentials = config.credentials(dbRelationshipMongo);
console.log(
`Using Platform.sh configuration with relationship ${dbRelationshipMongo}.`
);
settings = {
client: "mongo",
host: credentials.host,
port: credentials.port,
database: credentials.path,
username: credentials.username,
password: credentials.password,
};
options = {
ssl: false,
authenticationDatabase: "main",
};
} else {
if (config.isValidPlatform()) {
// Build hook configuration message.
console.log(
"Using default configuration during Platform.sh build hook until relationships are available."
);
} else {
// Strapi default local configuration.
console.log(
"Not in a Platform.sh Environment. Using default local sqlite configuration."
);
}
}
module.exports = {
defaultConnection: "default",
connections: {
default: {
connector: "mongoose",
settings: settings,
options: options,
},
},
};
```
This configuration instructs Platform.sh to deploy your Strapi v3 app with a MongoDB database.
### Local development: Running Strapi on your local machine with Platform.sh
Platform.sh provides support for locally running a Strapi application that has been deployed on Platform.sh including its services.
This means that once you download the code of the Strapi project you deployed on Platform.sh,
you can make changes to the project without pushing to Platform.sh each time to test them.
You can build your app locally using the Platform.sh CLI, even when its functionality depends on a number of services. You can run your Strapi application locally with all of it’s services by following the steps for your Strapi version:
#### Develop locally with Strapi v3
You can run your Strapi v3 app locally with all of its services.
First install the [config reader](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app) by running the following command:
```bash
npm install platformsh-config OR yarn add platformsh-config
```
It's also assumed that your `database.js` file in your `config` folder looks like this:
```js
const config = require("platformsh-config").config();
let dbRelationship = "postgresdatabase";
// Strapi default sqlite settings.
let settings = {
client: "sqlite",
filename: process.env.DATABASE_FILENAME || ".tmp/data.db",
};
let options = {
useNullAsDefault: true,
};
if (config.isValidPlatform() && !config.inBuild()) {
// Platform.sh database configuration.
const credentials = config.credentials(dbRelationship);
console.log(
`Using Platform.sh configuration with relationship ${dbRelationship}.`
);
settings = {
client: "postgres",
host: credentials.ip,
port: credentials.port,
database: credentials.path,
username: credentials.username,
password: credentials.password,
};
options = {
ssl: false,
debug: false,
acquireConnectionTimeout: 100000,
pool: {
min: 0,
max: 10,
createTimeoutMillis: 30000,
acquireTimeoutMillis: 600000,
idleTimeoutMillis: 20000,
reapIntervalMillis: 20000,
createRetryIntervalMillis: 200,
},
};
} else {
if (config.isValidPlatform()) {
// Build hook configuration message.
console.log(
"Using default configuration during Platform.sh build hook until relationships are available."
);
} else {
// Strapi default local configuration.
console.log(
"Not in a Platform.sh Environment. Using default local sqlite configuration."
);
}
}
module.exports = {
defaultConnection: "default",
connections: {
default: {
connector: "bookshelf",
settings: settings,
options: options,
},
},
};
```
If it's similar to the above and you’re running a Strapi v3 application,
follow the [instructions for general local development](https://docs.platform.sh/development/local.md).
#### Develop locally with Strapi v4
To run your Strapi v4 app locally with all of its services, follow these steps:
1. Download your deployed code by running the following command using the Platform.sh CLI:
```bash
platform get
```
2. Create a new branch.
Whenever you develop Platform.sh, you should develop in an isolated environment.
This way you aren't opening SSH tunnels to your production environment.
By creating a branch from your default environment,
you create a new environment with copies of all production code and data.
Create an isolated environment named `updates` by running the following command:
```bash
platform environment:branch updates
```
You can name the environment anything you want, just use the name you choose in later steps.
3. Assuming you're using a PostgreSQL or MySQL database,
modify your database connection to look like the following:
```js {location="config/database.js"}
const path = require("path");
let connection;
let db_relationship = "postgresdatabase";
// Helper function for decoding Platform.sh base64-encoded JSON variables.
function decode(value) {
return JSON.parse(Buffer.from(value, "base64"));
}
if (!process.env.PLATFORM_RELATIONSHIPS) {
if (process.env.PLATFORM_PROJECT) {
console.log(
"In Platform.sh build hook. Using default SQLite configuration until services are available."
);
} else {
console.log(
'Configuring local SQLite connection. \n\nIf you meant to use a tunnel, be sure to run \n\n$ export PLATFORM_RELATIONSHIPS="$(platform tunnel:info --encode)"\n\nto connect to that service.\n'
);
}
// Define the default SQLite connection.
connection = {
connection: {
client: "sqlite",
connection: {
filename: path.join(
__dirname,
"..",
process.env.DATABASE_FILENAME || ".tmp/data.db"
),
},
useNullAsDefault: true,
},
};
} else {
if (process.env.PLATFORM_PROJECT) {
console.log(
"In Platform.sh deploy hook. Using defined service configuration."
);
} else {
console.log("Using tunnel for local development.");
}
// Define the managed service connection.
let credentials = decode(process.env.PLATFORM_RELATIONSHIPS)[
db_relationship
][0];
// Option 1. PostgreSQL.
// The PostgreSQL configuration assumes the following in your .platform/services.yaml file:
//
// dbpostgres:
// type: postgresql:12
// disk: 256
//
// And a relationship defined in your .platform.app.yaml file as follows:
//
// relationships:
// postgresdatabase: "dbpostgres:postgresql"
if (credentials.scheme == "pgsql") {
console.log("PostgreSQL detected.");
let postgres_pool = {
min: 0,
max: 10,
acquireTimeoutMillis: 600000,
createTimeoutMillis: 30000,
idleTimeoutMillis: 20000,
reapIntervalMillis: 20000,
createRetryIntervalMillis: 200,
};
connection = {
connection: {
client: "postgres",
connection: {
host: credentials.ip,
port: credentials.port,
database: credentials.path,
user: credentials.username,
password: credentials.password,
ssl: false,
},
debug: false,
postgres_pool,
},
};
// Option 2. Oracle MySQL.
// The Oracle MySQL configuration assumes the following in your .platform/services.yaml file:
//
// dbmysql:
// type: oracle-mysql:8.0
// disk: 256
//
// And a relationship defined in your .platform.app.yamlfile as follows:
//
// relationships:
// database: "dbmysql:mysql"
} else if (credentials.scheme == "mysql") {
console.log("MySQL detected.");
connection = {
connection: {
client: "mysql",
connection: {
host: credentials.ip,
port: credentials.port,
database: credentials.path,
user: credentials.username,
password: credentials.password,
ssl: false,
},
debug: false,
},
};
}
}
// Export the connection to Strapi.
module.exports = ({ env }) => connection;
```
See the comments for explanations of individual sections.
If you have defined the relationship to your service differently (in `.platform.app.yaml`)
or are using a different service, use that name in place of `postgresdatabase`.
4. Open a SSH tunnel to the environment's database:
```bash
platform tunnel:open -A -e updates
```
Replace `` with your app's `name` in your `.platform.app.yaml` file.
If you get the error `The pcntl PHP extension is required` error, use this command instead:
```bash
platform tunnel:single -A -e updates
```
5. Add an environment variable that contains the service credentials:
```bash
export PLATFORM_RELATIONSHIPS="$(platform tunnel:info -A -e updates --encode)"
```
6. Download all media uploads from the environment:
```bash
platform mount:download -A -e updates -m public/uploads --target public/uploads -y
```
7. Build and start the Strapi server:
```bash
yarn --frozen-lockfile
yarn develop
```
Now your Strapi app should be running locally with a connection to a remote database
that's separate from your production database.
### Strapi multi-app projects
##### Background
A common pattern for Strapi applications is to serve as a backend or headless CMS for a frontend application.
This helps with serving external data to a frontend at build time.
Supported by Strapi's plugin ecosystem, data from Strapi (or headless) CMS can be served into a frontend application,
with that frontend typically located on a server elsewhere.
Platform.sh provides a platform for this architectural pattern through a [multi-app configuration](https://docs.platform.sh/create-apps/multi-app.md).
Consider the following project structure:
```bash
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── strapi
│ ├──
│ └── .platform.app.yaml
├── gatsby
│ ├──
│ └── .platform.app.yaml
└── README.md
```
Above is the repository structure for a decoupled Strapi project (Gatsby sourcing content from Strapi).
Strapi and Gatsby reside in their own subdirectories within the same repository.
They're deployed to the same project from separate application containers,
and from this cluster Gatsby can read data from Strapi internally.
Their commit histories are tied together,
so each new pull request environment can test changes to either the frontend or backend from the same place.
Gatsby is just one example of a frontend that can be used with this pattern.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Signing up
Each of the frontend guides below has a **Deploy on Platform.sh** button that deploys the guide's project for you
and also signs you up for a trial account.
If you're planning on deploying a template and following along with these guides for greater context,
feel free to move onto the next section.
If you're planning on using the templates and guides to deploy your existing codebase to Platform.sh,
you first need to [register for a trial Platform.sh account](https://auth.api.platform.sh/register).
If you don't want to sign up initially with your e-mail address,
you can sign up using an existing GitHub, Bitbucket, or Google account.
If you choose one of these options, you can set a password for your Platform.sh account later.
After creating an account, you're prompted to create your first project.
Since you are providing your own code, use the **Blank project** option.
Give the project a title and choose a region closest to your site visitors.
You can also select more resources for your project.
This is especially important with multi-application projects, so for more details see [plan size](#plan-size).
##### Plan size
There are a few important points to keep in mind when deploying this pattern if you've already [deployed Gatsby by itself](https://docs.platform.sh/guides/gatsby/deploy.md) on Platform.sh, which are relevant to each backend example.
After following the steps below,
you may find that Gatsby fails to bundle assets during its build if your plan size is Development.
This is a factor of both the size and number of Gatsby's dependencies on the frontend,
as well as the amount of data being pulled from the backend.
Multi-application projects generally require more resources to run on Platform.sh, and so the trial's default Development plan may not be enough to run your existing site.
You are free to either proceed with a smaller plan to test or increase the resources at this point for the project.
Otherwise, it may be best to initially deploy the templates listed in each backend guide to start out
and later modify that project to include your own code with more resources as you get used to developing on Platform.sh.
##### Frontends for Strapi
Platform.sh maintains a number of [multi-application templates](https://github.com/platformsh-templates/?q=strapi&type=&language=) for Strapi that generally have very similar configuration changes on the Strapi side.
Below are a few of those written as short guides for different frontends.
#### How to deploy Strapi with a Gatsby frontend on Platform.sh
Platform.sh maintains a [template](https://github.com/platformsh-templates/gatsby-strapi) that you can quickly deploy, and then use this guide as a reference for the Platform.sh specific changes that have been made to Gatsby and Strapi to make it work. Click the button below to sign up for a free trial account and deploy the project.

###### Shared configuration
Your local clone of the template has the following project structure:
```bash
├── .platform
│ ├── routes.yaml
│ └── services.yaml
├── strapi
│ ├── # App code
│ └── .platform.app.yaml
├── gatsby
│ ├── # App code
│ └── .platform.app.yaml
└── README.md
```
From this repository, you deploy a Gatsby app and a Strapi app.
The code for each of them resides in their own directories.
When deploying a single app project [such as Gatsby](https://docs.platform.sh/guides/gatsby/deploy.md),
the repository needs three configuration files that describe its infrastructure, described below in detail.
For [multi-app projects](https://docs.platform.sh/create-apps/multi-app.md),
two of those files remain in the project root and are shared between Gatsby and Strapi.
Each app keeps its own app configuration file (`.platform.app.yaml`) in its subdirectory.
####### Service configuration
This file describes which [service containers](https://docs.platform.sh/add-services.md) (such as a database) your project should include.
Gatsby does not require services to deploy, but Strapi does.
So the following examples shows these service configurations:
```yaml {}
# The services of the project.
#
# Each service listed will be deployed
# to power your Platform.sh project.
dbpostgres:
type: postgresql:12
disk: 256
```
####### Routes configuration
This [`.platform/routes.yaml`](https://docs.platform.sh/define-routes.md) file defines how requests are handled by Platform.sh.
The following example shows Gatsby being served from the primary domain
and Strapi being accessible from the `backend` subdomain.
```yaml {}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://www.{default}/":
type: upstream
upstream: "gatsby:http"
"https://{default}/":
type: redirect
to: "https://www.{default}/"
"https://www.backend.{default}/":
type: upstream
upstream: "strapi:http"
"https://backend.{default}/":
type: redirect
id: 'strapi'
to: "https://www.backend.{default}/"
```
###### Strapi
The multi-app template has a single modification to Platform.sh's [standard Strapi template](https://github.com/platformsh-templates/strapi):
the `name` attribute in Strapi's `.platform/services.yaml` has been updated to `strapi`.
This value is used to define the [relationship between Gatsby and Strapi](#gatsby)
and in the [routes configuration](#routes-configuration).
The only additional setup required to prepare the backend is to install a package that enables GraphQL on Strapi.
In your Strapi directory, add the dependency:
```bash
yarn add strapi-plugin-graphql
```
###### Gatsby
The frontend Gatsby app has a slightly different configuration from the basic [Gatsby deployment](https://docs.platform.sh/guides/gatsby/deploy.md).
Below is the `gatsby/.platform.app.yaml` file that configures the app.
```yaml {}
# .platform.app.yaml
# The name of this application, which must be unique within a project.
name: gatsby
# The type key specifies the language and version for your application.
type: 'nodejs:14'
# The hooks that will be triggered when the package is deployed.
hooks:
# Build hooks can modify the application files on disk but not access any services like databases.
post_deploy: |
npm run build
# The size of the persistent disk of the application (in MB).
disk: 1024
relationships:
strapi: "strapi:http"
# The configuration of the application when it is exposed to the web.
web:
locations:
'/':
# The public directory of the application relative to its root.
root: 'public'
index: ['index.html']
scripts: false
allow: true
mounts:
'/.cache':
source: local
source_path: cache
'/.config':
source: local
source_path: config
'public':
source: local
source_path: public
```
In particular, notice:
- `relationships`
Access to another service or app container in the cluster is given through [`relationships`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#relationships).
In this case, one has been defined to the backend Strapi container using it's `name`.
- `post_deploy`
Platform.sh containers reside in separate build containers at build time,
before their images are moved to the final app container at deploy time.
These build containers are isolated and so Gatsby can't access Strapi during the build hook,
where you would normally run the [`gatsby build` command](https://github.com/platformsh-templates/gatsby/blob/master/.platform.app.yaml#L21).
Strapi isn't available until after the deploy hook.
So the Gatsby build is postponed until the [`post_deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook).
To run `gatsby build` on-demand, or to trigger a rebuild from the backend when content is updated,
define a [runtime operation](https://docs.platform.sh/create-apps/runtime-operations.md#build-your-app-when-using-a-static-site-generator).
- `mounts`
There are consequences to postponing the Gatsby build,
as you don't generally have write access to the container this late in the pipeline.
To allow Gatsby to write to `public`, that directory has been defined as a [mount](https://docs.platform.sh/create-apps/app-reference/single-runtime-image#mounts).
You can then modify [gatsby-config.js](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-config/) to read from the backend Strapi container through the ``strapi`` relationship defined above to configure the ``apiURL`` attribute for ``gatsby-source-strapi``. Notice that the source plugin requires that you explicitly define the ``contentTypes`` you would like to retrieve from Strapi. At this point you have not built out the API, and the Content Types ``article`` and ``category`` are included to support the [post-install instructions](https://github.com/platformsh-templates/gatsby-strapi#user-content-post-install) outlined in the template’s README. Adjust these values to fit your current API if your are planning on migrating an existing Strapi repository.
This is facilitated by Platform.sh's [Config Reader library](https://github.com/platformsh/config-reader-nodejs).
So be sure to install this to the Gatsby dependencies first when replicating.
When used, Gatsby pulls the information to communicate with the Strapi container *on the current branch*.
Lastly, the Gatsby app itself needs to include [GraphQL queries](https://www.gatsbyjs.com/docs/reference/graphql-data-layer/)
to handle the data coming from Strapi and create content pages.
The most important files in the template you should consult are:
- [`gatsby/gatsby-node.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/gatsby-node.js)
Dynamically creates individual pages from the data source using Gatsby's [Node API](https://www.gatsbyjs.com/docs/reference/config-files/gatsby-node/). It retrieves all of Strapi's articles and categories (see [post-install below](#deploy-and-post-install)) using the GraphQL queries `allStrapiArticle` and `allStrapiCategory` respectively. For each, a page is created (`createPage`) with an assigned `path` and formatting described by one of the template files below (`component`).
- [`gatsby/src/templates/article.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/src/templates/article.js)
The template file that defines how a single Strapi article should be formatted on Gatsby, retrieving the data from that article using the `strapiArticle` GraphQL query.
- [`gatsby/src/templates/category.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/src/templates/category.js)
The template file that defines how a list of articles that belong to a single Category are formatted by Gatsby. It uses the `Category` query, and then filters a specific category `id` on `allStrapiArticle`.
- [`gatsby/src/pages/index.js`](https://github.com/platformsh-templates/gatsby-strapi/blob/master/gatsby/src/pages/index.js)
Retrieves all of Strapi's content to generate a list of articles on the homepage using the `allStrapiArticle` GraphQL query.
###### Deploy and post-install
When you first deploy the template, the frontend Gatsby site will fail with a 403 error.
Visit the `backend` subdomain of your site and finish the installation of Strapi.
You don't need to set database credentials as they're already provided.
After you have deployed, you need to set up Strapi’s Admin Panel and some initial content endpoints for the Gatsby frontend to consume. Create your admin user at the ``backend`` subdomain for Strapi. You can then follow the [template’s post-install instructions](https://github.com/platformsh-templates/gatsby-strapi#user-content-post-install) to setup up some initial ``Article`` and ``Category`` content endpoints. The API you develop there is only accessible to admins by default, so be sure to adjust the permissions to public so Gatsby can access it.
Once you've finished, redeploy the project with the CLI command `platform redeploy` to view your Gatsby site,
It's now pulling its content from a backend Strapi container in the same project.
###### Next steps
With Gatsby now deployed and pulling content from a backend Strapi application, there are a few things you may wish to change about your project going forward.
####### Shared application configuration
You can optionally combine the application configuration (`.platform/services.yaml`) for Gatsby
and Strapi into a [single configuration file](https://docs.platform.sh/create-apps/multi-app/project-structure.md#unified-app-configuration).
Like `.platform/services.yaml` and `.platform/routes.yaml`, this file is shared across the project and resides in the `.platform` subdirectory.
You need to explicitly define the source of each application.
####### Multiple content sources
Gatsby supports pulling multiple sources into its build. This can include external services like Stripe, or additional backend CMSs for different sets of content. Like shown here with Strapi, you can branch off your repository and add an additional subdirectory that contains the codebase for another frontend.
####### Plan size
As mentioned previously, you should have at least a Medium
plan for your multi-app projects.
This size gives the project enough resources for all of your containers
as well as the memory necessary to actually pull content from Strapi into Gatsby during its build.
Keep in mind that the increased plan size applies only to your production environment,
and not to preview environments (which default to Standard
).
As you continue to work with Gatsby and a backend headless CMS,
you may want to [upsize your preview environments](https://docs.platform.sh/administration/pricing.md#preview-environments).
### Deploy Hibernate ORM on Platform.sh
[Hibernate ORM](https://hibernate.org/) is an object-relational mapping tool for the Java programming language. It provides a framework for mapping an object-oriented domain model to a relational database. Hibernate handles object-relational impedance mismatch problems by replacing direct, persistent database accesses with high-level object handling functions.
##### Services
###### Configuration reader
While you can read the environment directly from your app,
you might want to use the[Java configuration reader library](https://github.com/platformsh/config-reader-java).
It decodes service credentials, the correct port, and other information for you.
Note that the Java configuration reader library is used in the following examples.
###### MySQL
[MySQL](https://docs.platform.sh/add-services/mysql.md) is an open-source relational database technology. Define the driver for [MySQL](https://mvnrepository.com/artifact/mysql/mysql-connector-java), and the Java dependencies. Then determine the SessionFactory client programmatically:
```java
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
import sh.platform.config.Config;
import sh.platform.config.Hibernate;
public class HibernateApp {
public static void main(String[] args) {
Config config = new Config();
Configuration configuration = new Configuration();
configuration.addAnnotatedClass(Address.class);
final Hibernate credential = config.getCredential("database", Hibernate::new);
final SessionFactory sessionFactory = credential.getMySQL(configuration);
try (Session session = sessionFactory.openSession()) {
Transaction transaction = session.beginTransaction();
//...
transaction.commit();
}
}
}
```
**Note**:
You can use the same MySQL driver for MariaDB as well if you wish to do so.
###### MariaDB
[MariaDB](https://docs.platform.sh/add-services/mysql.md) is an open-source relational database technology. Define the driver for [MariaDB](https://mvnrepository.com/artifact/org.mariadb.jdbc/mariadb-java-client), and the Java dependencies. Then determine the SessionFactory client programmatically:
```java
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
import sh.platform.config.Config;
import sh.platform.config.Hibernate;
public class HibernateApp {
public static void main(String[] args) {
Config config = new Config();
Configuration configuration = new Configuration();
configuration.addAnnotatedClass(Address.class);
final Hibernate credential = config.getCredential("database", Hibernate::new);
final SessionFactory sessionFactory = credential.getMariaDB(configuration);
try (Session session = sessionFactory.openSession()) {
Transaction transaction = session.beginTransaction();
//...
transaction.commit();
}
}
}
```
###### PostgreSQL
[PostgreSQL](https://docs.platform.sh/add-services/postgresql.md) is an open-source relational database technology. Define the driver for [PostgreSQL](https://mvnrepository.com/artifact/postgresql/postgresql), and the Java dependencies. Then determine the SessionFactory client programmatically:
```java
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.Transaction;
import org.hibernate.cfg.Configuration;
import sh.platform.config.Config;
import sh.platform.config.Hibernate;
public class HibernateApp {
public static void main(String[] args) {
Config config = new Config();
Configuration configuration = new Configuration();
configuration.addAnnotatedClass(Address.class);
final Hibernate credential = config.getCredential("database", Hibernate::new);
final SessionFactory sessionFactory = credential.getPostgreSQL(configuration);
try (Session session = sessionFactory.openSession()) {
Transaction transaction = session.beginTransaction();
//...
transaction.commit();
}
}
}
```
### Deploy Jakarta on Platform.sh
[Eclipse MicroProfile](https://microprofile.io/) is a community dedicated to optimizing the Enterprise Java mission for microservice-based architectures. The goal is to define a microservices application platform that is portable across multiple runtimes. Currently, the leading players in this group are IBM, Red Hat, Tomitribe, Payara, the London Java Community (LJC), and SouJava.
Java Enterprise Edition (Java EE) is an umbrella that holds specifications and APIs with enterprise features, like distributed computing and web services. Widely used in Java, Java EE runs on reference runtimes that can be anything from microservices to application servers that handle transactions, security, scalability, concurrency, and management for the components it’s deploying. Now, Enterprise Java has been standardized under the Eclipse Foundation with the name [Jakarta EE](https://jakarta.ee/).
##### Services
###### Configuration reader
While you can read the environment directly from your app,
you might want to use the[Java configuration reader library](https://github.com/platformsh/config-reader-java).
It decodes service credentials, the correct port, and other information for you.
Note that the Java configuration reader library is used in the following examples.
###### MongoDB
You can use [Jakarta NoSQL](https://projects.eclipse.org/projects/ee4j.nosql)/[JNoSQL](https://projects.eclipse.org/projects/technology.jnosql) to use [MongoDB](https://docs.platform.sh/add-services/mongodb.md) with your application by first determining the MongoDB client programmatically.
```java
import com.mongodb.MongoClient;
import jakarta.nosql.document.DocumentCollectionManager;
import jakarta.nosql.document.DocumentCollectionManagerFactory;
import org.jnosql.diana.mongodb.document.MongoDBDocumentConfiguration;
import sh.platform.config.Config;
import sh.platform.config.MongoDB;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
@ApplicationScoped
class DocumentManagerProducer {
private DocumentCollectionManagerFactory managerFactory;
private MongoDB mongoDB;
@PostConstruct
public void init() {
Config config = new Config();
this.mongoDB = config.getCredential("database", MongoDB::new);
final MongoClient mongoClient = mongoDB.get();
MongoDBDocumentConfiguration configuration = new MongoDBDocumentConfiguration();
this.managerFactory = configuration.get(mongoClient);
}
@Produces
public DocumentCollectionManager getManager() {
return managerFactory.get(mongoDB.getDatabase());
}
public void destroy(@Disposes DocumentCollectionManager manager) {
this.manager.close();
}
}
```
###### Apache Solr
You can use [Jakarta NoSQL](https://projects.eclipse.org/projects/ee4j.nosql)/[JNoSQL](https://projects.eclipse.org/projects/technology.jnosql) to use [Solr](https://docs.platform.sh/add-services/solr.md) with your application by first determining the Solr client programmatically.
```java
import jakarta.nosql.document.DocumentCollectionManager;
import jakarta.nosql.document.DocumentCollectionManagerFactory;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.jnosql.diana.solr.document.SolrDocumentConfiguration;
import sh.platform.config.Config;
import sh.platform.config.Solr;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
@ApplicationScoped
class DocumentManagerProducer {
private DocumentCollectionManagerFactory managerFactory;
@PostConstruct
public void init() {
Config config = new Config();
Solr solr = config.getCredential("database", Solr::new);
final HttpSolrClient httpSolrClient = solr.get();
SolrDocumentConfiguration configuration = new SolrDocumentConfiguration();
this.managerFactory = configuration.get(httpSolrClient);
}
@Produces
public DocumentCollectionManager getManager() {
return managerFactory.get("collection");
}
public void destroy(@Disposes DocumentCollectionManager manager) {
this.manager.close();
}
}
```
###### Elasticsearch
You can use [Jakarta NoSQL](https://projects.eclipse.org/projects/ee4j.nosql)/[JNoSQL](https://projects.eclipse.org/projects/technology.jnosql) to use [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md) with your application by first determining the Elasticsearch client programmatically.
```java
import jakarta.nosql.document.DocumentCollectionManager;
import jakarta.nosql.document.DocumentCollectionManagerFactory;
import org.elasticsearch.client.RestHighLevelClient;
import org.jnosql.diana.elasticsearch.document.ElasticsearchDocumentConfiguration;
import sh.platform.config.Config;
import sh.platform.config.Elasticsearch;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
@ApplicationScoped
class DocumentManagerProducer {
private DocumentCollectionManagerFactory managerFactory;
@PostConstruct
public void init() {
Config config = new Config();
Elasticsearch elasticsearch = config.getCredential("database", Elasticsearch::new);
final RestHighLevelClient client = elasticsearch.get();
ElasticsearchDocumentConfiguration configuration = new ElasticsearchDocumentConfiguration();
this.managerFactory = configuration.get(client);
}
@Produces
public DocumentCollectionManager getManager() {
return managerFactory.get("collection");
}
public void destroy(@Disposes DocumentCollectionManager manager) {
this.manager.close();
}
}
```
###### Redis
You can use [Jakarta NoSQL](https://projects.eclipse.org/projects/ee4j.nosql)/[JNoSQL](https://projects.eclipse.org/projects/technology.jnosql) to use [Redis](https://docs.platform.sh/add-services/redis.md) with your application by first determining the Redis client programmatically.
```java
import jakarta.nosql.keyvalue.BucketManager;
import org.jnosql.diana.redis.keyvalue.RedisBucketManagerFactory;
import org.jnosql.diana.redis.keyvalue.RedisConfiguration;
import redis.clients.jedis.JedisPool;
import sh.platform.config.Config;
import sh.platform.config.Redis;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
@ApplicationScoped
class BucketManagerProducer {
private static final String BUCKET = "olympus";
private RedisBucketManagerFactory managerFactory;
@PostConstruct
public void init() {
Config config = new Config();
Redis redis = config.getCredential("redis", Redis::new);
final JedisPool jedisPool = redis.get();
RedisConfiguration configuration = new RedisConfiguration();
managerFactory = configuration.get(jedisPool);
}
@Produces
public BucketManager getManager() {
return managerFactory.getBucketManager(BUCKET);
}
public void destroy(@Disposes BucketManager manager) {
manager.close();
}
}
```
###### MySQL
[MySQL](https://docs.platform.sh/add-services/mysql.md) is an open-source relational database technology, and Jakarta EE supports a robust integration with it: [JPA](https://projects.eclipse.org/projects/ee4j.jpa).
The first step is to choose the database that you would like to use in your project. Define the driver for [MySQL](https://mvnrepository.com/artifact/mysql/mysql-connector-java) and the Java dependencies. Then determine the DataSource client programmatically:
```java
import sh.platform.config.Config;
import sh.platform.config.JPA;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
@ApplicationScoped
class EntityManagerConfiguration {
private EntityManagerFactory entityManagerFactory;
private EntityManager entityManager;
@PostConstruct
void setUp() {
Config config = new Config();
final JPA credential = config.getCredential("postgresql", JPA::new);
entityManagerFactory = credential.getMySQL("jpa-example");
this.entityManager = entityManagerFactory.createEntityManager();
}
@Produces
@ApplicationScoped
EntityManagerFactory getEntityManagerFactory() {
return entityManagerFactory;
}
@Produces
@ApplicationScoped
EntityManager getEntityManager() {
return entityManager;
}
void close(@Disposes EntityManagerFactory entityManagerFactory) {
entityManagerFactory.close();
}
void close(@Disposes EntityManager entityManager) {
entityManager.close();
}
}
```
**Note**:
You can use the same MySQL driver for MariaDB as well if you wish to do so.
###### MariaDB
[MariaDB](https://docs.platform.sh/add-services/mysql.md) is an open-source relational database technology, and Jakarta EE supports a robust integration with it: [JPA](https://projects.eclipse.org/projects/ee4j.jpa).
The first step is to choose the database that you would like to use in your project. Define the driver for [MariaDB](https://mvnrepository.com/artifact/org.mariadb.jdbc/mariadb-java-client) and the Java dependencies. Then determine the DataSource client programmatically:
```java
import sh.platform.config.Config;
import sh.platform.config.JPA;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
@ApplicationScoped
class EntityManagerConfiguration {
private EntityManagerFactory entityManagerFactory;
private EntityManager entityManager;
@PostConstruct
void setUp() {
Config config = new Config();
final JPA credential = config.getCredential("postgresql", JPA::new);
entityManagerFactory = credential.getMariaDB("jpa-example");
this.entityManager = entityManagerFactory.createEntityManager();
}
@Produces
@ApplicationScoped
EntityManagerFactory getEntityManagerFactory() {
return entityManagerFactory;
}
@Produces
@ApplicationScoped
EntityManager getEntityManager() {
return entityManager;
}
void close(@Disposes EntityManagerFactory entityManagerFactory) {
entityManagerFactory.close();
}
void close(@Disposes EntityManager entityManager) {
entityManager.close();
}
}
```
###### PostgreSQL
[PostgreSQL](https://docs.platform.sh/add-services/postgresql.md) is an open-source relational database technology, and Jakarta EE supports a robust integration with it: [JPA](https://projects.eclipse.org/projects/ee4j.jpa).
The first step is to choose the database that you would like to use in your project. Define the driver for [PostgreSQL](https://mvnrepository.com/artifact/postgresql/postgresql) and the Java dependencies. Then determine the DataSource client programmatically:
```java
import sh.platform.config.Config;
import sh.platform.config.JPA;
import javax.annotation.PostConstruct;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
@ApplicationScoped
class EntityManagerConfiguration {
private EntityManagerFactory entityManagerFactory;
private EntityManager entityManager;
@PostConstruct
void setUp() {
Config config = new Config();
final JPA credential = config.getCredential("postgresql", JPA::new);
entityManagerFactory = credential.getPostgreSQL("jpa-example");
entityManager = entityManagerFactory.createEntityManager();
}
@Produces
@ApplicationScoped
EntityManagerFactory getEntityManagerFactory() {
return entityManagerFactory;
}
@Produces
@ApplicationScoped
EntityManager getEntityManager() {
return entityManager;
}
void close(@Disposes EntityManagerFactory entityManagerFactory) {
entityManagerFactory.close();
}
void close(@Disposes EntityManager entityManager) {
entityManager.close();
}
}
```
##### Transaction
To any Eclipse MicroProfile or any non-JTA application is essential to point out, CDI doesn't provide transaction management implementation as part of its specs. Transaction management is left to be implemented by the programmer through the interceptors, such as the code below.
```java
import javax.annotation.Priority;
import javax.inject.Inject;
import javax.interceptor.AroundInvoke;
import javax.interceptor.Interceptor;
import javax.interceptor.InvocationContext;
import javax.persistence.EntityManager;
import javax.persistence.EntityTransaction;
import javax.transaction.Transactional;
@Transactional
@Interceptor
@Priority(Interceptor.Priority.APPLICATION)
public class TransactionInterceptor {
@Inject
private EntityManager manager;
@AroundInvoke
public Object manageTransaction(InvocationContext context) throws Exception {
final EntityTransaction transaction = manager.getTransaction();
transaction.begin();
try {
Object result = context.proceed();
transaction.commit();
return result;
} catch (Exception exp) {
transaction.rollback();
throw exp;
}
}
}
```
To treat this issue, see the [Apache Delta Spike docs](https://deltaspike.apache.org/documentation/jpa.md#_extended_persistence_contexts).
##### Templates
* [Apache TomEE](https://github.com/platformsh-templates/microprofile-tomee)
* [Thorntail](https://github.com/platformsh-templates/microprofile-thorntail)
* [Payara Micro](https://github.com/platformsh-templates/microprofile-payara)
* [KumuluzEE](https://github.com/platformsh-templates/microprofile-kumuluzee)
* [Helidon](https://github.com/platformsh-templates/microprofile-helidon)
* [Open Liberty](https://github.com/platformsh-templates/microprofile-openliberty)
* [Quarkus](https://github.com/platformsh-templates/quarkus)
* [Tomcat](https://github.com/platformsh-templates/tomcat)
* [WildFly](https://github.com/platformsh-templates/microprofile-wildfly/)
### Deploy Micronaut on Platform.sh
[Micronaut](https://micronaut.io/) is an open-source, JVM-based framework for building full-stack, modular, testable microservice and serverless applications.
Unlike reflection-based IoC frameworks that load and cache reflection data for every single field, method, and constructor in your code, with Micronaut, your application startup time and memory consumption aren't bound to the size of your codebase.
Micronaut's cloud support is built right in, including support for common discovery services, distributed tracing tools, and cloud runtimes.
To get Micronaut running on Platform.sh, you have two potential starting places:
- You already have a Micronaut site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic Micronaut site.
- Use a ready-made [Micronaut template](https://github.com/platformsh-templates/micronaut).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Micronaut template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/micronaut/deploy/configure.md)
#### Configure Micronaut for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml
```
Now that you've added these files to your project,
configure each one for Micronaut in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Micronaut requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
Explaining the file line by line, notice the following settings:
- ``name``: The application name.
- ``type`` Where you’ll define the language, in this case, Java, and the version.
- ``disk``: The disk space that the application needs in megabytes.
- ``hooks.build``: The command to package the application.
- ``web.commands``: The order to start the application,
where the port is overwritten using the ``PORT`` environment variable provided by Platform.sh to the application container.
```yaml {location=".platform.app.yaml"}
# This file describes an application. You can have multiple applications
# in the same project.
#
# See https://docs.platform.sh/user_guide/reference/platform-app-yaml.html
# The name of this app. Must be unique within a project.
name: app
# The runtime the application uses.
type: "java:11"
disk: 1024
# The hooks executed at various points in the lifecycle of the application.
hooks:
build: mvn clean package
# The relationships of the application with services or other applications.
#
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
#relationships:
# database: "db:mysql"
# The configuration of app when it is exposed to the web.
web:
commands:
start: java -Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError -jar target/micronaut-1.0-SNAPSHOT.jar
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
Micronaut doesn't require services to deploy, so you don't need a `.platform/services.yaml` file for now.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure Micronaut to use those services once they're enabled.
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Micronaut app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://{default}/":
type: upstream
upstream: "app:http"
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
#### Customize Micronaut for Platform.sh
Now that your code contains all of the configuration to deploy on Platform.sh, it's time to make your Micronaut site itself ready to run on a Platform.sh environment. There are a number of additional steps that are either required or recommended, depending on how well you want to optimize your site.
###### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
Below is an example of how to install the Config Reader for Java using Maven:
```xml
sh.platform
config
2.2.2
```
and Gradle:
```txt
compile group: 'sh.platform', name: 'config', version: '2.2.2'
```
###### `.environment`
The `.platform.app.yaml` file on the [previous page](https://docs.platform.sh/guides/micronaut/deploy/configure.md#configure-apps-in-platformappyaml) has been pulled directly from the [Micronaut template](https://github.com/platformsh-templates/micronaut/blob/master/.platform.app.yaml). It is sufficient to deploy Micronaut on it's own, but since Micronaut makes it possible to overwrite configurations without impacting the application itself, you might elect to rely more heavily on environment variables in it's place.
Consider this simplified `.platform.app.yaml` file:
```yaml {location=".platform.app.yaml"}
name: myapp
type: "java:11"
disk: 1024
hooks:
build: mvn clean package
web:
commands:
start: java -jar $JAVA_OPTS $CREDENTIAL target/file.jar
```
On Platform.sh, we can set the environment variable `JAVA_OPTS` by committing a `.environment` file to the repository's root. Platform.sh runs `source .environment` in the application root when a project starts, and when logging into the environment over SSH.
That gives you a place to do extra environment variable setup before the application runs, including modifying the system `$PATH` and other shell level customizations.
It allows us to define `JAVA_OPTS` when running on Platform.sh, but otherwise not be used during local development testing.
```shell
# .environment
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
To check the Garbage collector settings, please, check the [Java Performance tuning section.](https://docs.platform.sh/languages/java/tuning.md)
#### Deploy Micronaut
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your user files to your local `files/user` directory and your public files to `files/public`
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount src/main/resources/files/user --source ./files/user
platform mount:upload --mount src/main/resources/files/public --source ./files/public
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
Go forth and Deploy (even on Friday)!
#### Additional resources
This guide has hopefully helped you deploy a new Micronaut site, or migrate an existing one, to Platform.sh. It has made a few assumptions to provide the best information to do so, but is by no means a complete reference for your particular application. For this reason, the Platform.sh team maintains and adds to a number of Micronaut guides that can help you add services like Elasticsearch and MongoDB to your application, or how to start using JPA.
Consult those guides below or in the sidebar for more information.
- [Elasticsearch](https://docs.platform.sh/guides/micronaut/elasticsearch.md)
- [JPA](https://docs.platform.sh/guides/micronaut/jpa.md)
- [MongoDB](https://docs.platform.sh/guides/micronaut/mongodb.md)
- [Micronaut Data](https://docs.platform.sh/guides/micronaut/micronaut-data.md)
- [Redis](https://docs.platform.sh/guides/micronaut/redis.md)
[Back](https://docs.platform.sh/guides/micronaut/deploy/deploy.md)
### How to Deploy Micronaut on Platform.sh with Elasticsearch
Micronaut provides two ways of accessing Elasticsearch: via the lower level `RestClient` or via the `RestHighLevelClient`. To initialize Elasticsearch in your project's cluster so that it can be accessed by a Micronaut application, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Micronaut project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/micronaut/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the Elasticsearch service
In your [service configuration](https://docs.platform.sh/add-services.md), include Elasticsearch with a [valid supported version](https://docs.platform.sh/add-services/elasticsearch.md):
.platform/services.yaml
```yaml {}
elasticsearch:
type: elasticsearch:8.5
disk: 256
```
##### 2. Add the Elasticsearch relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `searchelastic` to grant the application access to Elasticsearch via a relationship:
.platform.app.yaml
```yaml {}
relationships:
elasticsearch: "elasticsearch:elasticsearch"
```
##### 3. Export connection credentials to the environment
Connection credentials for Elasticsearch, like any service, are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to Elasticsearch into it's own environment variables that can be used by Micronaut. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export ES_HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".essearch[0].host")
export ES_PORT=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".essearch[0].port")
export ELASTICSEARCH_HTTPHOSTS="http://${ES_HOST}:${ES_PORT}"
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variable names are following the conversion rules of the [Micronaut Documentation](https://docs.micronaut.io/latest/guide/index.md).
##### 4. Connect to Elasticsearch
Commit that code and push. The Elasticsearch instance is ready to be connected from within the Micronaut application.
### How to Deploy Micronaut on Platform.sh with Micronaut Data
[Micronaut Data](https://micronaut-projects.github.io/micronaut-data/latest/guide/) is a database access toolkit that uses Ahead of Time (AoT) compilation to pre-compute queries for repository interfaces that are then executed by a thin, lightweight runtime layer.
**Note**:
This guide only covers the addition of a service configuration to an existing Micronaut project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/micronaut/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add a SQL database service
In your [service configuration](https://docs.platform.sh/add-services.md), include a SQL database service. Make sure to visit the documentation for [that service](https://docs.platform.sh/add-services.md) to find a valid version. For PostgreSQL that would look like:
.platform/services.yaml
```yaml {}
postgresql:
type: postgresql:17
disk: 256
```
##### 2. Grant access to the service through a relationship
To access the new service, set a `relationship` in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
.platform.app.yaml
```yaml {}
relationships:
postgresql: "postgresql:postgresql"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Micronaut. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export JDBC_HOST=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].host"`
export JDBC_PORT=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].port"`
export DATABASE=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].path"`
export DATASOURCES_DEFAULT_PASSWORD=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].password"`
export DATASOURCES_DEFAULT_USERNAME=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].username"`
export DATASOURCES_DEFAULT_URL=jdbc:postgresql://${JDBC_HOST}:${JDBC_PORT}/${DATABASE}
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variable names are following the conversion rules of the [Micronaut Documentation](https://docs.micronaut.io/latest/guide/index.md).
##### 4. Connect to the service
Commit that code and push. The specified cluster will now always point to the PostgreSQL or any SQL service that you wish.
### How to Deploy Micronaut on Platform.sh with MongoDB
To activate MongoDB and then have it accessed by the Micronaut application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a MongoDB service configuration to an existing Micronaut project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/micronaut/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the MongoDB service
In your [service configuration](https://docs.platform.sh/add-services.md), include MongoDB with a [valid supported version](https://docs.platform.sh/add-services/mongodb.md):
```yaml {location=".platform/services.yaml"}
dbmongo:
type: mongodb:3.6
disk: 512
```
##### 2. Grant access to MongoDb through a relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `dbmongo` to grant the application access to MongoDB via a relationship:
.platform.app.yaml
```yaml {}
relationships:
mongodb: "mongodb:mongodb"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Micronaut. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export MONGO_PORT=`echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodb[0].port"`
export MONGO_HOST=`echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodb[0].host"`
export MONGO_PASSWORD=`echo $PLATFORM_RELATIONSHIPS |base64 --decode | jq -r ".mongodb[0].password"`
export MONGO_USER=`echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodb[0].username"`
export MONGO_DATABASE=`echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodb[0].path"`
export MONGO_URL=mongodb://${MONGO_USER}:${MONGO_PASSWORD}@${MONGO_HOST}:${MONGO_PORT}/${MONGO_DATABASE}
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variable names are following the conversion rules of the [Micronaut Documentation](https://docs.micronaut.io/latest/guide/index.md).
##### 4. Connect to the service
Commit that code and push. The application is ready and connected to a MongoDB instance.
### How to Deploy Micronaut on Platform.sh with Redis
To activate Redis and then have it accessed by the Micronaut application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Micronaut project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/micronaut/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the Redis service
In your [service configuration](https://docs.platform.sh/add-services.md), include Persistent Redis with a [valid supported version](https://docs.platform.sh/add-services/redis.md#persistent-redis):
.platform/services.yaml
```yaml {}
data:
type: redis-persistent:8.0
disk: 256
```
##### 2. Add the Redis relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `redisdata` to grant the application access to Elasticsearch via a relationship:
.platform.app.yaml
```yaml {}
relationships:
redisdata: "data:redis"
```
##### 3. Export connection credentials to the environment
Connection credentials for Redis, like any service, are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to Elasticsearch into it's own environment variables that can be used by Micronaut. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export REDIS_HOST=$(echo $PLATFORM_RELATIONSHIPS|base64 --decode|jq -r ".redisdata[0].host")
export REDIS_PORT=$(echo $PLATFORM_RELATIONSHIPS|base64 --decode|jq -r ".redisdata[0].port")
export REDIS_URI=redis://${REDIS_HOST}:${REDIS_PORT}
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variable names are following the conversion rules of the [Micronaut Documentation](https://docs.micronaut.io/latest/guide/index.md).
##### 4. Connect to Redis
Commit that code and push. The Redis instance is ready to be connected from within the Micronaut application.
### How to Deploy Micronoaut on Platform.sh with JPA
To activate JPA and then have it accessed by the Micronoaut application already configured for Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Micronoaut project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/micronaut/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add a SQL database service
In your [service configuration](https://docs.platform.sh/add-services.md), include a SQL database service. Make sure to visit the documentation for [that service](https://docs.platform.sh/add-services.md) to find a valid version. For PostgreSQL that would look like:
.platform/services.yaml
```yaml {}
postgresql:
type: postgresql:17
disk: 256
```
##### 2. Grant access to the service through a relationship
To access the new service, set a `relationship` in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
.platform.app.yaml
```yaml {}
relationships:
postgresql: "postgresql:postgresql"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Micronaut. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export JDBC_HOST=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].host"`
export JDBC_PORT=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].port"`
export DATABASE=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].path"`
export DATASOURCES_DEFAULT_PASSWORD=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].password"`
export DATASOURCES_DEFAULT_USERNAME=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".database[0].username"`
export DATASOURCES_DEFAULT_URL=jdbc:postgresql://${JDBC_HOST}:${JDBC_PORT}/${DATABASE}
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variable names are following the conversion rules of the [Micronaut Documentation](https://docs.micronaut.io/latest/guide/index.md).
##### 4. Connect to the service
Commit that code and push. The specified cluster will now always point to the PostgreSQL or any SQL service that you wish.
### Deploy Quarkus on Platform.sh
[Quarkus](https://quarkus.io/) is, in its own words, a cloud-native, (Linux) container-first framework for writing Java applications.
To get Quarkus running on Platform.sh, you have two potential starting places:
- You already have a Quarkus site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic Quarkus site.
- Use a ready-made [Quarkus template](https://github.com/platformsh-templates/quarkus).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Quarkus template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/quarkus/deploy/configure.md)
#### Configure Quarkus for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml
```
Now that you've added these files to your project,
configure each one for Quarkus in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Quarkus requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
Explaining the file line by line, notice the following settings:
- ``name``: The application name
- ``type`` Where you’ll define the language, in this case, Java, and the version.
- ``disk``: The disk space that the application needs in megabytes.
- ``hooks.build``: The command to package the application
- ``web.commands``: The order to start the application, where the port is overwritten with ``-Dquarkus.http.port=$PORT``,
using the ``PORT`` environment variable provided by Platform.sh to the application container.
```yaml {location=".platform.app.yaml"}
# This file describes an application. You can have multiple applications
# in the same project.
#
# See https://docs.platform.sh/user_guide/reference/platform-app-yaml.html
# The name of this app. Must be unique within a project.
name: app
# The runtime the application uses.
type: "java:11"
disk: 1024
# The hooks executed at various points in the lifecycle of the application.
hooks:
build: ./mvnw package -DskipTests
# The relationships of the application with services or other applications.
#
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
#relationships:
# database: "db:mysql"
# The configuration of app when it is exposed to the web.
web:
commands:
start: java -jar -Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError -Dquarkus.http.port=$PORT target/quarkus-1.0.0-SNAPSHOT-runner.jar
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
Quarkus doesn't require services to deploy, so you don't need a `.platform/services.yaml` file for now.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure Quarkus to use those services once they're enabled.
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Quarkus app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://{default}/":
type: upstream
upstream: "app:http"
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
#### Customize Quarkus for Platform.sh
Now that your code contains all of the configuration to deploy on Platform.sh, it's time to make your Quarkus site itself ready to run on a Platform.sh environment. There are a number of additional steps that are either required or recommended, depending on how well you want to optimize your site.
###### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
Below is an example of how to install the Config Reader for Java using Maven:
```xml
sh.platform
config
2.2.2
```
and Gradle:
```txt
compile group: 'sh.platform', name: 'config', version: '2.2.2'
```
###### `.environment`
The `.platform.app.yaml` file on the [previous page](https://docs.platform.sh/guides/quarkus/deploy/configure.md#configure-apps-in-platformappyaml) has been pulled directly from the [Quarkus template](https://github.com/platformsh-templates/quarkus/blob/master/.platform.app.yaml). It is sufficient to deploy Quarkus on it's own, but since [Eclipse MicroProfile](https://github.com/eclipse/microprofile-config) makes it possible to overwrite configurations without impacting the application itself, you might elect to rely more heavily on environment variables in it's place.
Consider this simplified `.platform.app.yamll` file:
```yaml {location=".platform.app.yaml"}
name: myapp
type: "java:11"
disk: 1024
hooks:
build: ./mvnw package -DskipTests -Dquarkus.package.uber-jar=true
web:
commands:
start: java -jar $JAVA_OPTS $CREDENTIAL -Dquarkus.http.port=$PORT target/file.jar
```
On Platform.sh, we can set the environment variable `JAVA_OPTS` by committing a `.environment` file to the repository's root. Platform.sh runs `source .environment` in the application root when a project starts, and when logging into the environment over SSH.
That gives you a place to do extra environment variable setup before the application runs, including modifying the system `$PATH` and other shell level customizations.
It allows us to define `JAVA_OPTS` when running on Platform.sh, but otherwise not be used during local development testing.
```shell
# .environment
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
To check the Garbage collector settings, please, check the [Java Performance tuning section.](https://docs.platform.sh/languages/java/tuning.md)
#### Deploy Quarkus
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your user files to your local `files/user` directory and your public files to `files/public`
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount src/main/resources/files/user --source ./files/user
platform mount:upload --mount src/main/resources/files/public --source ./files/public
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
Go forth and Deploy (even on Friday)!
#### Additional resources
This guide has hopefully helped you deploy a new Quarkus site, or migrate an existing one, to Platform.sh. It has made a few assumptions to provide the best information to do so, but is by no means a complete reference for your particular application. For this reason, the Platform.sh team maintains and adds to a number of Quarkus guides that can help you add services like Elasticsearch and MongoDB to your application, or how to start using Panache and JPA.
Consult those guides below or in the sidebar for more information.
- [Elasticsearch](https://docs.platform.sh/guides/quarkus/elasticsearch.md)
- [JPA](https://docs.platform.sh/guides/quarkus/jpa.md)
- [MongoDB](https://docs.platform.sh/guides/quarkus/mongodb.md)
- [Panache](https://docs.platform.sh/guides/quarkus/panache.md)
- [Redis](https://docs.platform.sh/guides/quarkus/redis.md)
[Back](https://docs.platform.sh/guides/quarkus/deploy/deploy.md)
### How to Deploy Quarkus on Platform.sh with Elasticsearch
Quarkus provides two ways of accessing Elasticsearch: via the lower level `RestClient` or via the `RestHighLevelClient`. To initialize Elasticsearch in your project's cluster so that it can be accessed by a Quarkus application, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Quarkus project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/quarkus/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the Elasticsearch service
In your [service configuration](https://docs.platform.sh/add-services.md), include Elasticsearch with a [valid supported version](https://docs.platform.sh/add-services/elasticsearch.md):
.platform/services.yaml
```yaml {}
elasticsearch:
type: elasticsearch:8.5
disk: 256
```
##### 2. Add the Elasticsearch relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `searchelastic` to grant the application access to Elasticsearch via a relationship:
.platform.app.yaml
```yaml {}
relationships:
elasticsearch: "elasticsearch:elasticsearch"
```
##### 3. Export connection credentials to the environment
Connection credentials for Elasticsearch, like any service, are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to Elasticsearch into it's own environment variables that can be used by Quarkus. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export ES_HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".essearch[0].host")
export ES_PORT=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".essearch[0].port")
export QUARKUS_HIBERNATE_SEARCH_ELASTICSEARCH_HOSTS=${ES_HOST}:${ES_PORT}
export QUARKUS_HTTP_PORT=$PORT
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variables names are following the conversion rules of [Eclipse MicroProfile](https://github.com/eclipse/microprofile-config/blob/master/spec/src/main/asciidoc/configsources.asciidoc#user-content-default-configsources).
##### 4. Connect to Elasticsearch
Commit that code and push. The Elasticsearch instance is ready to be connected from within the Quarkus application.
### How to Deploy Quarkus on Platform.sh with JPA
Hibernate ORM is a standard [JPA](https://jakarta.ee/specifications/persistence/) implementation. It offers you the full breadth of an Object Relational Mapper and it works well in Quarkus. To activate JPA and then have it accessed by the Quarkus application already configured for Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Quarkus project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/quarkus/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add a SQL database service
In your [service configuration](https://docs.platform.sh/add-services.md), include a SQL database service. Make sure to visit the documentation for [that service](https://docs.platform.sh/add-services.md) to find a valid version. For PostgreSQL that would look like:
.platform/services.yaml
```yaml {}
postgresql:
type: postgresql:17
disk: 256
```
##### 2. Grant access to the service through a relationship
To access the new service, set a `relationship` in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
.platform.app.yaml
```yaml {}
relationships:
postgresql: "postgresql:postgresql"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Quarkus. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].host")
export DATABASE=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].path")
export QUARKUS_DATASOURCE_PASSWORD=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].password")
export QUARKUS_DATASOURCE_USERNAME=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].username")
export QUARKUS_DATASOURCE_JDBC_URL=jdbc:postgresql://${HOST}/${DATABASE}
export QUARKUS_HTTP_PORT=$PORT
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variables names are following the conversion rules of [Eclipse MicroProfile](https://github.com/eclipse/microprofile-config/blob/master/spec/src/main/asciidoc/configsources.asciidoc#user-content-default-configsources).
##### 4. Connect to the service
Commit that code and push. The specified cluster will now always point to the PostgreSQL or any SQL service that you wish.
### How to Deploy Quarkus on Platform.sh with MongoDB
MongoDB with Panache provides active record style entities (and repositories) like you have in [Hibernate ORM with Panache](https://quarkus.io/guides/hibernate-orm-panache). It focuses on helping you write your entities in Quarkus.
To activate MongoDB and then have it accessed by the Quarkus application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a MongoDB service configuration to an existing Quarkus project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/quarkus/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the MongoDB service
In your [service configuration](https://docs.platform.sh/add-services.md), include MongoDB with a [valid supported version](https://docs.platform.sh/add-services/mongodb.md):
```yaml {location=".platform/services.yaml"}
dbmongo:
type: mongodb:3.6
disk: 512
```
##### 2. Grant access to MongoDb through a relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `dbmongo` to grant the application access to MongoDB via a relationship:
.platform.app.yaml
```yaml {}
relationships:
mongodb: "mongodb:mongodb"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Quarkus. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export MONGO_PORT=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodatabase[0].port")
export MONGO_HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodatabase[0].host")
export QUARKUS_MONGODB_HOSTS="${MONGO_HOST}:${MONGO_PORT}"
export QUARKUS_MONGODB_CREDENTIALS_PASSWORD=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodatabase[0].password")
export QUARKUS_MONGODB_CREDENTIALS_USERNAME=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodatabase[0].username")
export QUARKUS_MONGODB_DATABASE=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".mongodatbase[0].path")
export QUARKUS_HTTP_PORT=$PORT
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variables names are following the conversion rules of [Eclipse MicroProfile](https://github.com/eclipse/microprofile-config/blob/master/spec/src/main/asciidoc/configsources.asciidoc#user-content-default-configsources).
##### 4. Connect to the service
Commit that code and push. The application is ready and connected to a MongoDB instance.
### How to Deploy Quarkus on Platform.sh with Panache
Hibernate ORM is a JPA implementation and offers you the full breadth of an Object Relational Mapper. It makes complex mappings possible, but they can sometimes be difficult. Hibernate ORM with Panache focuses on helping you write your entities in Quarkus.
To activate Hibernate Panache and then have it accessed by the Quarkus application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Quarkus project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/quarkus/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add a SQL database service
In your [service configuration](https://docs.platform.sh/add-services.md), include a SQL database service. Make sure to visit the documentation for [that service](https://docs.platform.sh/add-services.md) to find a valid version. For PostgreSQL that would look like:
.platform/services.yaml
```yaml {}
postgresql:
type: postgresql:17
disk: 256
```
##### 2. Grant access to the service through a relationship
To access the new service, set a `relationship` in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
.platform.app.yaml
```yaml {}
relationships:
postgresql: "postgresql:postgresql"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Quarkus. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].host")
export DATABASE=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].path")
export QUARKUS_DATASOURCE_PASSWORD=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].password")
export QUARKUS_DATASOURCE_USERNAME=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".postgresdatabase[0].username")
export QUARKUS_DATASOURCE_JDBC_URL=jdbc:postgresql://${HOST}/${DATABASE}
export QUARKUS_HTTP_PORT=$PORT
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variables names are following the conversion rules of [Eclipse MicroProfile](https://github.com/eclipse/microprofile-config/blob/master/spec/src/main/asciidoc/configsources.asciidoc#user-content-default-configsources).
##### 4. Connect to the service
Commit that code and push. The specified cluster will now always point to the PostgreSQL or any SQL service that you wish.
### How to Deploy Quarkus on Platform.sh with Redis
To activate Redis and then have it accessed by the Quarkus application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Quarkus project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/quarkus/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the Redis service
In your [service configuration](https://docs.platform.sh/add-services.md), include Persistent Redis with a [valid supported version](https://docs.platform.sh/add-services/redis.md#persistent-redis):
.platform/services.yaml
```yaml {}
data:
type: redis-persistent:8.0
disk: 256
```
##### 2. Add the Redis relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `searchelastic` to grant the application access to Elasticsearch via a relationship:
.platform.app.yaml
```yaml {}
relationships:
redisdata: "data:redis"
```
##### 3. Export connection credentials to the environment
Connection credentials for Redis, like any service, are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to Elasticsearch into it's own environment variables that can be used by Quarkus. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export REDIS_HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".redisdata[0].host")
export REDIS_PORT=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".redisdata[0].port")
export QUARKUS_REDIS_HOSTS=redis://${REDIS_HOST}:${REDIS_PORT}
export QUARKUS_HTTP_PORT=$PORT
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
Environment variables names are following the conversion rules of [Eclipse MicroProfile](https://github.com/eclipse/microprofile-config/blob/master/spec/src/main/asciidoc/configsources.asciidoc#user-content-default-configsources).
##### 4. Connect to Redis
Commit that code and push. The Redis instance is ready to be connected from within the Quarkus application.
### Configure Spring with MariaDB/MySQL
[MariaDB/MySQL](https://docs.platform.sh/add-services/mysql.md) is an open-source relational database technology.
Spring has a robust integration with this technology: [Spring Data JPA](https://spring.io/projects/spring-data-jpa).
The first step is to choose the database that you would like to use in your project.
Define the driver for [MariaDB](https://mvnrepository.com/artifact/org.mariadb.jdbc/mariadb-java-client)
or [MySQL](https://mvnrepository.com/artifact/mysql/mysql-connector-java) and the Java dependencies.
Then determine the DataSource client using the [Java configuration reader library](https://github.com/platformsh/config-reader-java).
```java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import sh.platform.config.Config;
import sh.platform.config.MariaDB; // Or substitute "MySQL" for "MariaDB"
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
@Bean(name = "dataSource")
public DataSource getDataSource() {
Config config = new Config();
MariaDB database = config.getCredential("database", MariaDB::new); // Or substitute "MySQL" for "MariaDB"
return database.get();
}
}
```
### Configure Spring with PostgreSQL
[PostgreSQL](https://docs.platform.sh/add-services/postgresql.md) is an open-source relational database technology.
Spring has a robust integration with this technology: [Spring Data JPA](https://spring.io/projects/spring-data-jpa).
The first step is to choose the database that you would like to use in your project.
Define the driver for [PostgreSQL](https://mvnrepository.com/artifact/postgresql/postgresql) and the Java dependencies.
Then determine the DataSource client using the [Java configuration reader library](https://github.com/platformsh/config-reader-java).
```java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import sh.platform.config.Config;
import sh.platform.config.PostgreSQL;
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
@Bean(name = "dataSource")
public DataSource getDataSource() {
Config config = new Config();
PostgreSQL database = config.getCredential("database", PostgreSQL::new);
return database.get();
}
}
```
### Configure Spring with RabbitMQ
You can use [Spring JMS](https://spring.io/guides/gs/messaging-jms/)
to use [RabbitMQ](https://docs.platform.sh/add-services/rabbitmq.md) with your app.
First, determine the MongoDB client using the [Java configuration reader library](https://github.com/platformsh/config-reader-java).
```java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jms.annotation.EnableJms;
import org.springframework.jms.connection.CachingConnectionFactory;
import org.springframework.jms.support.converter.MappingJackson2MessageConverter;
import org.springframework.jms.support.converter.MessageConverter;
import org.springframework.jms.support.converter.MessageType;
import sh.platform.config.Config;
import sh.platform.config.RabbitMQ;
import javax.jms.ConnectionFactory;
@Configuration
@EnableJms
public class JMSConfig {
private ConnectionFactory getConnectionFactory() {
Config config = new Config();
final RabbitMQ rabbitMQ = config.getCredential("rabbitmq", RabbitMQ::new);
return rabbitMQ.get();
}
@Bean
public MessageConverter getMessageConverter() {
MappingJackson2MessageConverter converter = new MappingJackson2MessageConverter();
converter.setTargetType(MessageType.TEXT);
converter.setTypeIdPropertyName("_type");
return converter;
}
@Bean
public CachingConnectionFactory getCachingConnectionFactory() {
ConnectionFactory connectionFactory = getConnectionFactory();
return new CachingConnectionFactory(connectionFactory);
}
}
```
### Configure Spring with Solr
You can use [Spring Data Solr](https://docs.spring.io/spring-data/solr/docs/current/reference/html/#solr.repositories)
for [Solr](https://docs.platform.sh/add-services/solr.md) with your app.
First, determine the Solr client using the [Java configuration reader library](https://github.com/platformsh/config-reader-java).
```java
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.solr.core.SolrTemplate;
import sh.platform.config.Config;
import sh.platform.config.Solr;
@Configuration
public class SolrConfig {
@Bean
public HttpSolrClient elasticsearchTemplate() {
Config config = new Config();
final Solr credential = config.getCredential("solr", Solr::new);
final HttpSolrClient httpSolrClient = credential.get();
String url = httpSolrClient.getBaseURL();
httpSolrClient.setBaseURL(url.substring(0, url.lastIndexOf('/')));
return httpSolrClient;
}
@Bean
public SolrTemplate solrTemplate(HttpSolrClient client) {
return new SolrTemplate(client);
}
}
```
### Deploy Spring on Platform.sh
[Spring](https://start.spring.io/) is, in its own words, a cloud-native, (Linux) container-first framework for writing Java applications.
To get Spring running on Platform.sh, you have two potential starting places:
- You already have a Spring site you are trying to deploy.
Go through this guide to make the recommended changes to your repository to prepare it for Platform.sh.
- You have no code at this point.
If you have no code, you have two choices:
- Generate a basic Spring site.
- Use a ready-made [Spring template](https://github.com/platformsh-templates/spring-mvc-maven-mongodb).
A template is a starting point for building your project.
It should help you get a project ready for production.
To use a template, click the button below to create a Spring template project.

Once the template is deployed, you can follow the rest of this guide
to better understand the extra files and changes to the repository.
##### Before you begin
You need:
- [Git](https://git-scm.com/downloads).
Git is the primary tool to manage everything your app needs to run.
Push commits to deploy changes and control configuration through YAML files.
These files describe your infrastructure, making it transparent and version-controlled.
- A Platform.sh account.
If you don't already have one, [register for a trial account](https://auth.api.platform.sh/register).
You can sign up with an email address or an existing GitHub, Bitbucket, or Google account.
If you choose one of these accounts, you can set a password for your Platform.sh account later.
- The [Platform.sh CLI](https://docs.platform.sh/administration/cli.md).
This lets you interact with your project from the command line.
You can also do most things through the [Web Console](https://docs.platform.sh/administration/web.md).
##### Initialize a project
You can start with a basic code base or push a pre-existing project to Platform.sh.
- Create your first project by running the following command:
```bash {}
platform create --title
```
Then choose the region you want to deploy to, such as the one closest to your site visitors.
You can also select more resources for your project through additional flags,
but a Development plan should be enough for you to get started.
Copy the ID of the project you've created.
- Get your code ready locally.
If your code lives in a remote repository, clone it to your computer.
If your code isn't in a Git repository, initialize it by running ``git init``.
- Connect your Platform.sh project with Git.
You can use Platform.sh as your Git repository or connect to a third-party provider:
GitHub, GitLab, or BitBucket.
That creates an upstream called ``platform`` for your Git repository.
When you choose to use a third-party Git hosting service
the Platform.sh Git repository becomes a read-only mirror of the third-party repository.
All your changes take place in the third-party repository.
Add an integration to your existing third party repository.
The process varies a bit for each supported service, so check the specific pages for each one.
- [BitBucket](https://docs.platform.sh/integrations/source/bitbucket.md)
- [GitHub](https://docs.platform.sh/integrations/source/github.md)
- [GitLab](https://docs.platform.sh/integrations/source/gitlab.md)
Accept the default options or modify to fit your needs.
All of your existing branches are automatically synchronized to Platform.sh.
You get a deploy failure message because you haven’t provided configuration files yet.
You add them in the next step.
If you’re integrating a repository to Platform.sh that contains a number of open pull requests,
don’t use the default integration options.
Projects are limited to three* preview environments (active and deployed branches or pull requests)
and you would need to deactivate them individually to test this guide’s migration changes.
Instead, each service integration should be made with the following flag:
```bash {}
platform integration:add --type= ... --build-pull-requests=false
```
You can then go through this guide and activate the environment when you’re ready to deploy
* You can purchase additional preview environments at any time in the Console.
Open your project and select **Edit plan**.
Add additional **Environments**, view a cost estimate, and confirm your changes.
Now you have a local Git repository, a Platform.sh project, and a way to push code to that project. Next you can configure your project to work with Platform.sh.
[Configure repository](https://docs.platform.sh/guides/spring/deploy/configure.md)
#### Configure Spring for Platform.sh
You now have a *project* running on Platform.sh.
In many ways, a project is just a collection of tools around a Git repository.
Just like a Git repository, a project has branches, called *environments*.
Each environment can then be activated.
*Active* environments are built and deployed,
giving you a fully isolated running site for each active environment.
Once an environment is activated, your app is deployed through a cluster of containers.
You can configure these containers in three ways, each corresponding to a [YAML file](https://docs.platform.sh/learn/overview/yaml):
- **Configure apps** in a `.platform.app.yaml` file.
This controls the configuration of the container where your app lives.
- **Add services** in a `.platform/services.yaml` file.
This controls what additional services are created to support your app,
such as databases or search servers.
Each environment has its own independent copy of each service.
If you're not using any services, you don't need this file.
- **Define routes** in a `.platform/routes.yaml` file.
This controls how incoming requests are routed to your app or apps.
It also controls the built-in HTTP cache.
If you're only using the single default route, you don't need this file.
Start by creating empty versions of each of these files in your repository:
```bash
# Create empty Platform.sh configuration files
mkdir -p .platform && touch .platform/services.yaml && touch .platform/routes.yaml
```
Now that you've added these files to your project,
configure each one for Spring in the following sections.
Each section covers basic configuration options and presents a complete example
with comments on why Spring requires those values.
###### Configure apps in `.platform.app.yaml`
Your app configuration in a `.platform.app.yaml` file is allows you to configure nearly any aspect of your app.
For all of the options, see a [complete reference](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
The following example shows a complete configuration with comments to explain the various settings.
Explaining the file line by line, notice the following settings:
- ``name``: The application name.
- ``type`` Where you define the language, in this case, Java, and the version.
- ``disk``: The disk space that the application needs in megabytes.
- ``hooks.build``: The command to package the application.
- ``web.commands``: The order to start the application, where the port is overwritten with ``--server.port=$PORT``,
using the ``PORT`` environment variable provided by Platform.sh to the application container.
```yaml {location=".platform.app.yaml"}
# This file describes an application. You can have multiple applications
# in the same project.
#
# See https://docs.platform.sh/user_guide/reference/platform-app-yaml.html
# The name of this app. Must be unique within a project.
name: app
# The runtime the application uses.
type: "java:11"
disk: 1024
# The hooks executed at various points in the lifecycle of the application.
hooks:
build: mvn clean package
# The relationships of the application with services or other applications.
#
# The left-hand side is the name of the relationship as it will be exposed
# to the application in the PLATFORM_RELATIONSHIPS variable. The right-hand
# side is in the form `:`.
relationships:
database: "db:mongodb"
# The configuration of app when it is exposed to the web.
web:
commands:
start: java -jar $JAVA_OPTS target/spring-mvc-maven-mongodb.jar --server.port=$PORT
```
###### Add services in `.platform/services.yaml`
You can add the managed services you need for you app to run in the `.platform/services.yaml` file.
You pick the major version of the service and security and minor updates are applied automatically,
so you always get the newest version when you deploy.
You should always try any upgrades on a development branch before pushing to production.
Spring doesn't require services to deploy, so you don't need a `.platform/services.yaml` file for now.
You can [add other services](https://docs.platform.sh/add-services.md) if desired,
such as [Solr](https://docs.platform.sh/add-services/solr.md) or [Elasticsearch](https://docs.platform.sh/add-services/elasticsearch.md).
You need to configure Spring to use those services once they're enabled.
###### Define routes
All HTTP requests sent to your app are controlled through the routing and caching you define in a `.platform/routes.yaml` file.
The two most important options are the main route and its caching rules.
A route can have a placeholder of `{default}`,
which is replaced by your domain name in production and environment-specific names for your preview environments.
The main route has an `upstream`, which is the name of the app container to forward requests to.
You can enable [HTTP cache](https://docs.platform.sh/define-routes/cache.md).
The router includes a basic HTTP cache.
By default, HTTP caches includes all cookies in the cache key.
So any cookies that you have bust the cache.
The `cookies` key allows you to select which cookies should matter for the cache.
You can also set up routes as [HTTP redirects](https://docs.platform.sh/define-routes/redirects.md).
In the following example, all requests to `www.{default}` are redirected to the equivalent URL without `www`.
HTTP requests are automatically redirected to HTTPS.
If you don't include a `.platform/routes.yaml` file, a single default route is used.
This is equivalent to the following:
```yaml {location=".platform/routes.yaml"}
https://{default}/:
type: upstream
upstream: :http
```
Where `` is the `name` you've defined in your [app configuration](#configure-apps-in-platformappyaml).
The following example presents a complete definition of a main route for a Spring app:
```bash {location=".platform/routes.yaml"}
# The routes of the project.
#
# Each route describes how an incoming URL is going
# to be processed by Platform.sh.
"https://{default}/":
type: upstream
upstream: "app:http"
"https://www.{default}/":
type: redirect
to: "https://{default}/"
```
#### Customize Spring for Platform.sh
Now that your code contains all of the configuration to deploy on Platform.sh, it's time to make your Spring site itself ready to run on a Platform.sh environment. There are a number of additional steps that are either required or recommended, depending on how well you want to optimize your site.
###### Install the Config Reader
You can get all information about a deployed environment,
including how to connect to services, through [environment variables](https://docs.platform.sh/development/variables.md).
Your app can [access these variables](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app).
Below is an example of how to install the Config Reader for Java using Maven:
```xml
sh.platform
config
2.2.2
```
and Gradle:
```txt
compile group: 'sh.platform', name: 'config', version: '2.2.2'
```
###### `.environment`
The `.platform.app.yaml` file in the [previous step](https://docs.platform.sh/guides/spring/deploy/configure.md#configure-apps-in-platformappyaml)
has been pulled directly from the [Spring template](https://github.com/platformsh-templates/spring-mvc-maven-mongodb/blob/master/.platform.app.yaml).
It is sufficient to deploy Spring on its own, but since [Spring Config](https://docs.spring.io/spring-boot/docs/current/reference/html/features.md#features.external-config.typesafe-configuration-properties.relaxed-binding.environment-variables)
makes it possible to overwrite configurations without impacting the application itself,
you might elect to rely more heavily on environment variables in its place.
Consider this simplified `.platform.app.yaml` file:
```yaml {location=".platform.app.yaml"}
name: myapp
type: "java:11"
disk: 1024
hooks:
build: mvn clean package
web:
commands:
start: java -jar $JAVA_OPTS target/file.jar --server.port=$PORT
```
On Platform.sh, we can set the environment variable `JAVA_OPTS` by committing a `.environment` file to the repository's root. Platform.sh runs `source .environment` in the application root when a project starts, and when logging into the environment over SSH.
That gives you a place to do extra environment variable setup prior to the application running, including modifying the system `$PATH` and other shell level customizations.
It allows us to define `JAVA_OPTS` when running on Platform.sh, but otherwise not be used during local development testing.
```shell
# .environment
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
To check the Garbage collector settings, please, check the [Java Performance tuning section.](https://docs.platform.sh/languages/java/tuning.md)
#### Deploy Spring
Now you have your configuration for deployment and your app set up to run on Platform.sh.
Make sure all your code is committed to Git
and run `git push` to your Platform.sh environment.
Your code is built, producing a read-only image that's deployed to a running cluster of containers.
If you aren't using a source integration, the log of the process is returned in your terminal.
If you're using a source integration, you can get the log by running `platform activity:log --type environment.push`.
When the build finished, you're given the URL of your deployed environment.
Click the URL to see your site.
If your environment wasn't active and so wasn't deployed, activate it by running the following command:
```bash
platform environment:activate
```
###### Migrate your data
If you are moving an existing site to Platform.sh, then in addition to code you also need to migrate your data.
That means your database and your files.
####### Import the database
First, obtain a database dump from your current site,
such as using the
* [`pg_dump` command for PostgreSQL](https://www.postgresql.org/docs/current/app-pgdump.md)
* [`mysqldump` command for MariaDB](https://mariadb.com/kb/en/mysqldump/)
* [`sqlite-dump` command for SQLite](https://www.sqlitetutorial.net/sqlite-dump/)
Next, import the database into your Platform.sh site by running the following command:
```bash
platform sql < dump.sql
```
That connects to the database service through an SSH tunnel and imports the SQL.
####### Import files
First, download your files from your current hosting environment.
The easiest way is likely with rsync, but consult your host's documentation.
This guide assumes that you have already downloaded
all of your user files to your local `files/user` directory and your public files to `files/public`
, but adjust accordingly for their actual locations.
Next, upload your files to your mounts
using the `platform mount:upload` command.
Run the following command from your local Git repository root,
modifying the `--source` path if needed.
```bash
platform mount:upload --mount src/main/resources/files/user --source ./files/user
platform mount:upload --mount src/main/resources/files/public --source ./files/public
```
This uses an SSH tunnel and rsync to upload your files as efficiently as possible.
Note that rsync is picky about its trailing slashes, so be sure to include those.
You've now added your files and database to your Platform.sh environment.
When you make a new branch environment off of it,
all of your data is fully cloned to that new environment
so you can test with your complete dataset without impacting production.
Go forth and Deploy (even on Friday)!
#### Additional resources
This guide has hopefully helped you deploy a new Spring site, or migrate an existing one, to Platform.sh. It has made a few assumptions to provide the best information to do so, but is by no means a complete reference for your particular application. For this reason, the Platform.sh team maintains and adds to a number of Spring guides that can help you add services like Elasticsearch and MongoDB to your application, or how to start using Panache and JPA.
Consult those guides below or in the sidebar for more information.
- [Elasticsearch](https://docs.platform.sh/guides/spring/elasticsearch.md)
- [JPA](https://docs.platform.sh/guides/spring/jpa.md)
- [MongoDB](https://docs.platform.sh/guides/spring/mongodb.md)
- [Redis](https://docs.platform.sh/guides/spring/redis.md)
[Back](https://docs.platform.sh/guides/spring/deploy/deploy.md)
### How to Deploy Spring on Platform.sh with Elasticsearch
To activate Elasticsearch and then have it accessed by the Spring application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Spring project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/spring/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the Elasticsearch service
In your [service configuration](https://docs.platform.sh/add-services.md), include Elasticsearch with a [valid supported version](https://docs.platform.sh/add-services/elasticsearch.md):
.platform/services.yaml
```yaml {}
elasticsearch:
type: elasticsearch:8.5
disk: 256
```
##### 2. Add the Elasticsearch relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `searchelastic` to grant the application access to Elasticsearch via a relationship:
.platform.app.yaml
```yaml {}
relationships:
elasticsearch: "elasticsearch:elasticsearch"
```
##### 3. Export connection credentials to the environment
Connection credentials for Elasticsearch, like any service, are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to Elasticsearch into it's own environment variables that can be used by Spring. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export ES_HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".essearch[0].host")
export ES_PORT=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".essearch[0].port")
export SPRING_ELASTICSEARCH_REST_URIS="http://${ES_HOST}:${ES_PORT}"
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
For access to more credentials options, check [Spring common application properties](https://docs.spring.io/spring-boot/docs/current/reference/html/application-properties.md)
and [binding from environment variables](https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.md#features.external-config.typesafe-configuration-properties.relaxed-binding.environment-variables).
##### 4. Connect to Elasticsearch
Commit that code and push. The Elasticsearch instance is ready to be connected from within the Spring application.
### How to Deploy Spring on Platform.sh with JPA
To activate JPA and then have it accessed by the Spring application already configured for Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Spring project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/spring/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add a SQL database service
In your [service configuration](https://docs.platform.sh/add-services.md), include a SQL database service with a [valid supported version](https://docs.platform.sh/add-services.md) to find a valid version. For PostgreSQL that would look like:
.platform/services.yaml
```yaml {}
postgresql:
type: postgresql:17
disk: 256
```
##### 2. Grant access to the service through a relationship
To access the new service, set a `relationship` in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
.platform.app.yaml
```yaml {}
relationships:
postgresql: "postgresql:postgresql"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Spring. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export DB_PORT=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".postgresdatabase[0].port"`
export HOST=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".postgresdatabase[0].host"`
export DATABASE=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".postgresdatabase[0].path"`
export SPRING_DATASOURCE_URL="jdbc:mysql://${HOST}:${DB_PORT}/${DATABASE}"
export SPRING_DATASOURCE_USERNAME=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".postgresdatabase[0].username"`
export SPRING_DATASOURCE_PASSWORD=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".postgresdatabase[0].password"`
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
For access to more credentials options, check [Spring common application properties](https://docs.spring.io/spring-boot/docs/current/reference/html/application-properties.md)
and [binding from environment variables](https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.md#features.external-config.typesafe-configuration-properties.relaxed-binding.environment-variables).
##### 4. Connect to the service
Commit that code and push.
The specified cluster now always points to the PostgreSQL or any SQL service that you wish.
### How to Deploy Spring on Platform.sh with MongoDB
To activate MongoDB and then have it accessed by the Spring application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a MongoDB service configuration to an existing Spring project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/spring/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the MongoDB service
In your [service configuration](https://docs.platform.sh/add-services.md), include MongoDB with a [valid supported version](https://docs.platform.sh/add-services/mongodb.md):
```yaml {location=".platform/services.yaml"}
dbmongo:
type: mongodb:3.6
disk: 512
```
##### 2. Grant access to MongoDb through a relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `dbmongo` to grant the application access to MongoDB via a relationship:
.platform.app.yaml
```yaml {}
relationships:
mongodb: "mongodb:mongodb"
```
##### 3. Export connection credentials to the environment
Connection credentials for services are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to the database into it's own environment variables that can be used by Spring. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export SPRING_DATA_MONGODB_USERNAME=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".dbmongo[0].username"`
export SPRING_DATA_MONGODB_PASSWORD=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".dbmongo[0].password"`
export SPRING_DATA_MONGODB_HOST=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".dbmongo[0].host"`
export SPRING_DATA_MONGODB_DATABASE=`echo $PLATFORM_RELATIONSHIPS|base64 -d|jq -r ".dbmongo[0].path"`
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
For access to more credentials options, check [Spring common application properties](https://docs.spring.io/spring-boot/docs/current/reference/html/application-properties.md)
and [binding from environment variables](https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.md#features.external-config.typesafe-configuration-properties.relaxed-binding.environment-variables).
##### 4. Connect to the service
Commit that code and push. The application is ready and connected to a MongoDB instance.
##### Use Spring Data for MongoDB
You can use [Spring Data MongoDB](https://spring.io/projects/spring-data-mongodb) to use MongoDB with your app.
First, determine the MongoDB client using the [Java configuration reader library](https://github.com/platformsh/config-reader-java).
```java
import com.mongodb.MongoClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.mongodb.config.AbstractMongoConfiguration;
import sh.platform.config.Config;
import sh.platform.config.MongoDB;
@Configuration
public class MongoConfig extends AbstractMongoConfiguration {
private Config config = new Config();
@Override
@Bean
public MongoClient mongoClient() {
MongoDB mongoDB = config.getCredential("database", MongoDB::new);
return mongoDB.get();
}
@Override
protected String getDatabaseName() {
return config.getCredential("database", MongoDB::new).getDatabase();
}
}
```
### How to Deploy Spring on Platform.sh with Redis
To activate Redis and then have it accessed by the Spring application already in Platform.sh, it is necessary to modify two files.
**Note**:
This guide only covers the addition of a service configuration to an existing Spring project already configured to deploy on Platform.sh. Please see the [deployment guide](https://docs.platform.sh/guides/spring/deploy.md) for more detailed instructions for setting up app containers and initial projects.
##### 1. Add the Redis service
In your [service configuration](https://docs.platform.sh/add-services.md),
include persistent Redis with a [valid supported version](https://docs.platform.sh/add-services/redis.md#persistent-redis):
.platform/services.yaml
```yaml {}
data:
type: redis-persistent:8.0
disk: 256
```
##### 2. Add the Redis relationship
In your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), use the service name `searchelastic` to grant the application access to Elasticsearch via a relationship:
.platform.app.yaml
```yaml {}
relationships:
redisdata: "data:redis"
```
##### 3. Export connection credentials to the environment
Connection credentials for Redis, like any service, are exposed to the application container through the `PLATFORM_RELATIONSHIPS` environment variable from the deploy hook onward. Since this variable is a base64 encoded JSON object of all of your project's services, you'll likely want a clean way to extract the information specific to Elasticsearch into it's own environment variables that can be used by Spring. On Platform.sh, custom environment variables can be defined programmatically in a `.environment` file using `jq` to do just that:
```text
export SPRING_REDIS_HOST=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".redisdata[0].host")
export SPRING_REDIS_PORT=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq -r ".redisdata[0].port")
export JAVA_OPTS="-Xmx$(jq .info.limits.memory /run/config.json)m -XX:+ExitOnOutOfMemoryError"
```
**Tip**:
For access to more credentials options, check [Spring common application properties](https://docs.spring.io/spring-boot/docs/current/reference/html/application-properties.md)
and [binding from environment variables](https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.md#features.external-config.typesafe-configuration-properties.relaxed-binding.environment-variables).
##### 4. Connect to Redis
Commit that code and push. The Redis instance is ready to be connected from within the Spring application.
##### Use Spring Data for Redis
You can use [Spring Data Redis](https://spring.io/projects/spring-data-mongodb) to use Redis with your app.
First, determine the MongoDB client using the [Java configuration reader library](https://github.com/platformsh/config-reader-java).
```java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericToStringSerializer;
@Configuration
public class RedisConfig {
@Bean
JedisConnectionFactory jedisConnectionFactory() {
Config config = new Config();
RedisSpring redis = config.getCredential("redis", RedisSpring::new);
return redis.get();
}
@Bean
public RedisTemplate redisTemplate() {
final RedisTemplate template = new RedisTemplate();
template.setConnectionFactory(jedisConnectionFactory());
template.setValueSerializer(new GenericToStringSerializer(Object.class));
return template;
}
}
```
## Reference
### App reference
To define your app, you can either use one of Platform.sh's [single-runtime image](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md)
or its [composable image (BETA)](https://docs.platform.sh/create-apps/app-reference/composable-image.md).
##### Single-runtime image
Platform.sh provides and maintains a list of single-runtime images you can use for each of your application containers.
See [all of the options you can use](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md) to define your app using a single-runtime image.
##### Composable image (BETA)
The Platform.sh composable image provides more flexibility than single-runtime images.
When using a composable image, you can define a stack (or group of packages) for your application container to use.
There are over 80,000 packages available from the [Nix Packages collection](https://search.nixos.org/) that you can add to your stack.
You can add as many packages to your application container as you need.
**Note**:
Platform.sh guarantees optimal user experience with the specific [set of packages](https://docs.platform.sh/create-apps/app-reference/composable-image.md#supported-nix-packages) it supports.
You can use any other package available from the [Nix Packages collection](https://search.nixos.org/), including unstable ones,
but NixOs is responsible for their support.
See [all of the options you can use](https://docs.platform.sh/create-apps/app-reference/composable-image.md) to define your app using the composable image.
#### Single-runtime image
See all of the options for controlling your apps and how they’re built and deployed on Platform.sh.
For single-app projects, the configuration is all done in a `.platform.app.yaml` file,
usually located at the root of your app folder in your Git repository.
[Multi-app projects](https://docs.platform.sh/create-apps/multi-app.md) can be set up in various ways.
See a [comprehensive example](https://docs.platform.sh/create-apps.md#comprehensive-example) of a configuration in a `.platform.app.yaml` file.
For reference, see a [log of changes to app configuration](https://docs.platform.sh/create-apps/upgrading.md).
###### Top-level properties
The following table presents all properties available at the top level of the YAML for the app.
The column _Set in instance?_ defines whether the given property can be overridden within a `web` or `workers` instance.
To override any part of a property, you have to provide the entire property.
| Name | Type | Required | Set in instance? | Description |
|--------------------|--------------------------------------------------------------------------|----------|------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `name` | `string` | Yes | No | A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated with the app. |
| `type` | A [type](#types) | Yes | No | The base image to use with a specific app language. Format: `runtime:version`. |
| `size` | A [size](#sizes) | | Yes | How much resources to devote to the app. Defaults to `AUTO` in production environments. |
| `relationships` | A dictionary of [relationships](#relationships) | | Yes | Connections to other services and apps. |
| `disk` | `integer` or `null` | | Yes | The size of the disk space for the app in [MB](https://docs.platform.sh/glossary.md#mb). Minimum value is `128`. Defaults to `null`, meaning no disk is available. See [note on available space](#available-disk-space) |
| `mounts` | A dictionary of [mounts](#mounts) | | Yes | Directories that are writable even after the app is built. If set as a local source, `disk` is required. |
| `web` | A [web instance](#web) | | N/A | How the web application is served. |
| `workers` | A [worker instance](#workers) | | N/A | Alternate copies of the application to run as background processes. |
| `timezone` | `string` | | No | The timezone for crons to run. Format: a [TZ database name](https://en.wikipedia.org/wiki/List_of_tz_database_time_zones). Defaults to `UTC`, which is the timezone used for all logs no matter the value here. See also [app runtime timezones](https://docs.platform.sh/create-apps/timezone.md) |
| `access` | An [access dictionary](#access) | | Yes | Access control for roles accessing app environments. |
| `variables` | A [variables dictionary](#variables) | | Yes | Variables to control the environment. |
| `firewall` | A [firewall dictionary](#firewall) | | Yes | Outbound firewall rules for the application. |
| `build` | A [build dictionary](#build) | | No | What happens when the app is built. |
| `dependencies` | A [dependencies dictionary](#dependencies) | | No | What global dependencies to install before the `build` hook is run. |
| `hooks` | A [hooks dictionary](#hooks) | | No | What commands run at different stages in the build and deploy process. |
| `crons` | A [cron dictionary](#crons) | | No | Scheduled tasks for the app. |
| `source` | A [source dictionary](#source) | | No | Information on the app's source code and operations that can be run on it. |
| `runtime` | A [runtime dictionary](#runtime) | | No | Customizations to your PHP runtime. |
| `additional_hosts` | An [additional hosts dictionary](#additional-hosts) | | Yes | Maps of hostnames to IP addresses. |
| `operations` | A [dictionary of Runtime operations](https://docs.platform.sh/create-apps/runtime-operations.md) | | No | Runtime operations for the application. |
###### Root directory
Some of the properties you can define are relative to your app's root directory.
The root defaults to the location of your `.platform.app.yaml` file.
That is, if a custom value for `source.root` is not provided in your configuration, the default behavior is equivalent to the above.
To specify another directory, for example for a [multi-app project](https://docs.platform.sh/create-apps/multi-app.md),
use the [`source.root` property](#source).
###### Types
**Note**:
You can now use the Platform.sh composable image (BETA) to install runtimes and tools in your application container.
If you’ve reached this section from another page, you may be interested in supported ``stacks`` where ``type`` was referenced.
See [supported Nix packages for the ](https://docs.platform.sh/create-apps/app-reference/composable-image.md#supported-nix-packages) for more information.
The `type` defines the base container image used to run the application.
The version is the major (`X`) and sometimes minor (`X.Y`) version numbers,
depending on the service, as in the following table.
Security and other patches are taken care of for you automatically.
Available languages and their supported versions:
| **Language** | **``runtime``** | **Supported ``version``** |
| [C#/.Net Core](https://docs.platform.sh/languages/dotnet.md) | ``dotnet`` | 7.0, 6.0, 8.0 |
| [Elixir](https://docs.platform.sh/languages/elixir.md) | ``elixir`` | 1.18, 1.15, 1.14 |
| [Go](https://docs.platform.sh/languages/go.md) | ``golang`` | 1.24, 1.23, 1.22, 1.21, 1.20 |
| [Java](https://docs.platform.sh/languages/java.md) | ``java`` | 21, 19, 18, 17, 11, 8 |
| [JavaScript/Node.js](https://docs.platform.sh/languages/nodejs.md) | ``nodejs`` | 22, 20, 18 |
| [PHP](https://docs.platform.sh/languages/php.md) | ``php`` | 8.4, 8.3, 8.2, 8.1 |
| [Python](https://docs.platform.sh/languages/python.md) | ``python`` | 3.13, 3.12, 3.11, 3.10, 3.9, 3.8 |
| [Ruby](https://docs.platform.sh/languages/ruby.md) | ``ruby`` | 3.4, 3.3, 3.2, 3.1, 3.0 |
| [Rust](https://docs.platform.sh/languages/rust.md) | ``rust`` | 1 |
####### Example configuration
These are used in the format `runtime:version`:
```yaml {location=".platform.app.yaml"}
type: 'php:8.4'
```
###### Sizes
Resources are distributed across all containers in an environment from the total available from your [plan size](https://docs.platform.sh/administration/pricing.md).
So if you have more than just a single app, it doesn't get all of the resources available.
Each environment has its own resources and there are different [sizing rules for preview environments](#sizes-in-preview-environments).
By default, resource sizes (CPU and memory) are chosen automatically for an app
based on the plan size and the number of other containers in the cluster.
Most of the time, this automatic sizing is enough.
You can set sizing suggestions for production environments when you know a given container has specific needs.
Such as a worker that doesn't need much and can free up resources for other apps.
To do so, set `size` to one of the following values:
- `S`
- `M`
- `L`
- `XL`
- `2XL`
- `4XL`
The total resources allocated across all apps and services can't exceed what's in your plan.
####### Container profiles: CPU and memory
By default, Platform.sh allocates a container profile to each app and service depending on:
- The range of resources it’s expected to need
- Your [plan size](https://docs.platform.sh/administration/pricing.md), as resources are distributed across containers.
Ideally you want to give databases the biggest part of your memory, and apps the biggest part of your CPU.
The container profile and the [size of the container](#sizes) determine
how much CPU and memory (in [MB](https://docs.platform.sh/glossary.md#mb)) the container gets.
There are three container profiles available: ``HIGH_CPU``, ``BALANCED``, and ``HIGH_MEMORY``.
######## ``HIGH_CPU`` container profile
| Size | CPU | MEMORY |
| ---- | ----- | -------- |
| S | 0.40 | 128 MB |
| M | 0.40 | 128 MB |
| L | 1.20 | 256 MB |
| XL | 2.50 | 384 MB |
| 2XL | 5.00 | 768 MB |
| 4XL | 10.00 | 1536 MB |
######## `BALANCED` container profile
| Size | CPU | MEMORY |
| ---- | ---- | -------- |
| S | 0.05 | 32 MB |
| M | 0.05 | 64 MB |
| L | 0.08 | 256 MB |
| XL | 0.10 | 512 MB |
| 2XL | 0.20 | 1024 MB |
| 4XL | 0.40 | 2048 MB |
######## `HIGH_MEMORY` container profile
| Size | CPU | MEMORY |
| ---- | ---- | --------- |
| S | 0.25 | 128 MB |
| M | 0.25 | 288 MB |
| L | 0.40 | 1280 MB |
| XL | 0.75 | 2624 MB |
| 2XL | 1.50 | 5248 MB |
| 4XL | 3.00 | 10496 MB |
######## Container profile reference
The following table shows which container profiles Platform.sh applies when deploying your project.
| Container | Profile |
|-----------------------|-------------|
| Chrome Headless | HIGH_CPU |
| .NET | HIGH_CPU |
| Elasticsearch | HIGH_MEMORY |
| Elasticsearch Premium | HIGH_MEMORY |
| Elixir | HIGH_CPU |
| Go | HIGH_CPU |
| Gotenberg | HIGH_MEMORY |
| InfluxDB | HIGH_MEMORY |
| Java | HIGH_MEMORY |
| Kafka | HIGH_MEMORY |
| MariaDB | HIGH_MEMORY |
| Memcached | BALANCED |
| MongoDB | HIGH_MEMORY |
| MongoDB Premium | HIGH_MEMORY |
| Network Storage | HIGH_MEMORY |
| Node.js | HIGH_CPU |
| OpenSearch | HIGH_MEMORY |
| Oracle MySQL | HIGH_MEMORY |
| PHP | HIGH_CPU |
| PostgreSQL | HIGH_MEMORY |
| Python | HIGH_CPU |
| RabbitMQ | HIGH_MEMORY |
| Redis ephemeral | BALANCED |
| Redis persistent | BALANCED |
| Ruby | HIGH_CPU |
| Rust | HIGH_CPU |
| Solr | HIGH_MEMORY |
| Varnish | HIGH_MEMORY |
| Vault KMS | HIGH_MEMORY |
####### Sizes in preview environments
Containers in preview environments don't follow the `size` specification.
Application containers are set based on the plan's setting for **Environments application size**.
The default is size **S**, but you can increase it by editing your plan.
(Service containers in preview environments are always set to size **S**.)
###### Relationships
To allow containers in your project to communicate with one another,
you need to define relationships between them.
You can define a relationship between an app and a service, or [between two apps](https://docs.platform.sh/create-apps/multi-app/relationships.md).
The quickest way to define a relationship between your app and a service
is to use the service's default endpoint.
However, some services allow you to define multiple databases, cores, and/or permissions.
In these cases, you can't rely on default endpoints.
Instead, you can explicitly define multiple endpoints when setting up your relationships.
**Note**:
App containers don’t have a default endpoint like services.
To connect your app to another app in your project,
you need to explicitly define the ``http`` endpoint as the endpoint to connect both apps.
For more information, see how to [define relationships between your apps](https://docs.platform.sh/create-apps/multi-app/relationships.md).
**Availability**:
New syntax (default and explicit endpoints) described below is supported by most, but not all, image types
(``Relationship 'SERVICE_NAME' of application 'myapp' ... targets a service without a valid default endpoint configuration.``).
This syntax is currently being rolled out for all images.
If you encounter this error, use the “legacy” Platform.sh configuration noted at the bottom of this section.
To define a relationship between your app and a service:
```yaml {}
relationships:
:
```
The ``SERVICE_NAME`` is the name of the service as defined in its [configuration](https://docs.platform.sh/add-services.md).
It is used as the relationship name, and associated with a ``null`` value.
This instructs Platform.sh to use the service’s default endpoint to connect your app to the service.
For example, if you define the following configuration:
.platform.app.yaml
```yaml {}
relationships:
mariadb:
```
Platform.sh looks for a service named ``mariadb`` in your ``.platform/services.yaml`` file,
and connects your app to it through the service’s default endpoint.
For reference, the equivalent configuration using explicit endpoints would be the following:
.platform.app.yaml
```yaml {}
relationships:
mariadb:
service: mariadb
endpoint: mysql
```
You can define any number of relationships in this way:
.platform.app.yaml
```yaml {}
relationships:
mariadb:
redis:
elasticsearch:
```
**Tip**:
An even quicker way to define many relationships is to use the following single-line configuration:
.platform.app.yaml
```yaml {}
relationships: {, , }
```
where
.platform/services.yaml
```yaml {}
:
type: mariadb:11.8
disk: 256
:
type: redis:8.0
disk: 256
:
type: elasticsearch:8.5
disk: 256
```
Use the following configuration:
.platform.app.yaml
```yaml {}
relationships:
:
service:
endpoint:
```
- ``RELATIONSHIP_NAME`` is the name you want to give to the relationship.
- ``SERVICE_NAME`` is the name of the service as defined in its [configuration](https://docs.platform.sh/add-services.md).
- ``ENDPOINT_NAME`` is the endpoint your app will use to connect to the service (refer to the service reference to know which value to use).
For example, to define a relationship named ``database`` that connects your app to a service called ``mariadb`` through the ``db1`` endpoint,
use the following configuration:
.platform.app.yaml
```yaml {}
relationships:
database: # The name of the relationship.
service: mariadb
endpoint: db1
```
For more information on how to handle multiple databases, multiple cores,
and/or different permissions with services that support such features,
see each service’s dedicated page:
- [MariaDB/MySQL](https://docs.platform.sh/add-services/mysql.md#multiple-databases) (multiple databases and permissions)
- [PostgreSQL](https://docs.platform.sh/add-services/postgresql.md#multiple-databases) (multiple databases and permissions)
- [Redis](https://docs.platform.sh/add-services/redis.md#multiple-databases) (multiple databases)
- [Solr](https://docs.platform.sh/add-services/solr.md#solr-6-and-later) (multiple cores)
- [Vault KMS](https://docs.platform.sh/add-services/vault.md#multiple-endpoints-configuration) (multiple permissions)
You can add as many relationships as you want to your app configuration,
using both default and explicit endpoints according to your needs:
.platform.app.yaml
```yaml {}
relationships:
database1:
service: mariadb
endpoint: admin
database2:
service: mariadb
endpoint: legacy
cache:
service: redis
search:
service: elasticsearch
```
**Legacy**:
The following legacy syntax for specifying relationships is still supported by Platform.sh:
.platform.app.yaml
```yaml {}
relationships:
: ":"
```
For example:
.platform.app.yaml
```yaml {}
relationships:
database: "mariadb:mysql"
```
Feel free to use this until the default and explicit endpoint syntax is supported on all images.
###### Available disk space
The maximum total space available to all apps and services is set by the storage in your plan settings.
When deploying your project, the sum of all `disk` keys defined in app and service configurations
must be *equal or less* than the plan storage size.
So if your *plan storage size* is 5 GB, you can, for example, assign it in one of the following ways:
- 2 GB to your app, 3 GB to your database
- 1 GB to your app, 4 GB to your database
- 1 GB to your app, 1 GB to your database, 3 GB to your OpenSearch service
If you exceed the total space available, you receive an error on pushing your code.
You need to either increase your plan's storage or decrease the `disk` values you've assigned.
You configure the disk size in [MB](https://docs.platform.sh/glossary.md#mb). Your actual available disk space is slightly smaller with some space used for formatting and the filesystem journal. When checking available space, note whether it’s reported in MB or MiB.
####### Downsize a disk
You can decrease the size of an existing disk for an app. If you do so, be aware that:
- Backups from before the downsize are incompatible and can no longer be used. You need to [create new backups](https://docs.platform.sh/environments/backup.md).
- The downsize fails if there’s more data on the disk than the desired size.
###### Mounts
After your app is built, its file system is read-only.
To make changes to your app's code, you need to use Git.
For enhanced flexibility, Platform.sh allows you to define and use writable directories called "mounts".
Mounts give you write access to files generated by your app (such as cache and log files)
and uploaded files without going through Git.
When you define a mount, you are mounting an external directory to your app container,
much like you would plug a hard drive into your computer to transfer data.
**Note**:
- Mounts aren’t available during the build
- When you [back up an environment](https://docs.platform.sh/environments/backup.md), the mounts on that environment are backed up too
####### Define a mount
To define a mount, use the following configuration:
```yaml {location=".platform.app.yaml"}
mounts:
'':
source:
source_path:
```
is the path to your mount **within the app container** (relative to the app's root).
If you already have a directory with that name, you get a warning that it isn't accessible after the build.
See how to [troubleshoot the warning](https://docs.platform.sh/create-apps/troubleshoot-mounts.md#overlapping-folders).
| Name | Type | Required | Description |
| ------------- |-------------------------------| -------- |----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `source` | `local`, `service`, or `tmp` | Yes | Specifies the type of the mount: - `local` mounts are unique to your app. They can be useful to store files that remain local to the app instance, such as application logs. `local` mounts require disk space. To successfully set up a local mount, set the `disk` key in your app configuration. - `service` mounts point to [Network Storage](https://docs.platform.sh/add-services/network-storage.md) services that can be shared between several apps. - `tmp` mounts are local ephemeral mounts, where an external directory is mounted to the `/tmp` directory of your app. The content of a `tmp` mount **may be removed during infrastructure maintenance operations**. Therefore, `tmp` mounts allow you to **store files that you’re not afraid to lose**, such as your application cache that can be seamlessly rebuilt. Note that the `/tmp` directory has **a maximum allocation of 8 GB**. |
| `source_path` | `string` | No | Specifies where the mount points **inside the [external directory](#mounts)**. - If you explicitly set a `source_path`, your mount points to a specific subdirectory in the external directory. - If the `source_path` is an empty string (`""`), your mount points to the entire external directory. - If you don't define a `source_path`, Platform.sh uses the as default value, without leading or trailing slashes. For example, if your mount lives in the `/web/uploads/` directory in your app container, it will point to a directory named `web/uploads` in the external directory. **WARNING:** Changing the name of your mount affects the `source_path` when it's undefined. See [how to ensure continuity](#ensure-continuity-when-changing-the-name-of-your-mount) and maintain access to your files. |
| `service` | `string` | | Only for `service` mounts: the name of the [Network Storage service](https://docs.platform.sh/add-services/network-storage.md). |
The accessibility to the web of a mounted directory depends on the [`web.locations` configuration](#web).
Files can be all public, all private, or with different rules for different paths and file types.
Note that when you remove a `local` mount from your `.platform.app.yaml` file,
the mounted directory isn't deleted.
The files still exist on disk until manually removed
(or until the app container is moved to another host during a maintenance operation in the case of a `tmp` mount).
####### Example configuration
```yaml {location=".platform.app.yaml"}
mounts:
'web/uploads':
source: local
source_path: uploads
'/.tmp_platformsh':
source: tmp
source_path: files/.tmp_platformsh
'/build':
source: local
source_path: files/build
'/.cache':
source: tmp
source_path: files/.cache
'/node_modules/.cache':
source: tmp
source_path: files/node_modules/.cache
```
For examples of how to set up a `service` mount, see the dedicated [Network Storage page](https://docs.platform.sh/add-services/network-storage.md).
####### Ensure continuity when changing the name of your mount
Changing the name of your mount affects the default `source_path`.
Say you have a `/my/cache/` mount with an undefined `source_path`:
```yaml {location=".platform.app.yaml"}
mounts:
'/my/cache/':
source: tmp
```
If you rename the mount to `/cache/files/`, it will point to a new, empty `/cache/files/` directory.
To ensure continuity, you need to explicitly define the `source_path` as the previous name of the mount, without leading or trailing slashes:
```yaml {location=".platform.app.yaml"}
mounts:
'/cache/files/':
source: tmp
source_path: my/cache
```
The `/cache/files/` mount will point to the original `/my/cache/` directory, maintaining access to all your existing files in that directory.
####### Overlapping mounts
The locations of mounts as they are visible to application containers can overlap somewhat.
For example:
```yaml {location=".platform/applications.yaml"}
applications:
myapp:
# ...
mounts:
'var/cache_a':
source: service
service: ns_service
source_path: cacheA
'var/cache_b':
source: tmp
source_path: cacheB
'var/cache_c':
source: local
source_path: cacheC
```
In this case, it does not matter that each mount is of a different `source` type.
Each mount is restricted to a subfolder within `var`, and all is well.
The following, however, is not allowed and will result in a failure:
```yaml {location=".platform/applications.yaml"}
applications:
myapp:
# ...
mounts:
'var/':
source: service
service: ns_service
source_path: cacheA
'var/cache_b':
source: tmp
source_path: cacheB
'var/cache_c':
source: local
source_path: cacheC
```
The `service` mount type specifically exists to share data between instances of the same application, whereas `tmp` and `instance` are meant to restrict data to build time and runtime of a single application instance, respectively.
These allowances are not compatible, and will result in an error if pushed.
###### Web
Use the `web` key to configure the web server running in front of your app.
Defaults may vary with a different [image `type`](#types).
| Name | Type | Required | Description |
|-------------|--------------------------------------------|-------------------------------|------------------------------------------------------|
| `commands` | A [web commands dictionary](#web-commands) | See [note](#required-command) | The command to launch your app. |
| `upstream` | An [upstream dictionary](#upstream) | | How the front server connects to your app. |
| `locations` | A [locations dictionary](#locations) | | How the app container responds to incoming requests. |
See some [examples of how to configure what's served](https://docs.platform.sh/create-apps/web.md).
####### Web commands
| Name | Type | Required | Description |
|--------------|----------|-------------------------------|-----------------------------------------------------------------------------------------------------|
| `pre_start` | `string` | | Command run just prior to `start`, which can be useful when you need to run _per-instance_ actions. |
| `start` | `string` | See [note](#required-command) | The command to launch your app. If it terminates, it's restarted immediately. |
| `post_start` | `string` | | Command runs **before** adding the container to the router and **after** the `start` command. |
**Note**:
The ``post_start`` feature is experimental and may change. Please share your feedback in the
[Platform.sh discord](https://discord.gg/platformsh).
Example:
```yaml {location=".platform.app.yaml"}
web:
commands:
start: 'uwsgi --ini conf/server.ini'
```
This command runs every time your app is restarted, regardless of whether or not new code is deployed.
**Note**:
Never “background” a start process using ``&``.
That’s interpreted as the command terminating and the supervisor process starts a second copy,
creating an infinite loop until the container crashes.
Just run it as normal and allow the Platform.sh supervisor to manage it.
######## Required command
On all containers other than PHP, the value for `start` should be treated as required.
On PHP containers, it's optional and defaults to starting PHP-FPM (`/usr/bin/start-php-app`).
It can also be set explicitly on a PHP container to run a dedicated process,
such as [React PHP](https://github.com/platformsh-examples/platformsh-example-reactphp)
or [Amp](https://github.com/platformsh-examples/platformsh-example-amphp).
See how to set up [alternate start commands on PHP](https://docs.platform.sh/languages/php.md#alternate-start-commands).
####### Upstream
| Name | Type | Required | Description | Default |
| --------------- |---------------------| -------- |-------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
| `socket_family` | `tcp` or `unix` | | Whether your app listens on a Unix or TCP socket. | Defaults to `tcp` for all [image types](#types) except PHP; for PHP image types the default is `unix`. |
| `protocol` | `http` or `fastcgi` | | Whether your app receives incoming requests over HTTP or FastCGI. | Default varies based on [image `type`](#types). |
For PHP, the defaults are configured for PHP-FPM and shouldn't need adjustment.
For all other containers, the default for `protocol` is `http`.
The following example is the default on non-PHP containers:
```yaml {location=".platform.app.yaml"}
web:
upstream:
socket_family: tcp
protocol: http
```
######## Where to listen
Where to listen depends on your setting for `web.upstream.socket_family` (defaults to `tcp`).
| `socket_family` | Where to listen |
|------------------|---------------------------------------------------------------------------------------------------------------------------------------|
| `tcp` | The port specified by the [`PORT` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) |
| `unix` | The Unix socket file specified by the [`SOCKET` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) |
If your application isn't listening at the same place that the runtime is sending requests,
you see `502 Bad Gateway` errors when you try to connect to your website.
####### Locations
Each key in the `locations` dictionary is a path on your site with a leading `/`.
For `example.com`, a `/` matches `example.com/` and `/admin` matches `example.com/admin`.
When multiple keys match an incoming request, the most-specific applies.
The following table presents possible properties for each location:
| Name | Type | Default | Description |
| ------------------- | ---------------------------------------------------- |------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `root` | `string` | | The directory to serve static assets for this location relative to the [app's root directory](#root-directory). Must be an actual directory inside the root directory. |
| `passthru` | `boolean` or `string` | `false` | Whether to forward disallowed and missing resources from this location to the app. A string is a path with a leading `/` to the controller, such as `/index.php`.
If your app is in PHP, when setting `passthru` to `true`, you might want to set `scripts` to `false` for enhanced security. This prevents PHP scripts from being executed from the specified location. You might also want to set `allow` to `false` so that not only PHP scripts can't be executed, but their source code also can't be delivered. |
| `index` | Array of `string`s or `null` | | Files to consider when serving a request for a directory. When set, requires access to the files through the `allow` or `rules` keys. |
| `expires` | `string` | `-1` | How long static assets are cached. The default means no caching. Setting it to a value enables the `Cache-Control` and `Expires` headers. Times can be suffixed with `ms` = milliseconds, `s` = seconds, `m` = minutes, `h` = hours, `d` = days, `w` = weeks, `M` = months/30d, or `y` = years/365d. If a `Cache-Control` appears on the `headers` configuration, `expires`, if set, will be ignored. Thus, make sure to set the `Cache-Control`'s `max-age` value when specifying a the header. |
| `allow` | `boolean` | `true` | Whether to allow serving files which don't match a rule. |
| `scripts` | `boolean` | | Whether to allow scripts to run. Doesn't apply to paths specified in `passthru`. Meaningful only on PHP containers. |
| `headers` | A headers dictionary | | Any additional headers to apply to static assets, mapping header names to values (see [Set custom headers on static content](https://docs.platform.sh/create-apps/web/custom-headers.md)). Responses from the app aren't affected. |
| `request_buffering` | A [request buffering dictionary](#request-buffering) | See below | Handling for chunked requests. |
| `rules` | A [rules dictionary](#rules) | | Specific overrides for specific locations. |
######## Rules
The rules dictionary can override most other keys according to a regular expression.
The key of each item is a regular expression to match paths exactly.
If an incoming request matches the rule, it's handled by the properties under the rule,
overriding any conflicting rules from the rest of the `locations` dictionary.
Under `rules`, you can set all the other possible [`locations` properties](#locations)
except `root`, `index`, `rules` and `request_buffering`.
In the following example, the `allow` key disallows requests for static files anywhere in the site.
This is overridden by a rule that explicitly allows common image file formats.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
# Handle dynamic requests
root: 'public'
passthru: '/index.php'
# Disallow static files
allow: false
rules:
# Allow common image files only.
'\.(jpe?g|png|gif|svgz?|css|js|map|ico|bmp|eot|woff2?|otf|ttf)$':
allow: true
```
######## Request buffering
Request buffering is enabled by default to handle chunked requests as most app servers don't support them.
The following table shows the keys in the `request_buffering` dictionary:
| Name | Type | Required | Default | Description |
| ------------------ | --------- |----------| ------- |-------------------------------------------|
| `enabled` | `boolean` | Yes | `true` | Whether request buffering is enabled. |
| `max_request_size` | `string` | | `250m` | The maximum size to allow in one request. |
The default configuration would look like this:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
passthru: true
request_buffering:
enabled: true
max_request_size: 250m
```
###### Workers
Workers are exact copies of the code and compilation output as a `web` instance after a [`build` hook](#hooks).
They use the same container image.
Workers can't accept public requests and so are suitable only for background tasks.
If they exit, they're automatically restarted.
The keys of the `workers` definition are the names of the workers.
You can then define how each worker differs from the `web` instance using
the [top-level properties](#top-level-properties).
Each worker can differ from the `web` instance in all properties _except_ for:
- `build` and `dependencies` properties, which must be the same
- `crons` as cron jobs don't run on workers
- `hooks` as the `build` hook must be the same
and the `deploy` and `post_deploy` hooks don't run on workers.
A worker named `queue` that was small and had a different start command could look like this:
```yaml {location=".platform.app.yaml"}
workers:
queue:
size: S
commands:
start: |
./worker.sh
```
For resource allocation, using workers in your project requires a [Medium
plan or larger](https://platform.sh/pricing/).
###### Access
The `access` dictionary has one allowed key:
| Name | Allowed values | Default | Description |
| ----- | ----------------------------------- | ------------- | ----------- |
| `ssh` | `admin`, `contributor`, or `viewer` | `contributor` | Defines the minimum role required to access app environments via SSH. |
In the following example, only users with `admin` permissions for the given [environment type](https://docs.platform.sh/administration/users.md#environment-type-roles)
can access the deployed environment via SSH:
```yaml {location=".platform.app.yaml"}
access:
ssh: admin
```
###### Variables
Platform.sh provides a number of ways to set [variables](https://docs.platform.sh/development/variables.md).
Variables set in your app configuration have the lowest precedence,
meaning they're overridden by any conflicting values provided elsewhere.
All variables set in your app configuration must have a prefix.
Some [prefixes have specific meanings](https://docs.platform.sh/development/variables.md#variable-prefixes).
Variables with the prefix `env` are available as a separate environment variable.
All other variables are available in the [`PLATFORM_VARIABLES` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
The following example sets two variables:
- A variable named `env:AUTHOR` with the value `Juan` that's available in the environment as `AUTHOR`
- A variable named `d8config:system.site:name` with the value `My site rocks`
that's available in the `PLATFORM_VARIABLES` environment variable
```yaml {location=".platform.app.yaml"}
variables:
env:
AUTHOR: 'Juan'
d8config:
"system.site:name": 'My site rocks'
```
You can also define and access more [complex values](https://docs.platform.sh/development/variables/use-variables.md#access-complex-values).
###### Firewall
**Tier availability**
This feature is available for
**Elite and Enterprise** customers. [Compare the tiers](https://platform.sh/pricing/) on our pricing page, or [contact our sales team](https://platform.sh/contact/) for more information.
Set limits in outbound traffic from your app with no impact on inbound requests.
The `outbound` key is required and contains one or more rules.
The rules define what traffic is allowed; anything unspecified is blocked.
Each rule has the following properties where at least one is required and `ips` and `domains` can't be specified together:
| Name | Type | Default | Description |
| --------- |---------------------|-----------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `ips` | Array of `string`s | `["0.0.0.0/0"]` | IP addresses in [CIDR notation](https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing). See a [CIDR format converter](https://www.ipaddressguide.com/cidr). |
| `domains` | Array of `string`s | | [Fully qualified domain names](https://en.wikipedia.org/wiki/Fully_qualified_domain_name) to specify specific destinations by hostname. |
| `ports` | Array of `integer`s | | Ports from 1 to 65535 that are allowed. If any ports are specified, all unspecified ports are blocked. If no ports are specified, all ports are allowed. Port `25`, the SMTP port for sending email, is always blocked. |
The default settings would look like this:
```yaml {location=".platform.app.yaml"}
firewall:
outbound:
- ips: ["0.0.0.0/0"]
```
####### Support for rules
Where outbound rules for firewalls are supported in all environments.
For Dedicated Gen 2 projects, contact support for configuration.
####### Multiple rules
Multiple firewall rules can be specified.
In such cases, a given outbound request is allowed if it matches _any_ of the defined rules.
So in the following example requests to any IP on port 80 are allowed
and requests to 1.2.3.4 on either port 80 or 443 are allowed:
```yaml {location=".platform.app.yaml"}
firewall:
outbound:
- ips: ["1.2.3.4/32"]
ports: [443]
- ports: [80]
```
####### Outbound traffic to CDNs
Be aware that many services are behind a content delivery network (CDN).
For most CDNs, routing is done via domain name, not IP address,
so thousands of domain names may share the same public IP addresses at the CDN.
If you allow the IP address of a CDN, you are usually allowing many or all of the other customers hosted behind that
CDN.
####### Outbound traffic by domain
You can filter outbound traffic by domain.
Using domains in your rules rather than IP addresses is generally more specific and secure.
For example, if you use an IP address for a service with a CDN,
you have to allow the IP address for the CDN.
This means that you allow potentially hundreds or thousands of other servers also using the CDN.
An example rule filtering by domain:
```yaml {location=".platform.app.yaml"}
firewall:
outbound:
- protocol: tcp
domains: ["api.stripe.com", "api.twilio.com"]
ports: [80, 443]
- protocol: tcp
ips: ["1.2.3.4/29","2.3.4.5"]
ports: [22]
```
######## Determine which domains to allow
To determine which domains to include in your filtering rules,
find the domains your site has requested the DNS to resolve.
Run the following command to parse your server’s `dns.log` file
and display all Fully Qualified Domain Names that have been requested:
```bash
awk '/query\[[^P]\]/ { print $6 | "sort -u" }' /var/log/dns.log
```
The output includes all DNS requests that were made, including those blocked by your filtering rules.
It doesn't include any requests made using an IP address.
Example output:
```bash
facebook.com
fastly.com
platform.sh
www.google.com
www.platform.sh
```
###### Build
The only property of the `build` dictionary is `flavor`, which specifies a default set of build tasks to run.
Flavors are language-specific.
See what the build flavor is for your language:
- [Node.js](https://docs.platform.sh/languages/nodejs.md#dependencies)
- [PHP](https://docs.platform.sh/languages/php.md#dependencies)
In all languages, you can also specify a flavor of `none` to take no action at all
(which is the default for any language other than PHP and Node.js).
```yaml {location=".platform.app.yaml"}
build:
flavor: none
```
###### Dependencies
Installs global dependencies as part of the build process.
They're independent of your app's dependencies
and are available in the `PATH` during the build process and in the runtime environment.
They're installed before the `build` hook runs using a package manager for the language.
| Language | Key name | Package manager |
|----------|-----------------------|--------------------------------------------------------------------------------------------------------------------|
| PHP | `php` | [Composer](https://getcomposer.org/) |
| Python 2 | `python` or `python2` | [Pip 2](https://packaging.python.org/tutorials/installing-packages/) |
| Python 3 | `python3` | [Pip 3](https://packaging.python.org/tutorials/installing-packages/) |
| Ruby | `ruby` | [Bundler](https://bundler.io/) |
| Node.js | `nodejs` | [npm](https://www.npmjs.com/) (see [how to use yarn](https://docs.platform.sh/languages/nodejs.md#use-yarn-as-a-package-manager)) |
The format for package names and version constraints are defined by the specific package manager.
An example of dependencies in multiple languages:
```yaml {location=".platform.app.yaml"}
dependencies:
php: # Specify one Composer package per line.
drush/drush: '8.0.0'
composer/composer: '^2'
python2: # Specify one Python 2 package per line.
behave: '*'
requests: '*'
python3: # Specify one Python 3 package per line.
numpy: '*'
ruby: # Specify one Bundler package per line.
sass: '3.4.7'
nodejs: # Specify one NPM package per line.
pm2: '^4.5.0'
```
###### Hooks
There are three different hooks that run as part of the process of building and deploying your app.
These are places where you can run custom scripts.
They are: the `build` hook, the `deploy` hook, and the `post_deploy` hook.
Only the `build` hook is run for [worker instances](#workers), while [web instances](#web) run all three.
The process is ordered as:
1. Variables accessible at build time become available.
1. [Build flavor](#build) runs if applicable.
1. Any [dependencies](#dependencies) are installed.
1. The `build` hook is run.
1. The file system is changed to read only (except for any [mounts](#mounts)).
1. The app container starts. Variables accessible at runtime and services become available.
1. The `deploy` hook is run.
1. The app container begins accepting requests.
1. The `post_deploy` hook is run.
Note that if an environment changes by no code changes, only the last step is run.
If you want the entire process to run, see how
to [manually trigger builds](https://docs.platform.sh/development/troubleshoot.md#manually-trigger-builds).
####### Writable directories during build
During the `build` hook, there are three writeable directories:
- `PLATFORM_APP_DIR`:
Where your code is checked out and the working directory when the `build` hook starts.
Becomes the app that gets deployed.
- `PLATFORM_CACHE_DIR`:
Persists between builds, but isn't deployed.
Shared by all builds on all branches.
- `/tmp`:
Isn't deployed and is wiped between each build.
Note that `PLATFORM_CACHE_DIR` is mapped to `/tmp`
and together they offer about 8GB of free space.
####### Hook failure
Each hook is executed as a single script, so they're considered to have failed only if the final command in them fails.
To cause them to fail on the first failed command, add `set -e` to the beginning of the hook.
If a `build` hook fails for any reason, the build is aborted and the deploy doesn't happen.
Note that this only works for `build` hooks --
if other hooks fail, the app is still deployed.
######## Automated testing
It’s preferable that you set up and run automated tests in a dedicated CI/CD tool.
Relying on Platform.sh hooks for such tasks can prove difficult.
During the `build` hook, you can halt the deployment on a test failure but the following limitations apply:
- Access to services such as databases, Redis, Vault KMS, and even writable mounts is disabled.
So any testing that relies on it is sure to fail.
- If you haven’t made changes to your app, an existing build image is reused and the build hook isn’t run.
- Test results are written into your app container, so they might get exposed to a third party.
During the `deploy` hook, you can access services but **you can’t halt the deployment based on a test failure**.
Note that there are other downsides:
- Your app container is read-only during the deploy hook,
so if your tests need to write reports and other information, you need to create a file mount for them.
- Your app can only be deployed once the deploy hook has been completed.
Therefore, running automated testing via the deploy hook generates slower deployments.
- Your environment isn’t available externally during the deploy hook.
Unit and integration testing might work without the environment being available,
but you can’t typically perform end-to-end testing until after the environment is up and available.
###### Crons
The keys of the `crons` definition are the names of the cron jobs.
The names must be unique.
If an application defines both a `web` instance and `worker` instances, cron jobs run only on the `web` instance.
See how to [get cron logs](https://docs.platform.sh/increase-observability/logs/access-logs.md#container-logs).
The following table shows the properties for each job:
| Name | Type | Required | Description |
| ------------------ | -------------------------------------------- | -------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `spec` | `string` | Yes | The [cron specification](https://en.wikipedia.org/wiki/Cron#Cron_expression). To prevent competition for resources that might hurt performance, on **Grid or Dedicated Gen 3** projects use `H` in definitions to indicate an unspecified but invariant time. For example, instead of using `0 * * * *` to indicate the cron job runs at the start of every hour, you can use `H * * * *` to indicate it runs every hour, but not necessarily at the start. This prevents multiple cron jobs from trying to start at the same time. **The `H` syntax isn't available on Dedicated Gen 2 projects.** |
| `commands` | A [cron commands dictionary](#cron-commands) | Yes | A definition of what commands to run when starting and stopping the cron job. |
| `shutdown_timeout` | `integer` | No | When a cron is canceled, this represents the number of seconds after which a `SIGKILL` signal is sent to the process to force terminate it. The default is `10` seconds. |
| `timeout` | `integer` | No | The maximum amount of time a cron can run before it's terminated. Defaults to the maximum allowed value of `86400` seconds (24 hours).
Note that you can [cancel pending or running crons](https://docs.platform.sh/environments/cancel-activity.md).
**Note**:
The use of the ``cmd`` key is now deprecated in favor of the ``commands``key.
Make sure you set your new cron jobs using the ``commands`` key,
and update your existing cron jobs to ensure continuity.
####### Cron commands
| Name | Type | Required | Description |
| ------------------ | --------- | -------- | ----------- |
| `start` | `string` | Yes | The command that's run. It's run in [Dash](https://en.wikipedia.org/wiki/Almquist_shell). |
| `stop` | `string` | No | The command that's issued to give the cron command a chance to shutdown gracefully, such as to finish an active item in a list of tasks. Issued when a cron task is interrupted by a user through the CLI or Console. If not specified, a `SIGTERM` signal is sent to the process. |
```yaml {location=".platform.app.yaml"}
crons:
mycommand:
spec: 'H * * * *'
commands:
start: sleep 60 && echo sleep-60-finished && date
stop: killall sleep
shutdown_timeout: 18
```
In this example configuration, the [cron specification](#crons) uses the `H` syntax.
Note that this syntax is only supported on Grid and Dedicated Gen 3 projects.
On Dedicated Gen 2 projects, use the [standard cron syntax](https://en.wikipedia.org/wiki/Cron#Cron_expression).
####### Example cron jobs
```yaml {}
type: 'php:8.4'
crons:
# Run Drupal's cron tasks every 19 minutes.
drupal:
spec: '*/19 * * * *'
commands:
start: 'cd web ; drush core-cron'
# But also run pending queue tasks every 7 minutes.
# Use an odd number to avoid running at the same time as the `drupal` cron.
drush-queue:
spec: '*/7 * * * *'
commands:
start: 'cd web ; drush queue-run aggregator_feeds'
```
.platform.app.yaml
```yaml {}
type: 'ruby:3.4'
crons:
# Execute a rake script every 19 minutes.
ruby:
spec: '*/19 * * * *'
commands:
start: 'bundle exec rake some:task'
```
.platform.app.yaml
```yaml {}
type: 'php:8.4'
crons:
# Run Laravel's scheduler every 5 minutes.
scheduler:
spec: '*/5 * * * *'
commands:
start: 'php artisan schedule:run'
```
.platform.app.yaml
```yaml {}
type: 'php:8.4'
crons:
# Take a backup of the environment every day at 5:00 AM.
snapshot:
spec: 0 5 * * *
commands:
start: |
# Only run for the production environment, aka main branch
if [ "$PLATFORM_ENVIRONMENT_TYPE" = "production" ]; then
croncape symfony ...
fi
```
####### Conditional crons
If you want to set up customized cron schedules depending on the environment type,
define conditional crons.
To do so, use a configuration similar to the following:
```yaml {location=".platform.app.yaml"}
crons:
update:
spec: '0 0 * * *'
commands:
start: |
if [ "$PLATFORM_ENVIRONMENT_TYPE" = production ]; then
platform backup:create --yes --no-wait
platform source-operation:run update --no-wait --yes
fi
```
####### Cron job timing
Minimum time between cron jobs being triggered:
| Plan | Time |
|-------------------- | --------- |
| Professional | 5 minutes |
| Elite or Enterprise | 1 minute |
For each app container, only one cron job can run at a time.
If a new job is triggered while another is running, the new job is paused until the other completes.
To minimize conflicts, a random offset is applied to all triggers.
The offset is a random number of seconds up to 20 minutes or the cron frequency, whichever is smaller.
Crons are also paused while activities such as [backups](https://docs.platform.sh/environments/backup.md) are running.
The crons are queued to run after the other activity finishes.
To run cron jobs in a timezone other than UTC, set the [timezone property](#top-level-properties).
####### Paused crons
[Preview environments](https://docs.platform.sh/glossary.md#preview-environment) are often used for a limited time and then abandoned.
While it's useful for environments under active development to have scheduled tasks,
unused environments don't need to run cron jobs.
To minimize unnecessary resource use,
crons on environments with no deployments are paused.
This affects all environments that aren't live environments.
This means all environments on Development plans
and all preview environments on higher plans.
Such environments with deployments within 14 days have crons with the status `running`.
If there haven't been any deployments within 14 days, the status is `paused`.
You can see the status in the Console
or using the CLI by running `platform environment:info` and looking under `deployment_state`.
######## Restarting paused crons
If the crons on your preview environment are paused but you're still using them,
you can push changes to the environment or redeploy it.
To restart crons without changing anything:
Run the following command:
```bash {}
platform redeploy
```
###### Runtime
The following table presents the various possible modifications to your PHP runtime:
| Name | Type | Language | Description |
|-----------------------------|------------------------------------------------------------|----------|---------------------------------------------------------------------------------------------------------|
| `extensions` | List of `string`s OR [extensions definitions](#extensions) | PHP | [PHP extensions](https://docs.platform.sh/languages/php/extensions.md) to enable. |
| `disabled_extensions` | List of `string`s | PHP | [PHP extensions](https://docs.platform.sh/languages/php/extensions.md) to disable. |
| `request_terminate_timeout` | `integer` | PHP | The timeout (in seconds) for serving a single request after which the PHP-FPM worker process is killed. |
| `sizing_hints` | A [sizing hints definition](#sizing-hints) | PHP | The assumptions for setting the number of workers in your PHP-FPM runtime. |
| `xdebug` | An Xdebug definition | PHP | The setting to turn on [Xdebug](https://docs.platform.sh/languages/php/xdebug.md). |
You can also set your [app's runtime timezone](https://docs.platform.sh/create-apps/timezone.md).
####### Extensions
**Note**:
You can now use the Platform.sh composable image (BETA) to install runtimes and tools in your application container.
If you’ve reached this section from another page and are using the composable image, enabling/disabling extensions should be placed under the ``stack`` key instead of what is listed below.
See [how to configure extensions with the composable image](https://docs.platform.sh/create-apps/app-reference/composable-image.md#top-level-properties).
You can enable [PHP extensions](https://docs.platform.sh/languages/php/extensions.md) just with a list of extensions:
```yaml {location=".platform.app.yaml"}
runtime:
extensions:
- geoip
- tidy
```
Alternatively, if you need to include configuration options, use a dictionary for that extension:
```yaml {location=".platform.app.yaml"}
runtime:
extensions:
- geoip
- name: blackfire
configuration:
server_id: foo
server_token: bar
```
In this case, the `name` property is required.
####### Sizing hints
The following table shows the properties that can be set in `sizing_hints`:
| Name | Type | Default | Minimum | Description |
|-------------------|-----------|---------|---------|------------------------------------------------|
| `request_memory` | `integer` | 45 | 10 | The average memory consumed per request in MB. |
| `reserved_memory` | `integer` | 70 | 70 | The amount of memory reserved in MB. |
See more about [PHP-FPM workers and sizing](https://docs.platform.sh/languages/php/fpm.md).
###### Source
The following table shows the properties that can be set in `source`:
| Name | Type | Required | Description |
| ------------ | ------------------------ | -------- |------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `operations` | An operations dictionary | | Operations that can be applied to the source code. See [source operations](https://docs.platform.sh/create-apps/source-operations.md) |
| `root` | `string` | | The path where the app code lives. Defaults to the directory of the `.platform.app.yaml` file. Useful for [multi-app setups](https://docs.platform.sh/create-apps/multi-app.md). |
###### Additional hosts
If you're using a private network with specific IP addresses you need to connect to,
you might want to map those addresses to hostnames to better remember and organize them.
In such cases, you can add a map of those IP addresses to whatever hostnames you like.
Then when your app tries to access the hostname, it's sent to the proper IP address.
So in the following example, if your app tries to access `api.example.com`, it's sent to `192.0.2.23`.
```yaml {location=".platform.app.yaml"}
additional_hosts:
api.example.com: "192.0.2.23"
web.example.com: "203.0.113.42"
```
This is equivalent to adding the mapping to the `/etc/hosts` file for the container.
#### Composable image
The Platform.sh composable image provides enhanced flexibility when defining your app.
It allows you to install several runtimes and tools in your application container,
in a **"one image to rule them all"** approach.
The composable image is built on [Nix](https://nix.dev), which offers the following benefits:
- You can add as many packages to your application container as you need,
choosing from over 120,000 packages from [the Nixpkgs collection](https://search.nixos.org/packages).
- The packages you add are built in total isolation, so you can install different versions of the same package.
- With [Nix](https://nix.dev/reference/glossary#term-Nix), there are no undeclared dependencies in your source code.
What works on your local machine is guaranteed to work on any other machine.
This page introduces all the settings available to configure your composable image from your `.platform.app.yaml` file
(usually located at the root of your Git repository).
Note that multi-app projects can be [set in various ways](https://docs.platform.sh/create-apps/multi-app.md).
If you're pressed for time, jump to this comprehensive [configuration example](https://docs.platform.sh/create-apps.md#comprehensive-example).
###### Top-level properties
The following table presents all the properties you can use at the top level of your app's YAML configuration file.
The column _Set in instance?_ defines whether the given property can be overridden within a `web` or `workers` instance.
To override any part of a property, you have to provide the entire property.
| Name | Type | Required | Set in instance? | Description |
|--------------------|--------------------------------------------------------------------------|----------|------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `name` | `string` | Yes | No | A unique name for the app. Must be lowercase alphanumeric characters. Changing the name destroys data associated with the app. |
| `type` | A type | Yes | No | [Defines the version of the Nix channel](#supported-nix-channels). Example: `type: "composable:25.05"` |
| `stack` | An array of [Nix packages](#stack) | Yes | No | A list of packages from the Platform.sh collection of [supported runtimes](#supported-nix-packages) and/or from [Nixpkgs](https://search.nixos.org/packages). |
| `size` | A [size](#sizes) | | Yes | How much resources to devote to the app. Defaults to `AUTO` in production environments. |
| `relationships` | A dictionary of [relationships](#relationships) | | Yes | Connections to other services and apps. |
| `disk` | `integer` or `null` | | Yes | The size of the disk space for the app in [MB](https://docs.platform.sh/glossary.md#mb). Minimum value is `128`. Defaults to `null`, meaning no disk is available. See [note on available space](#available-disk-space). |
| `mounts` | A dictionary of [mounts](#mounts) | | Yes | Directories that are writable even after the app is built. If set as a local source, `disk` is required. |
| `web` | A [web instance](#web) | | N/A | How the web application is served. |
| `workers` | A [worker instance](#workers) | | N/A | Alternate copies of the application to run as background processes. |
| `timezone` | `string` | | No | The timezone for crons to run. Format: a [TZ database name](https://en.wikipedia.org/wiki/List_of_tz_database_time_zones). Defaults to `UTC`, which is the timezone used for all logs no matter the value here. See also [app runtime timezones](https://docs.platform.sh/create-apps/timezone.md). |
| `access` | An [access dictionary](#access) | | Yes | Access control for roles accessing app environments. |
| `variables` | A [variables dictionary](#variables) | | Yes | Variables to control the environment. |
| `firewall` | A [firewall dictionary](#firewall) | | Yes | Outbound firewall rules for the application. |
| `hooks` | A [hooks dictionary](#hooks) | | No | What commands run at different stages in the build and deploy process. |
| `crons` | A [cron dictionary](#crons) | | No | Scheduled tasks for the app. |
| `source` | A [source dictionary](#source) | | No | Information on the app's source code and operations that can be run on it. |
| `additional_hosts` | An [additional hosts dictionary](#additional-hosts) | | Yes | Maps of hostnames to IP addresses. |
| `operations` | A [dictionary of Runtime operations](https://docs.platform.sh/create-apps/runtime-operations.md) | | No | Runtime operations for the application. |
**Note**:
The ``build``, ``dependencies``, and ``runtime`` keys are only supported when using a [single-runtime image](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md).
They are **not** supported when using the composable image.
They are replaced by the ``stack`` key.
###### Stack
Use the ``stack`` key to define which runtimes and binaries you want to install in your application container.
Define them as a YAML array as follows:
```yaml {location=".platform/applications.yaml"}
myapp:
stack: [ "@" ]
# OR
stack:
- "@"
```
To add a language to your stack, use the `@` format.
To add a tool to your stack, use the `` format, as no version is needed.
**Warning**:
While technically available during the build phase, ``nix`` commands aren’t supported at runtime as the image becomes read-only.
When using the Platform.sh composable image, you don’t need ``nix`` commands.
Everything you install using the ``stack`` key is readily available to you as the binaries are linked and included in ``$PATH``.
For instance, to [start a secondary runtime](#primary-runtime),
just issue the command (e.g. in the [start](https://docs.platform.sh/create-apps/app-reference/composable-image.md#web-commands)) instead of the ``nix run`` command.
######## Primary runtime
If you add multiple runtimes to your application container,
the first declared runtime becomes the primary runtime.
The primary runtime is the one that is automatically started.
To start other declared runtimes, you need to start them manually, using [web commands](#web-commands).
To find out which start command to use, go to the [Languages](https://docs.platform.sh/languages.md) section,
and visit the documentation page dedicated to your runtime.
**Note**:
If you use PHP, note that PHP-FPM is only started automatically if PHP is defined as the primary runtime.
####### Supported Nix channels
A Nix channel represents a curated, tested snapshot of the Nixpkgs repository, which contains a collection of Nix expressions (code for building packages and configuring systems).
Using the latest stable Nix channel ensures that you get stable, verified packages (not all `git` commits are heavily tested before being merged into the `master` branch).
Upsun typically supports only the most recent channel, but sometimes support for a previous channel is extended.
The following channels are supported:
- `25.05`
- `24.05`
####### Configure Nix channels
The Nix channel can be configured with the [top-level property `type`](#top-level-properties).
For example, to use the Nix channel `25.05`, you would use the following syntax:
```yaml {location=".platform/applications.yaml"}
type: "composable:25.05"
```
####### Supported Nix packages
**Note**:
The Nix packages listed in the following table are officially supported by Platform.sh to provide optimal user experience.
However, you can add any other packages from [the Nixpkgs collection](https://search.nixos.org/) to your ``stack``.
This includes packages from the ``unstable`` channel,
like [FrankenPHP](https://search.nixos.org/packages?channel=unstable&show=frankenphp&from=0&size=50&sort=relevance&type=packages&query=frankenphp).
While available for you to install, packages that aren’t listed in the following table are supported by Nix itself, not Platform.sh.
Depending on the Nix package, you can select only the major runtime version,
or the major and minor runtime versions as shown in the table.
Security and other patches are applied automatically.
| **Language** | **Nix package** | **Supported version(s)** |
|----------------------------------------------|---------------|----------------------------------------|
| [Clojure](https://clojure.org/) | `clojure` | 1 |
| [Elixir](https://docs.platform.sh/languages/elixir.md) | `elixir` | 1.151.14 |
| [Go](https://docs.platform.sh/languages/go.md) | `golang` | 1.221.21 |
| [Java](https://docs.platform.sh/languages/java.md) | `java` | 2221 |
| [Javascript/Bun](https://bun.sh/) | `bun` | 1 |
| [JavaScript/Node.js](https://docs.platform.sh/languages/nodejs.md) | `nodejs` | 24222018 |
| [Perl](https://www.perl.org/) | `perl` | 5 |
| [PHP](https://docs.platform.sh/languages/php.md) | `php` | 8.48.38.28.1 |
| [Python](https://docs.platform.sh/languages/python.md) | `python` | 3.123.113.103.92.7 |
| [Ruby](https://docs.platform.sh/languages/ruby.md) | `ruby` | 3.43.33.23.1 |
**Example:**
You want to add PHP version 8.4 and ``facedetect`` to your application container.
To do so, use the following configuration:
```yaml {location=".platform/applications.yaml"}
myapp:
stack: [ "php@8.4", "facedetect" ]
# OR
stack:
- "php@8.4"
- "facedetect"
```
####### PHP extensions and Python packages
When you add PHP or Python to your application container,
you can define which extensions (for PHP) or packages (for Python) you also want to add to your stack.
To find out which extensions you can install with your runtime,
follow these steps:
1. Go to the [NixOS search](https://search.nixos.org/).
2. Enter a runtime and click **Search**.
3. In the **Package sets** side bar, select the right set of extensions/packages for your runtime version.
You can choose the desired extensions/packages from the filtered results.

######## Install PHP extensions
To enable [PHP extensions](https://docs.platform.sh/languages/php/extensions.md),
specify a list of `extensions` below the language definition.
To disable [PHP extensions](https://docs.platform.sh/languages/php/extensions.md),
specify a list of `disabled_extensions` below the language definition.
For instance:
```yaml {location=".platform/applications.yaml"}
myapp:
source:
root: "/"
stack:
- "php@8.4":
extensions:
- apcu
- sodium
- xsl
- pdo_sqlite
disabled_extensions:
- gd
```
**Note**:
To help you find out the name of the PHP package you want to use,
some maintainers provide a ``PHP upstream extension`` value in the [NixOS search engine](https://search.nixos.org/packages?channel=unstable&show=php82Extensions.gd).
If this information is not provided, note that PHP package names on NixOS always respect the ``Extensions.`` format.
Therefore, you can copy the ```` as shown in the NixOS search results, and use it in your configuration.
Note that you can use environment variables or your `php.ini` file to [include further configuration options](https://docs.platform.sh/languages/php.md#customize-php-settings) for your PHP extensions.
######## Install Python packages
To install Python packages, add them to your stack as new packages.
To do so, use the full name of the package.
For instance, to install [``python312Packages.yq``](https://search.nixos.org/packages?channel=unstable&show=python312Packages.yq),
use the following configuration:
```yaml {location=".platform/applications.yaml"}
myapp:
stack:
- "python@3.12"
- "python312Packages.yq" # python package specific
```
Alternatively, if you need to include configuration options for your extensions, use either your ``php.ini`` file or [environment variables](https://docs.platform.sh/development/variables/set-variables.md).
####### Example configuration
Here is a full composable image configuration example. Note the use of the `@` format.
```yaml {location=".platform/applications.yaml"}
myapp:
stack:
- "php@8.4":
extensions:
- apcu
- sodium
- xsl
- pdo_sqlite
- "python@3.12"
- "python312Packages.yq" # python package specific
- "yq" # tool
```
####### Combine single-runtime and composable images
In a [multiple application context](https://docs.platform.sh/create-apps/multi-app.md),
you can use a mix of [single-runtime images](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md)
and [composable images](https://docs.platform.sh/create-apps/app-reference/composable-image.md).
Here is an example configuration including a ``frontend`` app and a ``backend`` app:
```yaml {location=".platform/applications.yaml"}
backend:
stack:
- "php@8.4":
extensions:
- apcu
- sodium
- xsl
- pdo_sqlite
- "python@3.12"
- "python312Packages.yq" # python package specific
frontend:
type: 'nodejs:22
```
**Note**:
If you add multiple runtimes to your application container,
the first declared runtime becomes the primary runtime.
The primary runtime is the one that is automatically started.
To start other declared runtimes, you need to start them manually, using [web commands](#web-commands).
To find out which start command to use, go to the [Languages](https://docs.platform.sh/languages.md) section,
and visit the documentation page dedicated to your language.
If you use PHP, note that PHP-FPM is only started automatically if PHP is defined as the primary runtime.
###### Sizes
Resources are distributed across all containers in an environment from the total available from your [plan size](https://docs.platform.sh/administration/pricing.md).
So if you have more than just a single app, it doesn't get all of the resources available.
Each environment has its own resources and there are different [sizing rules for preview environments](#sizes-in-preview-environments).
By default, resource sizes (CPU and memory) are chosen automatically for an app
based on the plan size and the number of other containers in the cluster.
Most of the time, this automatic sizing is enough.
You can set sizing suggestions for production environments when you know a given container has specific needs.
Such as a worker that doesn't need much and can free up resources for other apps.
To do so, set `size` to one of the following values:
- `S`
- `M`
- `L`
- `XL`
- `2XL`
- `4XL`
The total resources allocated across all apps and services can't exceed what's in your plan.
####### Container profiles: CPU and memory
By default, Platform.sh allocates a container profile to each app and service depending on:
- The range of resources it’s expected to need
- Your [plan size](https://docs.platform.sh/administration/pricing.md), as resources are distributed across containers.
Ideally you want to give databases the biggest part of your memory, and apps the biggest part of your CPU.
The container profile and the [size of the container](#sizes) determine
how much CPU and memory (in [MB](https://docs.platform.sh/glossary.md#mb)) the container gets.
There are three container profiles available: ``HIGH_CPU``, ``BALANCED``, and ``HIGH_MEMORY``.
######## ``HIGH_CPU`` container profile
| Size | CPU | MEMORY |
| ---- | ----- | -------- |
| S | 0.40 | 128 MB |
| M | 0.40 | 128 MB |
| L | 1.20 | 256 MB |
| XL | 2.50 | 384 MB |
| 2XL | 5.00 | 768 MB |
| 4XL | 10.00 | 1536 MB |
######## `BALANCED` container profile
| Size | CPU | MEMORY |
| ---- | ---- | -------- |
| S | 0.05 | 32 MB |
| M | 0.05 | 64 MB |
| L | 0.08 | 256 MB |
| XL | 0.10 | 512 MB |
| 2XL | 0.20 | 1024 MB |
| 4XL | 0.40 | 2048 MB |
######## `HIGH_MEMORY` container profile
| Size | CPU | MEMORY |
| ---- | ---- | --------- |
| S | 0.25 | 128 MB |
| M | 0.25 | 288 MB |
| L | 0.40 | 1280 MB |
| XL | 0.75 | 2624 MB |
| 2XL | 1.50 | 5248 MB |
| 4XL | 3.00 | 10496 MB |
######## Container profile reference
The following table shows which container profiles Platform.sh applies when deploying your project.
| Container | Profile |
|-------------------------|---------------|
| Chrome Headless | HIGH_CPU |
| .NET | HIGH_CPU |
| Elasticsearch | HIGH_MEMORY |
| Elasticsearch Premium | HIGH_MEMORY |
| Elixir | HIGH_CPU |
| Go | HIGH_CPU |
| Gotenberg | HIGH_MEMORY |
| InfluxDB | HIGH_MEMORY |
| Java | HIGH_MEMORY |
| Kafka | HIGH_MEMORY |
| Lisp | HIGH_CPU |
| MariaDB | HIGH_MEMORY |
| Memcached | BALANCED |
| MongoDB | HIGH_MEMORY |
| MongoDB Premium | HIGH_MEMORY |
| Network Storage | HIGH_MEMORY |
| Node.js | HIGH_CPU |
| OpenSearch | HIGH_MEMORY |
| Oracle MySQL | HIGH_MEMORY |
| PHP | HIGH_CPU |
| PostgreSQL | HIGH_MEMORY |
| Python | HIGH_CPU |
| RabbitMQ | HIGH_MEMORY |
| Redis ephemeral | BALANCED |
| Redis persistent | BALANCED |
| Ruby | HIGH_CPU |
| Rust | HIGH_CPU |
| Solr | HIGH_MEMORY |
| Varnish | HIGH_MEMORY |
| Vault KMS | HIGH_MEMORY |
####### Sizes in preview environments
Containers in preview environments don't follow the `size` specification.
Application containers are set based on the plan's setting for **Environments application size**.
The default is size **S**, but you can increase it by editing your plan.
(Service containers in preview environments are always set to size **S**.)
###### Relationships
To allow containers in your project to communicate with one another,
you need to define relationships between them.
You can define a relationship between an app and a service, or [between two apps](https://docs.platform.sh/create-apps/multi-app/relationships.md).
The quickest way to define a relationship between your app and a service
is to use the service's default endpoint.
However, some services allow you to define multiple databases, cores, and/or permissions.
In these cases, you can't rely on default endpoints.
Instead, you can explicitly define multiple endpoints when setting up your relationships.
**Note**:
App containers don’t have a default endpoint like services.
To connect your app to another app in your project,
you need to explicitly define the ``http`` endpoint as the endpoint to connect both apps.
For more information, see how to [define relationships between your apps](https://docs.platform.sh/create-apps/multi-app/relationships.md).
**Availability**:
New syntax (default and explicit endpoints) described below is supported by most, but not all, image types
(``Relationship 'SERVICE_NAME' of application 'myapp' ... targets a service without a valid default endpoint configuration.``).
This syntax is currently being rolled out for all images.
If you encounter this error, use the “legacy” Platform.sh configuration noted at the bottom of this section.
To define a relationship between your app and a service:
```yaml {}
relationships:
:
```
The ``SERVICE_NAME`` is the name of the service as defined in its [configuration](https://docs.platform.sh/add-services.md).
It is used as the relationship name, and associated with a ``null`` value.
This instructs Platform.sh to use the service’s default endpoint to connect your app to the service.
For example, if you define the following configuration:
.platform.app.yaml
```yaml {}
relationships:
mariadb:
```
Platform.sh looks for a service named ``mariadb`` in your ``.platform/services.yaml`` file,
and connects your app to it through the service’s default endpoint.
For reference, the equivalent configuration using explicit endpoints would be the following:
.platform.app.yaml
```yaml {}
relationships:
mariadb:
service: mariadb
endpoint: mysql
```
You can define any number of relationships in this way:
.platform.app.yaml
```yaml {}
relationships:
mariadb:
redis:
elasticsearch:
```
**Tip**:
An even quicker way to define many relationships is to use the following single-line configuration:
.platform.app.yaml
```yaml {}
relationships: {, , }
```
where
.platform/services.yaml
```yaml {}
:
type: mariadb:11.8
disk: 256
:
type: redis:8.0
disk: 256
:
type: elasticsearch:8.5
disk: 256
```
Use the following configuration:
.platform.app.yaml
```yaml {}
relationships:
:
service:
endpoint:
```
- ``RELATIONSHIP_NAME`` is the name you want to give to the relationship.
- ``SERVICE_NAME`` is the name of the service as defined in its [configuration](https://docs.platform.sh/add-services.md).
- ``ENDPOINT_NAME`` is the endpoint your app will use to connect to the service (refer to the service reference to know which value to use).
For example, to define a relationship named ``database`` that connects your app to a service called ``mariadb`` through the ``db1`` endpoint,
use the following configuration:
.platform.app.yaml
```yaml {}
relationships:
database: # The name of the relationship.
service: mariadb
endpoint: db1
```
For more information on how to handle multiple databases, multiple cores,
and/or different permissions with services that support such features,
see each service’s dedicated page:
- [MariaDB/MySQL](https://docs.platform.sh/add-services/mysql.md#multiple-databases) (multiple databases and permissions)
- [PostgreSQL](https://docs.platform.sh/add-services/postgresql.md#multiple-databases) (multiple databases and permissions)
- [Redis](https://docs.platform.sh/add-services/redis.md#multiple-databases) (multiple databases)
- [Solr](https://docs.platform.sh/add-services/solr.md#solr-6-and-later) (multiple cores)
- [Vault KMS](https://docs.platform.sh/add-services/vault.md#multiple-endpoints-configuration) (multiple permissions)
You can add as many relationships as you want to your app configuration,
using both default and explicit endpoints according to your needs:
.platform.app.yaml
```yaml {}
relationships:
database1:
service: mariadb
endpoint: admin
database2:
service: mariadb
endpoint: legacy
cache:
service: redis
search:
service: elasticsearch
```
**Legacy**:
The following legacy syntax for specifying relationships is still supported by Platform.sh:
.platform.app.yaml
```yaml {}
relationships:
: ":"
```
For example:
.platform.app.yaml
```yaml {}
relationships:
database: "mariadb:mysql"
```
Feel free to use this until the default and explicit endpoint syntax is supported on all images.
###### Available disk space
The maximum total space available to all apps and services is set by the storage in your plan settings.
When deploying your project, the sum of all `disk` keys defined in app and service configurations
must be *equal or less* than the plan storage size.
So if your *plan storage size* is 5 GB, you can, for example, assign it in one of the following ways:
- 2 GB to your app, 3 GB to your database
- 1 GB to your app, 4 GB to your database
- 1 GB to your app, 1 GB to your database, 3 GB to your OpenSearch service
If you exceed the total space available, you receive an error on pushing your code.
You need to either increase your plan's storage or decrease the `disk` values you've assigned.
You configure the disk size in [MB](https://docs.platform.sh/glossary.md#mb). Your actual available disk space is slightly smaller with some space used for formatting and the filesystem journal. When checking available space, note whether it’s reported in MB or MiB.
####### Downsize a disk
You can decrease the size of an existing disk for an app. If you do so, be aware that:
- The downsize fails if there's more data on the disk than the desired size.
- Backups from before the downsize can still be restored.
###### Mounts
After your app is built, its file system is read-only.
To make changes to your app's code, you need to use Git.
For enhanced flexibility, Platform.sh allows you to define and use writable directories called "mounts".
Mounts give you write access to files generated by your app (such as cache and log files)
and uploaded files without going through Git.
When you define a mount, you are mounting an external directory to your app container,
much like you would plug a hard drive into your computer to transfer data.
**Note**:
- Mounts aren’t available during the build
- When you [back up an environment](https://docs.platform.sh/environments/backup.md), the mounts on that environment are backed up too
####### Define a mount
To define a mount, use the following configuration:
```yaml {location=".platform.app.yaml"}
mounts:
'':
source:
source_path:
```
is the path to your mount **within the app container** (relative to the app's root).
If you already have a directory with that name, you get a warning that it isn't accessible after the build.
See how to [troubleshoot the warning](https://docs.platform.sh/create-apps/troubleshoot-mounts.md#overlapping-folders).
| Name | Type | Required | Description |
| ------------- |-------------------------------|----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `source` | `local`, `service`, or `tmp` | Yes | Specifies the type of the mount: - `local` mounts are unique to your app. They can be useful to store files that remain local to the app instance, such as application logs. `local` mounts require disk space. To successfully set up a local mount, set the `disk` key in your app configuration. - `service` mounts point to [Network Storage](https://docs.platform.sh/add-services/network-storage.md) services that can be shared between several apps. - `tmp` mounts are local ephemeral mounts, where an external directory is mounted to the `/tmp` directory of your app. The content of a `tmp` mount **may be removed during infrastructure maintenance operations**. Therefore, `tmp` mounts allow you to **store files that you’re not afraid to lose**, such as your application cache that can be seamlessly rebuilt. Note that the `/tmp` directory has **a maximum allocation of 8 GB**. |
| `source_path` | `string` | No | Specifies where the mount points **inside the [external directory](#mounts)**. - If you explicitly set a `source_path`, your mount points to a specific subdirectory in the external directory. - If the `source_path` is an empty string (`""`), your mount points to the entire external directory. - If you don't define a `source_path`, Platform.sh uses the as default value, without leading or trailing slashes. For example, if your mount lives in the `/web/uploads/` directory in your app container, it will point to a directory named `web/uploads` in the external directory. **WARNING:** Changing the name of your mount affects the `source_path` when it's undefined. See [how to ensure continuity](#ensure-continuity-when-changing-the-name-of-your-mount) and maintain access to your files. |
| `service` | `string` | | Only for `service` mounts: the name of the [Network Storage service](https://docs.platform.sh/add-services/network-storage.md). |
The accessibility to the web of a mounted directory depends on the [`web.locations` configuration](#web).
Files can be all public, all private, or with different rules for different paths and file types.
Note that when you remove a `local` mount from your `.platform.app.yaml` file,
the mounted directory isn't deleted.
The files still exist on disk until manually removed
(or until the app container is moved to another host during a maintenance operation in the case of a `tmp` mount).
####### Example configuration
```yaml {location=".platform.app.yaml"}
mounts:
'web/uploads':
source: local
source_path: uploads
'/.tmp_platformsh':
source: tmp
source_path: files/.tmp_platformsh
'/build':
source: local
source_path: files/build
'/.cache':
source: tmp
source_path: files/.cache
'/node_modules/.cache':
source: tmp
source_path: files/node_modules/.cache
```
For examples of how to set up a `service` mount, see the dedicated [Network Storage page](https://docs.platform.sh/add-services/network-storage.md).
####### Ensure continuity when changing the name of your mount
Changing the name of your mount affects the default `source_path`.
Say you have a `/my/cache/` mount with an undefined `source_path`:
```yaml {location=".platform.app.yaml"}
mounts:
'/my/cache/':
source: tmp
```
If you rename the mount to `/cache/files/`, it will point to a new, empty `/cache/files/` directory.
To ensure continuity, you need to explicitly define the `source_path` as the previous name of the mount, without leading or trailing slashes:
```yaml {location=".platform.app.yaml"}
mounts:
'/cache/files/':
source: tmp
source_path: my/cache
```
The `/cache/files/` mount will point to the original `/my/cache/` directory, maintaining access to all your existing files in that directory.
####### Overlapping mounts
The locations of mounts as they are visible to application containers can overlap somewhat.
For example:
```yaml {location=".platform/applications.yaml"}
applications:
myapp:
# ...
mounts:
'var/cache_a':
source: service
service: ns_service
source_path: cacheA
'var/cache_b':
source: tmp
source_path: cacheB
'var/cache_c':
source: local
source_path: cacheC
```
In this case, it does not matter that each mount is of a different `source` type.
Each mount is restricted to a subfolder within `var`, and all is well.
The following, however, is not allowed and will result in a failure:
```yaml {location=".platform/applications.yaml"}
applications:
myapp:
# ...
mounts:
'var/':
source: service
service: ns_service
source_path: cacheA
'var/cache_b':
source: tmp
source_path: cacheB
'var/cache_c':
source: local
source_path: cacheC
```
The `service` mount type specifically exists to share data between instances of the same application, whereas `tmp` and `instance` are meant to restrict data to build time and runtime of a single application instance, respectively.
These allowances are not compatible, and will result in an error if pushed.
###### Web
Use the `web` key to configure the web server running in front of your app.
| Name | Type | Required | Description |
|-------------|--------------------------------------------|-------------------------------|------------------------------------------------------|
| `commands` | A [web commands dictionary](#web-commands) | See [note](#required-command) | The command to launch your app. |
| `upstream` | An [upstream dictionary](#upstream) | | How the front server connects to your app. |
| `locations` | A [locations dictionary](#locations) | | How the app container responds to incoming requests. |
See some [examples of how to configure what's served](https://docs.platform.sh/create-apps/web.md).
####### Web commands
| Name | Type | Required | Description |
|--------------|----------|-------------------------------|------------------------------------------------------------------------------------------------------|
| `pre_start` | `string` | | Command runs just prior to `start`, which can be useful when you need to run _per-instance_ actions. |
| `start` | `string` | See [note](#required-command) | The command to launch your app. If it terminates, it's restarted immediately. |
| `post_start` | `string` | | Command runs **before** adding the container to the router and **after** the `start` command. |
**Note**:
The ``post_start`` feature is experimental and may change. Please share your feedback in the
[Platform.sh discord](https://discord.gg/platformsh).
Example:
```yaml {location=".platform.app.yaml"}
web:
commands:
start: 'uwsgi --ini conf/server.ini'
```
This command runs every time your app is restarted, regardless of whether or not new code is deployed.
**Note**:
Never “background” a start process using ``&``.
That’s interpreted as the command terminating and the supervisor process starts a second copy,
creating an infinite loop until the container crashes.
Just run it as normal and allow the Platform.sh supervisor to manage it.
######## Required command
On all containers other than PHP, the value for `start` should be treated as required.
On PHP containers, it's optional and defaults to starting PHP-FPM (`/usr/bin/start-php-app`).
It can also be set explicitly on a PHP container to run a dedicated process,
such as [React PHP](https://github.com/platformsh-examples/platformsh-example-reactphp)
or [Amp](https://github.com/platformsh-examples/platformsh-example-amphp).
See how to set up [alternate start commands on PHP](https://docs.platform.sh/languages/php.md#alternate-start-commands).
####### Upstream
| Name | Type | Required | Description | Default |
|-----------------|---------------------|----------|-------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
| `socket_family` | `tcp` or `unix` | | Whether your app listens on a Unix or TCP socket. | Defaults to `tcp` for all [primary runtimes](#primary-runtime) except PHP; for PHP the default is `unix`. |
| `protocol` | `http` or `fastcgi` | | Whether your app receives incoming requests over HTTP or FastCGI. | Default varies based on the [primary runtimes](#primary-runtime). |
For PHP, the defaults are configured for PHP-FPM and shouldn't need adjustment.
For all other containers, the default for `protocol` is `http`.
The following example is the default on non-PHP containers:
```yaml {location=".platform.app.yaml"}
web:
upstream:
socket_family: tcp
protocol: http
```
######## Where to listen
Where to listen depends on your setting for `web.upstream.socket_family` (defaults to `tcp`).
| `socket_family` | Where to listen |
|-----------------|---------------------------------------------------------------------------------------------------------------------------------------|
| `tcp` | The port specified by the [`PORT` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) |
| `unix` | The Unix socket file specified by the [`SOCKET` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) |
If your application isn't listening at the same place that the runtime is sending requests,
you see `502 Bad Gateway` errors when you try to connect to your website.
####### Locations
Each key in the `locations` dictionary is a path on your site with a leading `/`.
For `example.com`, a `/` matches `example.com/` and `/admin` matches `example.com/admin`.
When multiple keys match an incoming request, the most-specific applies.
The following table presents possible properties for each location:
| Name | Type | Default | Description |
|---------------------|------------------------------------------------------|-----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `root` | `string` | | The directory to serve static assets for this location relative to the app's root directory ([see `source.root`](#source)). Must be an actual directory inside the root directory. |
| `passthru` | `boolean` or `string` | `false` | Whether to forward disallowed and missing resources from this location to the app. A string is a path with a leading `/` to the controller, such as `/index.php`.
If your app is in PHP, when setting `passthru` to `true`, you might want to set `scripts` to `false` for enhanced security. This prevents PHP scripts from being executed from the specified location. You might also want to set `allow` to `false` so that not only PHP scripts can't be executed, but their source code also can't be delivered. |
| `index` | Array of `string`s or `null` | | Files to consider when serving a request for a directory. When set, requires access to the files through the `allow` or `rules` keys. |
| `expires` | `string` | `-1` | How long static assets are cached. The default means no caching. Setting it to a value enables the `Cache-Control` and `Expires` headers. Times can be suffixed with `ms` = milliseconds, `s` = seconds, `m` = minutes, `h` = hours, `d` = days, `w` = weeks, `M` = months/30d, or `y` = years/365d. |
| `allow` | `boolean` | `true` | Whether to allow serving files which don't match a rule. |
| `scripts` | `boolean` | | Whether to allow scripts to run. Doesn't apply to paths specified in `passthru`. Meaningful only on PHP containers. |
| `headers` | A headers dictionary | | Any additional headers to apply to static assets, mapping header names to values (see [Set custom headers on static content](https://docs.platform.sh/create-apps/web/custom-headers.md)). Responses from the app aren't affected. |
| `request_buffering` | A [request buffering dictionary](#request-buffering) | See below | Handling for chunked requests. |
| `rules` | A [rules dictionary](#rules) | | Specific overrides for specific locations. |
######## Rules
The rules dictionary can override most other keys according to a regular expression.
The key of each item is a regular expression to match paths exactly.
If an incoming request matches the rule, it's handled by the properties under the rule,
overriding any conflicting rules from the rest of the `locations` dictionary.
Under `rules`, you can set all the other possible [`locations` properties](#locations)
except `root`, `index`, `rules` and `request_buffering`.
In the following example, the `allow` key disallows requests for static files anywhere in the site.
This is overridden by a rule that explicitly allows common image file formats.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
# Handle dynamic requests
root: 'public'
passthru: '/index.php'
# Disallow static files
allow: false
rules:
# Allow common image files only.
'\.(jpe?g|png|gif|svgz?|css|js|map|ico|bmp|eot|woff2?|otf|ttf)$':
allow: true
```
######## Request buffering
Request buffering is enabled by default to handle chunked requests as most app servers don't support them.
The following table shows the keys in the `request_buffering` dictionary:
| Name | Type | Required | Default | Description |
|--------------------|-----------|----------|---------|-------------------------------------------|
| `enabled` | `boolean` | Yes | `true` | Whether request buffering is enabled. |
| `max_request_size` | `string` | | `250m` | The maximum size to allow in one request. |
The default configuration would look like this:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
passthru: true
request_buffering:
enabled: true
max_request_size: 250m
```
###### Workers
Workers are exact copies of the code and compilation output as a `web` instance after a [`build` hook](#hooks).
They use the same container image.
Workers can't accept public requests and so are suitable only for background tasks.
If they exit, they're automatically restarted.
The keys of the `workers` definition are the names of the workers.
You can then define how each worker differs from the `web` instance using
the [top-level properties](#top-level-properties).
Each worker can differ from the `web` instance in all properties _except_ for:
- `crons` as cron jobs don't run on workers
- `hooks` as the `build` hook must be the same
and the `deploy` and `post_deploy` hooks don't run on workers.
A worker named `queue` that was small and had a different start command could look like this:
```yaml {location=".platform.app.yaml"}
workers:
queue:
size: S
commands:
start: |
./worker.sh
```
For resource allocation, using workers in your project requires a [Medium
plan or larger](https://platform.sh/pricing/).
###### Access
The `access` dictionary has one allowed key:
| Name | Allowed values | Default | Description |
|-------|-------------------------------------|---------------|-----------------------------------------------------------------------|
| `ssh` | `admin`, `contributor`, or `viewer` | `contributor` | Defines the minimum role required to access app environments via SSH. |
In the following example, only users with `admin` permissions for the
given [environment type](https://docs.platform.sh/administration/users.md#environment-type-roles)
can access the deployed environment via SSH:
```yaml {location=".platform.app.yaml"}
access:
ssh: admin
```
###### Variables
Platform.sh provides a number of ways to set [variables](https://docs.platform.sh/development/variables.md).
Variables set in your app configuration have the lowest precedence,
meaning they're overridden by any conflicting values provided elsewhere.
All variables set in your app configuration must have a prefix.
Some [prefixes have specific meanings](https://docs.platform.sh/development/variables.md#variable-prefixes).
Variables with the prefix `env` are available as a separate environment variable.
All other variables are available in
the [`PLATFORM_VARIABLES` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
The following example sets two variables:
- A variable named `env:AUTHOR` with the value `Juan` that's available in the environment as `AUTHOR`
- A variable named `d8config:system.site:name` with the value `My site rocks`
that's available in the `PLATFORM_VARIABLES` environment variable
```yaml {location=".platform.app.yaml"}
variables:
env:
AUTHOR: 'Juan'
d8config:
"system.site:name": 'My site rocks'
```
You can also define and access more [complex values](https://docs.platform.sh/development/variables/use-variables.md#access-complex-values).
###### Firewall
**Tier availability**
This feature is available for
**Elite and Enterprise** customers. [Compare the tiers](https://platform.sh/pricing/) on our pricing page, or [contact our sales team](https://platform.sh/contact/) for more information.
Set limits in outbound traffic from your app with no impact on inbound requests.
The `outbound` key is required and contains one or more rules.
The rules define what traffic is allowed; anything unspecified is blocked.
Each rule has the following properties where at least one is required and `ips` and `domains` can't be specified
together:
| Name | Type | Default | Description |
|-----------|---------------------|-----------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `ips` | Array of `string`s | `["0.0.0.0/0"]` | IP addresses in [CIDR notation](https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing). See a [CIDR format converter](https://www.ipaddressguide.com/cidr). |
| `domains` | Array of `string`s | | [Fully qualified domain names](https://en.wikipedia.org/wiki/Fully_qualified_domain_name) to specify specific destinations by hostname. |
| `ports` | Array of `integer`s | | Ports from 1 to 65535 that are allowed. If any ports are specified, all unspecified ports are blocked. If no ports are specified, all ports are allowed. Port `25`, the SMTP port for sending email, is always blocked. |
The default settings would look like this:
```yaml {location=".platform.app.yaml"}
firewall:
outbound:
- ips: [ "0.0.0.0/0" ]
```
####### Support for rules
Where outbound rules for firewalls are supported in all environments.
For Dedicated Gen 2 projects, contact support for configuration.
####### Multiple rules
Multiple firewall rules can be specified.
In such cases, a given outbound request is allowed if it matches _any_ of the defined rules.
So in the following example requests to any IP on port 80 are allowed
and requests to 1.2.3.4 on either port 80 or 443 are allowed:
```yaml {location=".platform.app.yaml"}
firewall:
outbound:
- ips: [ "1.2.3.4/32" ]
ports: [ 443 ]
- ports: [ 80 ]
```
####### Outbound traffic to CDNs
Be aware that many services are behind a content delivery network (CDN).
For most CDNs, routing is done via domain name, not IP address,
so thousands of domain names may share the same public IP addresses at the CDN.
If you allow the IP address of a CDN, you are usually allowing many or all of the other customers hosted behind that
CDN.
####### Outbound traffic by domain
You can filter outbound traffic by domain.
Using domains in your rules rather than IP addresses is generally more specific and secure.
For example, if you use an IP address for a service with a CDN,
you have to allow the IP address for the CDN.
This means that you allow potentially hundreds or thousands of other servers also using the CDN.
An example rule filtering by domain:
```yaml {location=".platform.app.yaml"}
firewall:
outbound:
- protocol: tcp
domains: ["api.stripe.com", "api.twilio.com"]
ports: [80, 443]
- protocol: tcp
ips: ["1.2.3.4/29","2.3.4.5"]
ports: [22]
```
######## Determine which domains to allow
To determine which domains to include in your filtering rules,
find the domains your site has requested the DNS to resolve.
Run the following command to parse your server’s `dns.log` file
and display all Fully Qualified Domain Names that have been requested:
```bash
awk '/query\[[^P]\]/ { print $6 | "sort -u" }' /var/log/dns.log
```
The output includes all DNS requests that were made, including those blocked by your filtering rules.
It doesn't include any requests made using an IP address.
Example output:
```bash
facebook.com
fastly.com
platform.sh
www.google.com
www.platform.sh
```
###### Hooks
There are three different hooks that run as part of the process of building and deploying your app.
These are places where you can run custom scripts.
They are: the `build` hook, the `deploy` hook, and the `post_deploy` hook.
Only the `build` hook is run for [worker instances](#workers), while [web instances](#web) run all three.
The process is ordered as:
1. Variables accessible at build time become available.
1. The `build` hook is run.
1. The file system is changed to read only (except for any [mounts](#mounts)).
1. The app container starts. Variables accessible at runtime and services become available.
1. The `deploy` hook is run.
1. The app container begins accepting requests.
1. The `post_deploy` hook is run.
Note that if an environment changes by no code changes, only the last step is run.
If you want the entire process to run, see how to [manually trigger builds](https://docs.platform.sh/development/troubleshoot.md#manually-trigger-builds).
####### Writable directories during build
During the `build` hook, there are three writeable directories:
- `PLATFORM_APP_DIR`:
Where your code is checked out and the working directory when the `build` hook starts.
Becomes the app that gets deployed.
- `PLATFORM_CACHE_DIR`:
Persists between builds, but isn't deployed.
Shared by all builds on all branches.
- `/tmp`:
Isn't deployed and is wiped between each build.
Note that `PLATFORM_CACHE_DIR` is mapped to `/tmp`
and together they offer about 8GB of free space.
####### Hook failure
Each hook is executed as a single script, so they're considered to have failed only if the final command in them fails.
To cause them to fail on the first failed command, add `set -e` to the beginning of the hook.
If a `build` hook fails for any reason, the build is aborted and the deploy doesn't happen.
Note that this only works for `build` hooks --
if other hooks fail, the app is still deployed.
######## Automated testing
It’s preferable that you set up and run automated tests in a dedicated CI/CD tool.
Relying on Platform.sh hooks for such tasks can prove difficult.
During the `build` hook, you can halt the deployment on a test failure but the following limitations apply:
- Access to services such as databases, Redis, Vault KMS, and even writable mounts is disabled.
So any testing that relies on it is sure to fail.
- If you haven’t made changes to your app, an existing build image is reused and the build hook isn’t run.
- Test results are written into your app container, so they might get exposed to a third party.
During the `deploy` hook, you can access services but **you can’t halt the deployment based on a test failure**.
Note that there are other downsides:
- Your app container is read-only during the deploy hook,
so if your tests need to write reports and other information, you need to create a file mount for them.
- Your app can only be deployed once the deploy hook has been completed.
Therefore, running automated testing via the deploy hook generates slower deployments.
- Your environment isn’t available externally during the deploy hook.
Unit and integration testing might work without the environment being available,
but you can’t typically perform end-to-end testing until after the environment is up and available.
###### Crons
The keys of the `crons` definition are the names of the cron jobs.
The names must be unique.
If an application defines both a `web` instance and `worker` instances, cron jobs run only on the `web` instance.
See how to [get cron logs](https://docs.platform.sh/increase-observability/logs/access-logs.md#container-logs).
The following table shows the properties for each job:
| Name | Type | Required | Description |
|--------------------|----------------------------------------------|----------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `spec` | `string` | Yes | The [cron specification](https://en.wikipedia.org/wiki/Cron#Cron_expression). To prevent competition for resources that might hurt performance, use `H` in definitions to indicate an unspecified but invariant time. For example, instead of using `0 * * * *` to indicate the cron job runs at the start of every hour, you can use `H * * * *` to indicate it runs every hour, but not necessarily at the start. This prevents multiple cron jobs from trying to start at the same time. |
| `commands` | A [cron commands dictionary](#cron-commands) | Yes | A definition of what commands to run when starting and stopping the cron job. |
| `shutdown_timeout` | `integer` | No | When a cron is canceled, this represents the number of seconds after which a `SIGKILL` signal is sent to the process to force terminate it. The default is `10` seconds. |
| `timeout` | `integer` | No | The maximum amount of time a cron can run before it's terminated. Defaults to the maximum allowed value of `86400` seconds (24 hours). |
Note that you can [cancel pending or running crons](https://docs.platform.sh/environments/cancel-activity.md).
**Note**:
The use of the ``cmd`` key is now deprecated in favor of the ``commands``key.
Make sure you set your new cron jobs using the ``commands`` key,
and update your existing cron jobs to ensure continuity.
####### Cron commands
| Name | Type | Required | Description |
|---------|----------|----------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `start` | `string` | Yes | The command that's run. It's run in [Dash](https://en.wikipedia.org/wiki/Almquist_shell). |
| `stop` | `string` | No | The command that's issued to give the cron command a chance to shutdown gracefully, such as to finish an active item in a list of tasks. Issued when a cron task is interrupted by a user through the CLI or Console. If not specified, a `SIGTERM` signal is sent to the process. |
```yaml {location=".platform.app.yaml"}
crons:
mycommand:
spec: 'H * * * *'
commands:
start: sleep 60 && echo sleep-60-finished && date
stop: killall sleep
shutdown_timeout: 18
```
In this example configuration, the [cron specification](#crons) uses the `H` syntax.
Note that this syntax is only supported on Grid and Dedicated Gen 3 projects.
On Dedicated Gen 2 projects, use the [standard cron syntax](https://en.wikipedia.org/wiki/Cron#Cron_expression).
####### Example cron jobs
```yaml {}
stack: [ "php@8.4" ]
crons:
# Run Drupal's cron tasks every 19 minutes.
drupal:
spec: '*/19 * * * *'
commands:
start: 'cd web ; drush core-cron'
# But also run pending queue tasks every 7 minutes.
# Use an odd number to avoid running at the same time as the `drupal` cron.
drush-queue:
spec: '*/7 * * * *'
commands:
start: 'cd web ; drush queue-run aggregator_feeds'
```
.platform.app.yaml
```yaml {}
stack: [ "ruby@3.4" ]
crons:
# Execute a rake script every 19 minutes.
ruby:
spec: '*/19 * * * *'
commands:
start: 'bundle exec rake some:task'
```
.platform.app.yaml
```yaml {}
stack: [ "php@8.4" ]
crons:
# Run Laravel's scheduler every 5 minutes.
scheduler:
spec: '*/5 * * * *'
commands:
start: 'php artisan schedule:run'
```
.platform.app.yaml
```yaml {}
stack: [ "php@8.4" ]
crons:
# Take a backup of the environment every day at 5:00 AM.
snapshot:
spec: 0 5 * * *
commands:
start: |
# Only run for the production environment, aka main branch
if [ "$PLATFORM_ENVIRONMENT_TYPE" = "production" ]; then
croncape symfony ...
fi
```
####### Conditional crons
If you want to set up customized cron schedules depending on the environment type,
define conditional crons.
To do so, use a configuration similar to the following:
```yaml {location=".platform.app.yaml"}
crons:
update:
spec: '0 0 * * *'
commands:
start: |
if [ "$PLATFORM_ENVIRONMENT_TYPE" = production ]; then
platform backup:create --yes --no-wait
platform source-operation:run update --no-wait --yes
fi
```
####### Cron job timing
Minimum time between cron jobs being triggered:
| Plan | Time |
|-------------------- | --------- |
| Professional | 5 minutes |
| Elite or Enterprise | 1 minute |
For each app container, only one cron job can run at a time.
If a new job is triggered while another is running, the new job is paused until the other completes.
To minimize conflicts, a random offset is applied to all triggers.
The offset is a random number of seconds up to 20 minutes or the cron frequency, whichever is smaller.
Crons are also paused while activities such as [backups](https://docs.platform.sh/environments/backup.md) are running.
The crons are queued to run after the other activity finishes.
To run cron jobs in a timezone other than UTC, set the [timezone property](#top-level-properties).
####### Paused crons
[Preview environments](https://docs.platform.sh/glossary.md#preview-environment) are often used for a limited time and then abandoned.
While it's useful for environments under active development to have scheduled tasks,
unused environments don't need to run cron jobs.
To minimize unnecessary resource use,
crons on environments with no deployments are paused.
This affects all environments that aren't live environments.
This means all environments on Development plans
and all preview environments on higher plans.
Such environments with deployments within 14 days have crons with the status `running`.
If there haven't been any deployments within 14 days, the status is `paused`.
You can see the status in the Console
or using the CLI by running `platform environment:info` and looking under `deployment_state`.
######## Restarting paused crons
If the crons on your preview environment are paused but you're still using them,
you can push changes to the environment or redeploy it.
To restart crons without changing anything:
Run the following command:
```bash {}
platform redeploy
```
####### Sizing hints
The following table shows the properties that can be set in `sizing_hints`:
| Name | Type | Default | Minimum | Description |
|-------------------|-----------|---------|---------|------------------------------------------------|
| `request_memory` | `integer` | 45 | 10 | The average memory consumed per request in MB. |
| `reserved_memory` | `integer` | 70 | 70 | The amount of memory reserved in MB. |
See more about [PHP-FPM workers and sizing](https://docs.platform.sh/languages/php/fpm.md).
###### Source
The following table shows the properties that can be set in `source`:
| Name | Type | Required | Description |
|--------------|--------------------------|----------|---------------------------------------------------------------------------------------------------------------------------------|
| `operations` | An operations dictionary | | Operations that can be applied to the source code. See [source operations](https://docs.platform.sh/create-apps/source-operations.md) |
| `root` | `string` | | The path where the app code lives. Defaults to the root project directory. Useful for [multi-app setups](https://docs.platform.sh/create-apps/multi-app.md). |
###### Additional hosts
If you're using a private network with specific IP addresses you need to connect to,
you might want to map those addresses to hostnames to better remember and organize them.
In such cases, you can add a map of those IP addresses to whatever hostnames you like.
Then when your app tries to access the hostname, it's sent to the proper IP address.
So in the following example, if your app tries to access `api.example.com`, it's sent to `192.0.2.23`.
```yaml {location=".platform.app.yaml"}
additional_hosts:
api.example.com: "192.0.2.23"
web.example.com: "203.0.113.42"
```
This is equivalent to adding the mapping to the `/etc/hosts` file for the container.
### Source operations
On Platform.sh, you can run automated code updates through a feature called **source operations**.
Defined in your [app configuration](https://docs.platform.sh/create-apps.md), source operations let you specify commands
that can commit changes to your project's repository when called.
For example, you can set up a source operation to [automatically update your application dependencies](https://docs.platform.sh/learn/tutorials/dependency-updates.md),
[update a site from an upstream repository](#update-a-site-from-an-upstream-repository-or-template),
or [revert to the last commit](#revert-to-the-last-commit) pushed to your Git repository.
To run your source operations, you can use the [Platform.sh CLI](https://docs.platform.sh/administration/cli.md) or the [Console](https://console.platform.sh).
If you want to run your source operations and update your code automatically,
you can also define [cron jobs](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#crons).
##### How source operations work
When you trigger a source operation, the following happens in order:
1. The current environment HEAD commit is checked out in Git.
It doesn't have any remotes or tags defined in the project.
It only has the current environment branch.
2. Sequentially, for each app that has an operation bearing [the name](#define-a-source-operation)
of the triggered source operation in its configuration,
the operation command is run in the app container.
The container isn't part of the environment's runtime cluster
and doesn't require that the environment is running.
The environment has all of the variables normally available during the build phase.
These may be optionally overridden by the variables specified when the operation is run.
3. If any new commits were created, they're pushed to the repository and the normal build process is triggered.
If multiple apps in a single project both result in a new commit,
there are two distinct commits in the Git history but only a single new build process.
##### Define a source operation
A source operation requires two things:
- A name that must be unique within the application.
The name is the key of the block defined under `source.operations` in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#source).
- A `command` that defines what's run when the operation is triggered.
The syntax is similar to the following:
```yaml {location=".platform.app.yaml"}
source:
operations:
:
command:
```
For example, to update a file from a remote location, you could define an operation like this:
```yaml {location=".platform.app.yaml"}
source:
operations:
update-file:
command: |
set -e
curl -O https://example.com/myfile.txt
git add myfile.txt
git commit -m "Update remote file"
```
The name of the source operation in this case is `update-file`.
For more possibilities, see other [source operation examples](#source-operation-examples).
##### Run a source operation
Run the following command:
```bash {}
platform source-operation:run
```
Replace with the name of your operation, such as ``update-file`` in the [example above](#define-a-source-operation).
After running a source operation,
to apply the changes to your local development environment run the `git pull` command.
Note that you can [cancel pending or running source operations](https://docs.platform.sh/environments/cancel-activity.md).
##### Use variables in your source operations
You can add [variables](https://docs.platform.sh/development/variables.md) to the environment of the source operation.
Use the `env:` prefix to expose each of those variables as a Unix environment variable.
In this way, they're referenced by the source operation
and interpreted the same way as any other variable set in your project.
For example, you might want to have a `FILE` variable available with the value `example.txt`
to pass to a source operation similar to the following:
```yaml {location=".platform.app.yaml"}
source:
operations:
update-file:
command: |
set -e
curl -O https://example.com/$FILE
git add $FILE
git commit -m "Update remote file"
```
Follow these steps to run the source operation:
```bash {}
platform source-operation:run update-file --variable env:FILE="example.txt"
```
##### Source integrations
If your project is using a [source integration](https://docs.platform.sh/integrations/source.md),
any new commits resulting from a source operation are first pushed to your external Git repository.
Then the source integration pushes those commits to Platform.sh and redeploys the environment.
When using a source integration,
you can't run source operations on environments created from pull or merge requests created on the external repository.
If you try running a source operation on a non-supported environment, you see the following error:
```text
[ApiFeatureMissingException]
This project doesn't support source operations.
```
##### Automated source operations using a cron job
You can use a cron to automatically run your source operations.
Note that it’s best not to run source operations on your production environment,
but rather on a dedicated environment where you can test changes.
Make sure you have the [Platform.sh CLI](https://docs.platform.sh/administration/cli.md) installed
and [an API token](https://docs.platform.sh/administration/cli/api-tokens.md#2-create-an-api-token)
so you can run a cron job in your app container.
1. Set your API token as a top-level environment variable:
- Open the environment where you want to add the variable.
- Click Settings **Settings**.
- Click **Variables**.
- Click **+ Add variable**.
- In the **Variable name** field, enter ``env:PLATFORMSH_CLI_TOKEN``.
- In the **Value** field, enter your API token.
- Make sure the **Available at runtime** and **Sensitive variable** options are selected.
- Click **Add variable**.
**Note**:
Once you add the API token as an environment variable,
anyone with [SSH access](https://docs.platform.sh/development/ssh.md) can read its value.
Make sure you carefully check your [user access on this project](https://docs.platform.sh/administration/users.md#manage-project-users).
2. Add a build hook to your app configuration to install the CLI as part of the build process:
```yaml {location=".platform.app.yaml"}
hooks:
build: |
set -e
echo "Installing Platform.sh CLI"
curl -fsSL https://raw.githubusercontent.com/platformsh/cli/main/installer.sh | bash
echo "Testing Platform.sh CLI"
platform
```
3. Then, to configure a cron job to automatically run a source operation once a day,
use a configuration similar to the following:
```yaml {location=".platform.app.yaml"}
crons:
update:
# Run the code below every day at midnight.
spec: '0 0 * * *'
commands:
start: |
set -e
platform sync -e development code data --no-wait --yes
platform source-operation:run update-file --no-wait --yes
```
The example above synchronizes the `development` environment with its parent
and then runs the `update-file` source operation defined [previously](#define-a-source-operation).
##### Source operation examples
**Tier availability**
This feature is available for
**Enterprise and Elite** customers. [Compare the tiers](https://platform.sh/pricing/) on our pricing page, or [contact our sales team](https://platform.sh/contact/) for more information.
###### Update your application dependencies
You can set up a source operation and a cron job to [automate your dependency updates](https://docs.platform.sh/learn/tutorials/dependency-updates.md).
###### Update a site from an upstream repository or template
The following source operation syncronizes your branch with an upstream Git repository.
1. [Add a project-level variable](https://docs.platform.sh/development/variables/set-variables.md#create-project-variables)
named `env:UPSTREAM_REMOTE` with the Git URL of the upstream repository.
That makes that repository available as a Unix environment variable in all environments,
including in the source operation's environment.
- Variable name: `env:UPSTREAM_REMOTE`
- Variable example value: `https://github.com/platformsh/platformsh-docs`
2. In your app configuration, define a source operation to fetch from that upstream repository:
```yaml {location=".platform.app.yaml"}
source:
operations:
upstream-update:
command: |
set -e
git remote add upstream $UPSTREAM_REMOTE
git fetch --all
git merge upstream/main
```
3. Now every time you run the `upstream-update` operation on a given branch,
the branch fetches all changes from the upstream git repository
and then merges the latest changes from the default branch in the upstream repository.
If there’s a conflict merging from the upstream repository,
the source operation fails and doesn't update from the upstream repository.
Run the `upstream-update` operation on a preview environment rather than directly on Production.
###### Revert to the last commit
The following source operation reverts the last commit pushed to the Git repository.
This can be useful if you didn't properly test the changes of another operation
and you need to quickly revert to the previous state.
```yaml {location=".platform.app.yaml"}
source:
operations:
revert:
command: |
git reset --hard HEAD~
```
Now every time you run the `revert` operation on a given branch,
the operation reverts to the last commit pushed to that branch.
###### Update Drupal Core
The following source operation uses Composer to update Drupal Core:
```yaml {location=".platform.app.yaml"}
source:
operations:
update-drupal-core:
command: |
set -e
composer update drupal/core --with-dependencies
git add composer.lock
git commit -m "Automated Drupal Core update."
```
`--with-dependencies` is used to also update Drupal Core dependencies.
Read more on how to [update Drupal Core via Composer on Drupal.org](https://www.drupal.org/docs/updating-drupal/updating-drupal-core-via-composer).
Now every time you run the `update-drupal-core` operation, it updates Drupal Core.
###### Download a Drupal extension
The following source operation downloads a Drupal extension.
You can define the Drupal extension by setting an `EXTENSION` variable
or [overriding it](#use-variables-in-your-source-operations) when running the source operation.
```yaml {location=".platform.app.yaml"}
source:
operations:
download-drupal-extension:
command: |
set -e
composer require $EXTENSION
git add composer.json
git commit -am "Automated install of: $EXTENSION via Composer."
```
Now every time you run the `download-drupal-extension` operation, it downloads the defined extension.
If it's a new extension, after the source operation finishes,
you need to enable the new extension via the Drupal management interface or using Drush.
###### Update Git submodules
The following source operation updates all Git submodules recursively:
```yaml {location=".platform.app.yaml"}
source:
operations:
rebuild:
command: |
set -e
git submodule update --init --recursive
git submodule update --remote --checkout
SHA=$(git submodule | awk -F' ' '{print $1}' | sed -s 's/+//g')
echo -n "$SHA" > .sha
git add uppler .sha
git commit -m "Updating submodule to commit '$SHA'"
```
Now every time you run the `rebuild` operation, it updates the Git submodules.
### Runtime operations
Runtime operations allow you to trigger one-off commands or scripts on your project.
Similar to [crons](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#crons), they run in the app container but not on a specific schedule.
You can [define runtime operations](#define-a-runtime-operation) in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md)
and [trigger them](#run-a-runtime-operation) at any time through the Platform.sh CLI.
For example, if you have a static website,
you may want to set up a runtime operation to occasionally fetch content from a backend system
without having to rebuild your whole app.
You can use runtime operations if you have Grid or Dedicated Gen 3 environments.
##### Define a runtime operation
To define a runtime operation, add a configuration similar to the following:
```yaml {location=".platform.app.yaml"}
operations:
:
role:
commands:
start:
```
When you define a runtime operation,
you can specify which users can trigger it according to their user `role`:
- `viewer`
- `contributor`
- `admin`
If you don't set the `role` option when configuring your runtime operation,
by default all users with the `contributor` role can trigger it.
For example, to allow admin users to clear the cache of a Drupal site,
you could define an operation like the following:
```yaml {location=".platform.app.yaml"}
operations:
clear-rebuild:
role: admin
commands:
start: drush cache:rebuild
```
The name of the runtime operation in this case is `clear-rebuild`.
For more possibilities, see other [runtime operation examples](#runtime-operation-examples).
##### Run a runtime operation
A runtime operation can be triggered through the Platform.sh CLI once it has been [defined](#define-a-runtime-operation).
Run the following command:
```bash {}
platform operation:run --project --environment
```
You can only trigger a runtime operation if you have permission to do so.
Permissions are granted through the ``role`` option specified in the [runtime operation configuration](#define-a-runtime-operation). This can only be done if a [runtime operation has been defined](#define-a-runtime-operation).
For example, to trigger the runtime operation [defined previously](#define-a-runtime-operation),
you could run the following command:
```bash {}
platform operation:run clear-rebuild --project --environment
```
##### List your runtime operations
To list all the runtime operations available on an environment,
run the following command:
```bash
platform operation:list --project --environment
```
##### Runtime operation examples
###### Build your app when using a static site generator
During every Platform.sh deployment, a standard [build](https://docs.platform.sh/learn/overview/build-deploy.md#the-build) is run.
When you use a static site generator like [Gatsby](https://docs.platform.sh/guides/gatsby.md)
or [Next.js](https://docs.platform.sh/guides/nextjs.md) with [a headless backend](https://docs.platform.sh/guides/gatsby/headless.md),
you need to run a second ``build`` step to get your app ready for production.
This is because, as its framework is being built,
your frontend needs to pull content-related data from your backend’s API
(to generate all the static HTML pages your site is to serve).
To accomplish this on Platform.sh, where each app goes through a build-deploy pipeline in parallel,
your frontend’s build must be delayed _until after_ your backend has fully deployed.
It's often delayed up until the [`post_deploy` hook](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md#post-deploy-hook) stage,
when the filesystem is read-only.
You can use a runtime operation to trigger the second `build` step
after the initial deployment of your app or after a redeployment.
You can also trigger it when you need to fetch content from your backend
but want to avoid going through the whole Platform.sh [build and deploy processes](https://docs.platform.sh/learn/overview/build-deploy.md) again.
**Note**:
The following examples assume that the frontend and backend containers are included in the same environment.
This isn’t necessary for the commands to run successfully.
What is necessary is that the build destination for your frontend **is writable at runtime**
(meaning, you must [define a mount](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts) for it).
If you don’t want to include a build within a mount (especially if your data source **isn’t** on Platform.sh),
you can use [source operations](https://docs.platform.sh/create-apps/source-operations.md) to achieve a similar effect,
but through generating a new commit.
```yaml {}
operations:
gatsby-build:
role: viewer
commands:
start: gatsby build
```
To trigger your runtime operation, run a command similar to the following:
```bash {}
platform operation:run gatsby-build --project --environment
```
To run the [Next.js build](https://nextjs.org/docs/deployment#nextjs-build-api) step,
define a runtime operation similar to the following:
.platform.app.yaml
```yaml {}
operations:
next-build:
role: admin
commands:
# All below are valid, depending on your setup
start: next build
# start: npx next build
# start: npm run build
```
To trigger your runtime operation, run a command similar to the following:
```bash {}
platform operation:run next-build --project --environment
```
###### Execute actions on your Node.js app
You can define runtime operations for common [pm2](https://pm2.io/docs/runtime/overview/) process manager tasks.
```yaml {}
operations:
pm2-ping:
role: admin
commands:
start: |
# Assuming pm2 start npm --no-daemon --watch --name $APP -- start -- -p $PORT
APP=$(cat package.json | jq -r '.name')
pm2 ping $APP
```
To trigger your runtime operation, run a command similar to the following:
```bash {}
platform operation:run pm2-ping --project --environment
```
To reload your Node.js app, define a runtime operation similar to the following:
.platform.app.yaml
```yaml {}
operations:
pm2-reload:
role: admin
commands:
start: |
# Assuming pm2 start npm --no-daemon --watch --name $APP -- start -- -p $PORT
APP=$(cat package.json | jq -r '.name')
pm2 reload $APP
```
To trigger your runtime operation, run a command similar to the following:
```bash {}
platform operation:run pm2-reload --project --environment
```
To restart your Node.js app, define a runtime operation similar to the following:
.platform.app.yaml
```yaml {}
operations:
pm2-restart:
role: admin
commands:
start: |
# Assuming pm2 start npm --no-daemon --watch --name $APP -- start -- -p $PORT
APP=$(cat package.json | jq -r '.name')
pm2 restart $APP
```
To trigger your runtime operation, run a command similar to the following:
```bash {}
platform operation:run pm2-restart --project --environment
```
###### Define management commands on your Django project
On a Django project, you can [define custom `django-admin` commands](https://docs.djangoproject.com/en/4.2/howto/custom-management-commands/), for example to run a one-off management command (`manual migration` in the example above) outside of the Django ORM migration framework.
To do so, define a runtime operation similar to the following:
```yaml {location=".platform.app.yaml"}
name: myapp
type: python:3.13
operations:
manual-migration:
role: admin
commands:
start: python manage.py manual_migration
```
To trigger your runtime operation, run a command similar to the following:
```bash
platform operation:run manual-migration --project --environment
```
### Configure what's served
How you should configure your web server depends a lot on what you want to serve.
The following examples show how in specific scenarios you might define [your web server](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web).
#### Create a basic PHP app with a front controller
To handle dynamic requests to your PHP app, you might want to use a [front controller](https://en.wikipedia.org/wiki/Front_controller).
The following example shows how for such an app you might start defining [your web server](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web).
###### Define a document root
Start by defining your document root (where all your publicly visible pages are).
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
root: 'public'
```
###### Define a front controller
Define where all requests that don't match a file in the document root are sent.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
root: 'public'
passthru: '/index.php'
index:
- index.php
```
In this case, `/index.php` acts as a front controller and handles dynamic requests.
Because it handles dynamic requests, you want to ensure that scripts are enabled
and responses aren't cached.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
#...
scripts: true
# No caching for static files.
# (Dynamic pages use whatever cache headers are generated by the program.)
expires: -1
```
###### Define rules
You might want to define specific rules for the location.
For example, you might want to allow all kinds of files except mp4 files.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
...
# Allow all file types generally
allow: true
rules:
# Disallow .mp4 files specifically.
\.mp4$:
allow: false
```
###### Set different rules for specific locations
You might want to set specific rules for specific locations.
For example, you might have files in your `/public/images` directory that are served at `/images`.
You could define a specific cache time for them and limit them to only static image files.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
#...
# Set a 5 min expiration time for static files in this location.
# Missing files are sent to front controller
# through the '/' location above.
'/images':
expires: 300
passthru: true
# Do not execute PHP scripts from this location and do not
# deliver their source code (for enhanced security).
scripts: false
allow: false
rules:
# Only allow static image files in this location
'\.(jpe?g|png|gif|svgz?|ico|bmp)$':
allow: true
```
###### Complete example
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
root: 'public'
passthru: '/index.php'
index:
- index.php
scripts: true
# No caching for static files.
# (Dynamic pages use whatever cache headers are generated by the program.)
expires: -1
# Allow all file types generally
allow: true
rules:
# Disallow .mp4 files specifically.
\.mp4$:
allow: false
# Set a 5 min expiration time for static files in this location.
# Missing files are sent to front controller
# through the '/' location above.
'/images':
expires: 300
passthru: true
# Do not execute PHP scripts from this location and do not
# deliver their source code (for enhanced security).
scripts: false
allow: false
rules:
# Only allow static image files in this location
'\.(jpe?g|png|gif|svgz?|ico|bmp)$':
allow: true
```
#### Rewrite requests without redirects
You might want to rewrite requests so they're served by specific sections of your app
without having to redirect users.
For example, you might want to make URLs seem semantic to users without having to rewrite your app architecture.
In such a case, you might want requests to `/shoes/great-shoe/` to be served
as if they were requests to `/?category=shoes&product=great-shoe`.
If so, add a [rule](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#rules) similar to the following:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
...
rules:
'^/(?[^/]+)/(?[^/]+)/$':
passthru: '/?category=$category&product=$product'
```
Or you might organize your images by file type, but don't want to expose the organization externally.
You could rewrite requests to do that behind the scenes:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
...
rules:
'^/img/(?.*)\.(?.*)$':
passthru: '/$type/$name.$type'
```
Now a request to `/img/image.png` returns the file found at `/png/image.png`.
###### Query parameters
Query parameters in the request are untouched by rules and will be passed to the app.
For example, if you have the category and product rule from previously, a request to `/shoes/great-shoe/?product=terrible-shoe`
is rewritten to `?category=shoes&product=great-shoe&product=terrible-shoe`.
In that case, the `product` query parameter sent to the app will contain the value `terrible-shoe`.
#### Serve directories at different paths
In some cases you might want to depart from the common practice of serving directories directly.
You might want to create a URL structure different than the structure on your disk.
For example, in Git you might have a folder for your app and another folder that builds your documentation.
Your entire Git repository might look like the following:
```text
.platform/
routes.yaml
services.yaml
applications.yaml
application/
[app-code-files]
docs-src/
[docs-code-files]
```
And your build process might build the documentation with an output folder such as `docs-public`.
If so, you can serve all requests by your app code except for those that start with `/docs`,
which you serve with your generated docs.
Use a [`web` configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web) similar to the following:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
passthru: true
'/docs':
root: 'docs-public'
index:
- "index.html"
expires: 24h
scripts: false
allow: true
```
This way, your app can safely coexist with static files as if it were a single site hierarchy.
And you can keep the static pages separate from your app code.
#### Serve static sites
Static site generators are a popular way to create fast sites.
Because there's no need to wait for responses from servers, the sites may load faster.
As an example, this documentation is built using a tool called Hugo and served by Platform.sh as a static site.
You can see the [entire repository on GitHub](https://github.com/platformsh/platformsh-docs),
including its [app configuration](https://github.com/platformsh/platformsh-docs/blob/main/.platform/applications.yaml).
To learn how to serve your static site using Platform.sh,
you can start with the required [minimal app configuration](#minimal-app-configuration) and build on it,
or jump straight to an [example of a complete configuration](#complete-example-configuration).
###### Minimal app configuration
To successfully serve a static site using Platform.sh,
you need to set up a minimal app configuration similar to the following:
```yaml {location=".platform.app.yaml"}
name: myapp
# The type of the application to build.
type: "nodejs:22"
# The web key configures the web server running in front of your app.
web:
locations:
/:
# Static site generators usually output built static files to a specific directory.
# Define this directory (must be an actual directory inside the root directory of your app)
# as the root for your static site.
root: "public"
# Files to consider when serving a request for a directory.
index:
- index.html
```
See more information on the required minimal settings:
- [Top-level properties](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#top-level-properties).
- [`web` property](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web).
- [`locations` properties](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#locations).
###### Add more features
####### Allow static files but not dynamic files on PHP containers
If you have a PHP container,
you might want to enable client-side scripts but disable server-side scripts.
To enable static files that don't match any rule while disabling server-side scripts on a PHP container,
use the following configuration:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
# ...
scripts: false
allow: true
```
See more information on [`locations` properties](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#locations).
####### Create cache rules
You can create sensible cache rules to improve performance.
For example, if you publish new content regularly without updating images or site files much,
you might want to cache text files for a day but all image files for longer.
To do so, use a configuration similar to the following:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
# ...
expires: 24h
rules:
\.(css|js|gif|jpe?g|png|svg)$:
expires: 4w
```
You can also set a `Cache-Control` header in your rules.
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
# ...
expires: 24h
rules:
\.(css|js|gif|jpe?g|png|svg)$:
headers:
Cache-Control: "public, max-age=2419200, immutable"
```
If `expires` and a `Cache-Control` header are set, the rule ignores the `expires` and sets only the `Cache-Control` header. For this reason, make sure
to add a `max-age` value, in seconds, for the `Cache-Control` header.
####### Conserve the server
Because your site is completely static, it doesn't need the server to be running.
To set a background process that blocks the server and conserves resources,
use the following configuration:
```yaml {location=".platform.app.yaml"}
web:
commands:
start: sleep infinity
```
You can also use this place to start small programs,
such as a [script to handle 404 errors](https://support.platform.sh/hc/en-us/community/posts/16439636723474).
###### Complete example configuration
```yaml {location=".platform.app.yaml"}
name: myapp
type: 'python:3.11'
web:
locations:
'/':
# The public directory of the application relative to its root
root: 'public'
# The files to look for when serving a directory
index:
- 'index.html'
# Disable server-side scripts
scripts: false
allow: true
# Set caching policy
expires: 24h
rules:
\.(css|js|gif|jpe?g|png|svg)$:
expires: 4w
commands:
# Run a no-op process that uses no CPU resources since this is a static site
start: sleep infinity
```
#### Set custom headers on static content
When your app responds to dynamic requests, it can generate headers on the fly.
To set headers for static content, add them in [your `web` configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web).
You might want to do so to add custom content-type headers, limit what other sites can embed your content,
or allow cross origin requests.
Say you want to limit most files to be embedded only on your site, but you want an exception for Markdown files.
And you want to serve both Markdown and [AAC](https://en.wikipedia.org/wiki/Advanced_Audio_Coding) files with the
correct content types to avoid
[MIME sniffing](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types#mime_sniffing).
Start by defining a header for files in general:
```yaml {location=".platform.app.yaml"}
web:
locations:
"/":
...
# Apply rules to all static files (dynamic files get rules from your app)
headers:
X-Frame-Options: SAMEORIGIN
```
This sets the `X-Frame-Options` header to `SAMEORIGIN` for all static files.
Now your files can only be embedded within your site.
Now set up an exception for Markdown (`*.md`) files using a [rule](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#rules):
```yaml {location=".platform.app.yaml"}
web:
locations:
"/":
#...
rules:
\.md$:
headers:
Content-Type: "text/markdown; charset=UTF-8"
```
This rule sets an explicit content type for files that end in `.md`. Because specific rules override the general
heading configuration, Markdown files don't get the `X-Frame-Options` header set before.
**Setting charset**:
By default, [HTTP charset parameters](https://www.w3.org/International/articles/http-charset/index.en) are not sent to the response.
If not set, modern browsers will detect ``ISO-8859-1`` and likely default to ``windows-1252`` as this has 32 more international characters.
To set the HTTP charset parameters to your desired charset, you can add ``; charset=UTF-8`` in the ``Content-Type`` parameters.
Now set a rule for AAC files.
```yaml {location=".platform.app.yaml"}
web:
locations:
"/":
...
rules:
\.aac$:
headers:
X-Frame-Options: SAMEORIGIN
Content-Type: audio/aac
```
This rule sets an explicit content type for files that end in `.aac`. It repeats the rule for `X-Frame-Options` because
the `headers` block here overrides the more general configuration.
So now you have three header configurations:
* `X-Frame-Options: SAMEORIGIN` **and** `Content-Type: audio/aac` for AAC files
* Only `Content-Type: text/markdown` for Markdown files
* Only `X-Frame-Options: SAMEORIGIN` for everything else
###### Cross origin requests
To allow cross origin requests, add a `Access-Control-Allow-Origin` header to responses.
You can do so for specific origins or for all origins with a wildcard.
```yaml {location=".platform.app.yaml"}
web:
locations:
"/":
...
# Apply rules to all static files (dynamic files get rules from your app)
headers:
Access-Control-Allow-Origin: "*"
```
If you use the wildcard value, the headers are modified for each request in the following ways:
* The value of the `Access-Control-Allow-Origin` header is set to the value of the `Origin` request header.
* The `Vary` header is included with a value of `Origin`. See why in the [MDN web docs](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS#access-control-allow-origin).
This is done so that credentialed requests can be supported.
They would otherwise fail CORS checks if the wildcard value is used.
###### `Strict_Transport_Security` header
The `Strict_Transport_Security` header returns a value of `max-age=0`
unless you enable [HTTP Strict Transport Security (HSTS)](https://docs.platform.sh/define-routes/https.md#enable-http-strict-transport-security-hsts)
in your [routes configuration](https://docs.platform.sh/define-routes.md).
Note that once HSTS is enabled, configuration capabilities depend
on the [HSTS properties](https://docs.platform.sh/define-routes/https.md#enable-http-strict-transport-security-hsts)
set in your routes configuration.
For example, the `max-age` value is set to `31536000` by Platform.sh and can't be customized.
### Set up multiple apps in a single project
You can create multiple apps within a single project so they can share data.
This can be useful if you have several apps that are closely related,
such as a backend-only CMS and a frontend system for content delivery and display.
No matter how many apps you have in one project, they're all served by a single [router for the project](https://docs.platform.sh/create-apps/multi-app/routes.md).
To allow your apps to communicate with each other, [create relationships](https://docs.platform.sh/create-apps/multi-app/relationships.md).
Each app separately defines its relationships to [services](https://docs.platform.sh/add-services.md),
so apps can share services or have their own.
#### Choose a project structure
How you structure a project with multiple apps depends on how your code is organized
and what you want to accomplish.
For example, there are various ways you could set up the following multiple apps:

Here are some example use cases and potential ways to organize the project:
| Use case | Structure |
|-----------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------|
| Separate basic apps that are worked on together. | [Unified app configuration](#unified-app-configuration) |
| One app depends on code from another app. | [Nested directories](#nested-directories) |
| You want to keep configuration separate from code, such as through Git submodules. | [Configuration separate from code](#split-your-code-source-into-multiple-git-submodule-repositories) |
| You want multiple apps from the same source code. | [Unified app configuration](#unified-app-configuration) |
| You want to control all apps in a single location. | [Unified app configuration](#unified-app-configuration) |
###### Unified app configuration
You can configure all your apps from a single file.
To do so, create a `.platform/applications.yaml` and define each app as a key.
For example, if you have an API Platform backend with a Symfony API,
a Mercure Rocks server, and a Gatsby frontend,
you can organize your repository like this:
```txt
├── .platform
│ ├── applications.yaml <- Unified app configuration
│ ├── routes.yaml
│ └── services.yaml
├── admin
│ └── ... <- API Platform Admin app code
├── api-app
│ └── ... <- Bigfoot app code
├── gatsby
│ └── ... <- Gatsby app code
└── mercure
└── ... <- Mercure Rocks app code
```
The `api` app is built from the `api-app` directory.
The `admin` app is built from the `admin` directory.
The `gatsby` app is built from the `gatsby` directory.
The `mercure` app is built from the `mercure` directory.
They all have different configurations for how they serve the files. For more details, see the [complete example file](https://github.com/platformsh-templates/bigfoot-multiapp/blob/multiapp-monolith/.platform/applications.yaml).
**Note**:
The ``.platform`` directory is located at the root, separate from your apps.
It contains all the needed configuration files to set up the routing, services and behavior of each app.
Since the code bases of your apps live in a different directory,
you need to [change the source root of each app](#change-the-source-root-of-your-app).
To build multiple apps from the repository root, set ``source.root`` to ``/``.
This allows you to control all your apps in one place and even build multiple apps from the same source code.
To allow your apps to communicate with each other, define [relationships](https://docs.platform.sh/create-apps/multi-app/relationships.md).
Note that with this setup, when you amend the code of one of your apps,
the build image for your other apps can still be reused.
Once your repository is organized, you can use a configuration similar to the following:
```yaml {location=".platform/applications.yaml"}
api:
type: php:8.2
relationships:
database:
service: "database"
endpoint: "postgresql"
mounts:
"/var/cache": "shared:files/cache"
"/var/log": "shared:files/log"
"/var/sessions": "shared:files/sessions"
web:
locations:
"/":
root: "public"
passthru: '/index.php'
index:
- index.php
headers:
Access-Control-Allow-Origin: "*"
hooks:
build: |
set -x -e
curl -s https://get.symfony.com/cloud/configurator | bash
symfony-build
deploy: |
set -x -e
symfony-deploy
source:
root: api-app
admin:
type: nodejs:16
mounts:
'/.tmp_platformsh': 'shared:files/tmp_platformsh'
'/build': 'shared:files/build'
'/.cache': 'shared:files/.cache'
'/node_modules/.cache': 'shared:files/node_modules/.cache'
web:
locations:
"/admin":
root: "build"
passthru: "/admin/index.html"
index:
- "index.html"
headers:
Access-Control-Allow-Origin: "*"
hooks:
build: |
set -eu
corepack yarn install --immutable --force
post_deploy: |
corepack yarn run build
source:
root: admin
gatsby:
type: 'nodejs:18'
mounts:
'/.cache': { source: local, source_path: cache }
'/.config': { source: local, source_path: config }
'/public': { source: local, source_path: public }
web:
locations:
'/site':
root: 'public'
index: [ 'index.html' ]
scripts: false
allow: true
hooks:
build: |
set -e
yarn --frozen-lockfile
post_deploy: |
yarn build --prefix-paths
source:
root: gatsby
mercure:
type: golang:1.18
mounts:
'database': { source: local, source_path: 'database' }
'/.local': { source: local, source_path: '.local' }
'/.config': { source: local, source_path: '.config' }
web:
commands:
start: ./mercure run --config Caddyfile.platform_sh
locations:
/:
passthru: true
scripts: false
request_buffering:
enabled: false
headers:
Access-Control-Allow-Origin: "*"
hooks:
build: |
# Install Mercure using cache
FILE="mercure_${MERCUREVERSION}_Linux_x86_64.tar.gz"
if [ ! -f "$PLATFORM_CACHE_DIR/$FILE" ]; then
URL="https://github.com/dunglas/mercure/releases/download/v${MERCUREVERSION}/$FILE"
wget -O "$PLATFORM_CACHE_DIR/$FILE" $URL
else
echo "Found $FILE in cache, using cache"
fi
file $PLATFORM_CACHE_DIR/$FILE
tar xvzf $PLATFORM_CACHE_DIR/$FILE
source:
root: mercure/.config
```
###### Nested directories
When code bases are separate, changes to one app don't necessarily mean that the other apps in the project get rebuilt.
You might have a situation where app `main` depends on app `languagetool`, but `languagetool` doesn't depend on `main`.
In such cases, you can nest the dependency so the parent (`main`) gets rebuilt on changes to it or its children,
but the child (`languagetool`) is only rebuilt on changes to itself.
For example, you might have a Python app (`main`) that runs a script that requires Java code to be up to date.
But the Java app (`languagetool`) doesn't require updating when the Python app (`main`) is updated.
In that case, you can nest the Java app within the Python app:
```txt
├── .platform
│ ├── applications.yaml
│ └── .platform/routes.yaml
├── languagetool
│ └── main.java <- Java app code
└── main.py <- Python app code
```
The Python app's code base includes all of the files at the top level (excluding the `.platform` directory)
*and* all of the files within the `languagetool` directory.
The Java app's code base includes only the files within the `languagetool` directory.
In this case, your `.platform/applications.yaml` file must contain 2 entries, one for the `main` app and second one for the `languagetool` app.
**Note**:
The ``.platform`` directory is located at the root, separate from your apps.
It contains all the needed configuration files to set up the routing, services and behavior of each app.
Since the code base of the ``languagetool`` app lives in a different directory (``languagetool/``),
you need to [change the source root](#change-the-source-root-of-your-app) of the ``languagetool`` app.
Once your repository is organized, you can use a configuration similar to the following:
```yaml {location=".platform/applications.yaml"}
main:
type: 'python:3.11'
...
languagetool:
type: 'java:17'
source:
root: 'languagetool'
...
```
###### Split your code source into multiple Git submodule repositories
If you have different teams working on different code with different processes,
you might want each app to have its own repository.
Then you can build them together in another repository using [Git submodules](https://git-scm.com/book/en/v2/Git-Tools-Submodules).
With this setup, your apps are kept separate from the top application.
Each app has its own [Git submodule](https://git-scm.com/book/en/v2/Git-Tools-Submodules) containing its code base.
All your apps are configured in a single `.platform/applications.yaml` file.
So you could organize your [project repository](https://github.com/platformsh-templates/bigfoot-multiapp/tree/submodules-root-app-yaml) like this:
```text
├── .platform
│ ├── applications.yaml
│ ├── routes.yaml
│ └── services.yaml
├── @admin <-- API Platform Admin submodule
├── @api <-- Bigfoot submodule
├── @gatsby <-- Gatsby submodule
├── @mercure <-- Mercure rocks submodule
└── .gitmodules
```
[Add the submodules using the Git CLI](https://docs.platform.sh/development/submodules.md#clone-submodules-during-deployment).
Your `.gitmodules` file would define all the submodules like this:
```txt {location=".gitmodules"}
[submodule "admin"]
path = admin
url = https://github.com/platformsh-templates/bigfoot-multiapp-admin.git
[submodule "api"]
path = api
url = https://github.com/platformsh-templates/bigfoot-multiapp-api.git
[submodule "gatsby"]
path = gatsby
url = https://github.com/platformsh-templates/bigfoot-multiapp-gatsby.git
[submodule "mercure"]
path = mercure
url = https://github.com/platformsh-templates/bigfoot-multiapp-mercure.git
```
**Note**:
In this case, and any other case where your app configuration files are kept outside of the app directory,
make sure you [change the source root](#change-the-source-root-of-your-app) for each of your apps.
###### Change the source root of your app
When your app's code base and configuration file aren't located at the same directory level in your project repository,
you need to [define a root directory](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#root-directory) for your app.
To do so, add a new `source.root` property in your app configuration.
For example, to change the source root of the `admin` app
from the [unified app configuration](#unified-app-configuration) example project,
you could add the following configuration:
```yaml {location=".platform/applications.yaml"}
admin:
source:
root: admin
```
The `source.root` path is relative to the repository root.
In this example, the `admin` app now treats the `admin` directory as its root when building.
If `source.root` isn't specified, it defaults to the same directory as the `.platform/applications.yaml` (or `.platform.app.yaml`) file itself.
#### Define routes for your multiple apps
When you set up a project containing multiple applications,
all of your apps are served by a single [router for the project](https://docs.platform.sh/define-routes.md).
Each of your apps must have a `name` that's unique within the project.
To define specific routes for one of your apps, use this `name`.
There are various ways you can define routes for multiple app projects.

In this project, you have a CMS app, two frontend apps (one using Symfony and another using Gatsby),
and a Mercure Rocks server app, defined as follows:
```yaml {location=".platform/applications.yaml"}
admin:
type: nodejs:16
source:
root: admin
...
api:
type: php:8.2
source:
root: api
...
gatsby:
type: nodejs:18
source:
root: gatsby
...
mercure:
type: golang:1.18
source:
root: mercure/.config
...
```
**Note**:
You don’t need to define a route for each app in the repository.
If an app isn’t specified, then it isn’t accessible to the web.
One good example of defining an app with no route is when you [use Git submodules](https://docs.platform.sh/create-apps/multi-app/project-structure.md#split-your-code-source-into-multiple-git-submodule-repositories) and want to [use a source operation to update your submodules](https://docs.platform.sh/development/submodules.md#update-submodules).
You can also achieve the same thing by defining the app as a [worker](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#workers).
Depending on your needs, you could configure the router container
[using subdomains](#define-routes-using-subdomains) or using [subdirectories](#define-routes-using-subdirectories).
####### Define routes using subdomains
You could define routes for your apps as follows:
```yaml {location=".platform/routes.yaml"}
"https://mercure.{default}/":
type: upstream
upstream: "mercure:http"
"https://{default}/":
type: upstream
upstream: "api:http"
```
So if your default domain is `example.com`, that means:
- `https://mercure.example.com/` is served by your Mercure Rocks app (`mercure`).
- `https://example.com/` is served by your Symfony frontend app (`api`).
**Note**:
Using a subdomain might [double your network traffic](https://www.nickolinger.com/blog/2021-08-04-you-dont-need-that-cors-request/),
so consider using a path like ``https://{default}/api`` instead.
####### Define routes using subdirectories
Alternatively, you could define your routes as follows:
```yaml {location=".platform/routes.yaml"}
"https://{default}/":
type: upstream
upstream: "api:http"
"https://{default}/admin":
type: upstream
upstream: "admin:http"
```
Then you would need to configure each app's `web.locations` property to match these paths:
```yaml {location=".platform/applications.yaml"}
api:
type: php:8.2
source:
root: api
...
web:
locations:
"/":
passthru: "/index.php"
root: "public"
index:
- index.php
admin:
type: nodejs:16
source:
root: admin
...
web:
locations:
'/admin':
passthru: '/admin/index.html'
root: 'build'
index:
- 'index.html'
```
So if your default domain is `example.com`, that means:
- `https://example.com/` is served by your Symfony frontend app (`api`).
- `https://example.com/admin` is served by your Admin app (`admin`).
Note that in this example, for the configuration of your `admin` app,
you need to add the URL suffix `/admin` as both an index in the `web.locations` and a value for the `passhtru` setting.
For a complete example, [go to this project on GitHub](https://github.com/platformsh-templates/bigfoot-multiapp/tree/submodules-root-subfolders-applications).
#### Define relationships between your multiple apps
When you set up a project containing multiple applications,
by default your apps can't communicate with each other.
To enable connections, define relationships between apps using the `http` endpoint.
You can't define circular relationships.
If `app1` has a relationship to `app2`, then `app2` can't have a relationship to `app1`.
If you need data to go both ways, consider coordinating through a shared data store,
like a database or [RabbitMQ server](https://docs.platform.sh/add-services/rabbitmq.md).
Relationships between apps use HTTP, not HTTPS.
This is still secure because they're internal and not exposed to the outside world.
###### Relationships example
You have two apps, `app1` and `app2`, and `app1` needs data from `app2`.
In your app configuration for `app1`, define a relationship to `app2`:
```yaml {location=".platform/applications.yaml"}
app1:
relationships:
api:
service: "app2"
endpoint: "http"
```
Once they're both built, `app1` can access `app2` at the following URL: `http://api.internal`.
The specific URL is always available through the [`PLATFORM_RELATIONSHIPS` variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables):
```bash
$ echo $PLATFORM_RELATIONSHIPS | base64 --decode | jq '.api[0].host'
api.internal
```
### Timezones
On Platform.sh, there are several timezones you might want to keep in mind.
All timezones default to UTC time.
You can customize some of them, but in most cases,
it's best if you leave them in UTC
and store user data with an associated timezone instead.
The different timezones on Platform.sh are the following:
| Timezone | Description |Customizable |
|----------------------|----------------------------------------------|--------------|
| Container timezone | The timezone for all Platform.sh containers (UTC). |No |
| App runtime timezone | [Set an app runtime timezone](#set-an-app-runtime-timezone) if you want your app runtime to use a specific timezone instead of the container timezone.
The app runtime timezone only affects your app itself. | Yes |
| Cron timezone | [Set a cron timezone](#set-a-cron-timezone) if you want your crons to run in a specific timezone instead of the app runtime timezone (or instead of the container timezone if no app runtime timezone is set on your project).
The cron timezone only affects your cron jobs. | Yes |
| Log timezone | The timezone for all Platform.sh logs (UTC). | No |
**Note**:
Each Platform.sh project also has a **project timezone** that only affects [automated backups](https://docs.platform.sh/environments/backup.md#use-automated-backups).
By default, the project timezone is based on the [region](https://docs.platform.sh/development/regions.md) where your project is hosted.
You can [change it from the Console](https://docs.platform.sh/projects/change-project-timezone.md) at any time.
##### Set an app runtime timezone
How you can set an app runtime timezone depends on your actual app runtime:
```yaml {}
variables:
php:
"date.timezone": "Europe/Paris"
```
Start the server with ``env TZ=’’ node server.js``.Start the server with ``env TZ=’’ python server.py``.
- Start the server with ``env TZ=’’ java -jar …`` OR.
- Set the Java virtual machine argument ``user.timezone``.
This Java virtual machine argument takes precedence over the environment variable TZ.
For example, you can use the flag ``-D`` when running the application:
``java -jar -D user.timezone=GMT`` or ``java -jar -D user.timezone="Asia/Kolkata"``
##### Set a cron timezone
You can set a specific timezone for your crons so they don't run in your app runtime timezone (or container timezone if no app runtime timezone is set on your project).
To do so, [set the `timezone` top-level property](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#top-level-properties) in your app configuration.
### Troubleshoot disks
For more general information, see how to [troubleshoot development](https://docs.platform.sh/development/troubleshoot.md).
##### Exceeding plan storage limit
Professional plans come with a default amount of storage that you can [change with your plan](https://docs.platform.sh/administration/pricing.md).
The storage is allocated among your services and applications using the `disk` parameter in their configuration files.
You might accidentally set the sum of all `disk` parameters in the files to exceed your plans storage limit.
For example, by setting `disk: 4096` for a MySQL service in `.platform/services.yaml`
and `disk: 4096` in `.platform.app.yaml` for a plan with a 5 GB storage limit.
In such cases, you get an error like the following:
```text
Error: Resources exceeding plan limit; disk: 8192.00MB > 5120.00MB; try removing a service, or add more storage to your plan
```
To fix the error, do one of the following:
* Lower the `disk` parameters to a value within your plan's storage limits.
Note the [limits to downsizing disks](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#downsize-a-disk).
* Increase your plan's storage limits.
This can only be done by people with the [manage plans permission](https://docs.platform.sh/administration/users.md#organization-permissions).
##### Low disk space
If you have set up [health notifications](https://docs.platform.sh/integrations/notifications.md),
you may receive a notification of low disk space.
To solve this issue:
* [Check mount usage](https://docs.platform.sh/create-apps/troubleshoot-mounts.md#disk-space-issues)
* [Check your database disk space](#check-your-database-disk-space) (if applicable)
* [Increase the available disk space](#increase-available-disk-space) (if necessary)
###### Check your database disk space
To get approximate disk usage for a database, run the command `platform db:size`.
This returns an estimate such as the following:
```text
+----------------+-----------------+--------+
| Allocated disk | Estimated usage | % used |
+----------------+-----------------+--------+
| 1.0 GiB | 520.3 MiB | ~ 51% |
+----------------+-----------------+--------+
```
Keep in mind that this estimate doesn't represent the exact real size on disk.
But if you notice that the usage percentage is high, you may need to increase the available space.
###### Increase available disk space
If you find that your application or service is running out of disk space,
you can increase the available storage.
To increase the space available for applications and services,
use the `disk` keys in your `.platform.app.yaml` and `.platform/services.yaml` files.
The sum of all `disk` keys can't exceed the available storage in your plan.
If you need more storage to fit the sum of all `disk` keys, increase your plan's storage limits.
This can only be done by people with the [manage plans permission](https://docs.platform.sh/administration/users.md#organization-permissions).
##### No space left on device
During the `build` hook, you may see the following error:
```text
W: [Errno 28] No space left on device: ...
```
This is caused by the amount of disk provided to the build container before deployment.
Application images are restricted to 8 GB during build, no matter how much writable disk has been set aside for the deployed application.
Some build tools (yarn/npm) store cache for different versions of their modules.
This can cause the build cache to grow over time beyond the maximum.
Try [clearing the build cache](https://docs.platform.sh/development/troubleshoot.md#clear-the-build-cache) and [triggering a redeploy](https://docs.platform.sh/development/troubleshoot.md#force-a-redeploy).
If for some reason your application absolutely requires more than 8 GB during build,
you can open a [support ticket](https://docs.platform.sh/learn/overview/get-support.md) to have this limit increased.
### Troubleshoot mounts
For more general information, see how to [troubleshoot development](https://docs.platform.sh/development/troubleshoot.md).
##### Overlapping folders
If you have a mount with the same name as a directory you've committed to Git or you create such a directory during the build,
you get a message like the following:
```bash
W: The mount '/example' has a path that overlaps with a non-empty folder.
The content of the non-empty folder either comes from:
- your git repository (you may have accidentally committed files).
- or from the build hook.
Please be aware that this content isn't accessible at runtime.
```
This shows that the files in Git or from your build aren't available after the build.
The only files that are available are those in your mount.
To make the files available in the mount, move them away and then copy them into the mount:
1. In the `build` hook, use `mv` to move the files to another location.
```bash
mv example tmp/example
```
2. In the `deploy` hook, use `cp` to copy the files into the mount.
```bash
cp -r tmp/example example
```
To see the files without copying them, temporarily remove the mount from your app configuration.
Then SSH into your app and view the files.
You can then put the mount back in place.
##### Mounted files not publicly accessible
If you've set up mounts to handle files like user uploads, you want to make sure the files are accessible.
Do so by managing their [location](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#locations).
This example defines two mounts, one named `private` and one `upload`:
```yaml {location=".platform.app.yaml"}
mounts:
'private':
source: local
source_path: private
'uploads':
source: local
source_path: uploads
```
With only this definition, their behavior is the same.
To make `uploads` accessible, define a location with different rules as in the following example:
```yaml {location=".platform.app.yaml"}
web:
locations:
'/':
# Handle dynamic requests
root: 'public'
passthru: '/app.php'
# Allow uploaded files to be served, but don't run scripts.
'/uploads':
root: 'uploads'
expires: 300s
scripts: false
allow: true
```
##### Mounts starting with a dot ignored
Platform.sh ignores YAML keys that start with a dot.
This causes a mount like `.myhiddenfolder` to be ignored.
To mount a directory starting with a dot, put a `/` at the start of its definition:
```yaml {location=".platform.app.yaml"}
mounts:
'/.myhiddenfolder':
source: local
source_path: 'myhiddenfolder'
```
##### Disk space issues
If you are worried about how much disk your mounts are using, check the size with the following command:
```bash
platform mount:size
```
You see the total size and what's available for each directory:
```text
Checking disk usage for all mounts on abcdefg123456-main-abcd123--app@ssh.eu.platform.sh...
+-------------------------+-----------+---------+-----------+-----------+----------+
| Mount(s) | Size(s) | Disk | Used | Available | Capacity |
+-------------------------+-----------+---------+-----------+-----------+----------+
| private | 55.2 MiB | 1.9 GiB | 301.5 MiB | 1.6 GiB | 15.5% |
| tmp | 8.3 GiB | 8.9 GiB | 8.8 GiB | 93.0 MiB | 98.8% |
| web/sites/default/files | 212.2 MiB | 9.6 GiB | 1.9 GiB | 7.6 GiB | 20.3% |
+-------------------------+-----------+---------+-----------+-----------+----------+
```
### Upgrading
##### Changes in version 2022.02
* The cron `cmd` syntax is now deprecated in favor of `commands`.
Previous cron job definitions looked like this:
```yaml {location=".platform.app.yaml"}
crons:
sendemails:
spec: '*/7 * * * *'
cmd: cd public && send-pending-emails.sh
```
They should now be written like this:
```yaml {location=".platform.app.yaml"}
crons:
sendemails:
spec: '*/7 * * * *'
commands:
start: cd public && send-pending-emails.sh
```
The new syntax offers greater flexibility and configuration.
For more details, see the [full specification for cron jobs](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#crons).
##### Changes in version 2019.05
* The `!archive` tag in YAML has been un-deprecated, and is now favored over the `!include` option. `!include` is still available for other include types (`yaml`, `binary`, and `string`).
##### Changes in version 2017.11 (2017-11-09)
* The `!archive` tag in YAML files is now deprecated in favor of the more generic [`!include`](https://docs.platform.sh/learn/overview/yaml.md).
For example, the following `.platform/services.yaml` snippet:
```yaml {location=".platform/services.yaml"}
mysearch:
type: solr:6.3
disk: 1024
configuration:
core_config: !archive "myconfdir"
```
Can now be written as:
```yaml {location=".platform/services.yaml"}
mysearch:
type: solr:6.3
disk: 1024
configuration:
core_config: !include
type: archive
path: "myconfdir"
```
* The syntax for the `mounts` key in `.platform.app.yaml` has changed.
Rather than a parsed string, the value of each mount is a [multi-key definition](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts).
That is, the following example:
```yaml {location=".platform.app.yaml"}
mounts:
"tmp": "shared:files/tmp"
"logs": "shared:files/logs"
```
Can now be written as:
```yaml {location=".platform.app.yaml"}
mounts:
tmp:
source: local
source_path: tmp
logs:
source: local
source_path: logs
```
##### Changes in version 2016.6 (2016-11-18)
* Application containers now include the latest LTS version of Node.js, 6.9.1. The previously included version was 4.6.1.
* Composer was briefly called with `--no-dev`, but as of 2016-11-21 this change has been reverted, because of the unintended effect it had on projects using the Symfony framework.
##### Changes in version 2016.5
As of October 2016, the default behaviour of the `expires` key, which controls
client-side caching of static files, has changed. Previously, if the key was
unset, the `Expires` and `Cache-Control` HTTP headers were left unset in the
response, which meant that client side caching behaviour was left undefined.
To ensure consistent behaviour that doesn't depend on which browser the client
is using, the new default behaviour is to set these headers to values that
disable client-side caching. This change only affects static files served
directly by the web server. Responses served from `passthru` URLs continue to use
whatever caching headers were set by the application.
To enable caching on your static files, make sure you include an `expires` key in your [web configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), as shown below:
```yaml {location=".platform.app.yaml"}
web:
locations:
"/":
root: "public"
passthru: "/index.php"
index:
- index.php
expires: 300
scripts: true
allow: true
rules:
\.mp4$:
allow: false
expires: -1
"/sites/default/files":
expires: 300
passthru: true
allow: true
```
##### Changes in version 2016.4
As of July 2016, we no longer create default configuration files if one isn't provided.
The defaults we used to provide were tailored specifically for Drupal 7, which is now a legacy-support version with the release of Drupal 8 and not especially useful for non-Drupal or non-PHP sites.
They also defaulted to software versions that are no longer current and recommended.
Instead, you must provide your own `.platform.app.yaml`, `.platform/routes.yaml`, and `.platform/services.yaml` files.
Additionally, a version for a language or service should always be specified as well. That allows you to control when you upgrade from one version to another without relying on a network default.
The previous default files, for reference, are:
###### Application
```yaml {location=".platform.app.yaml"}
name: php
type: "php:5.4"
build:
flavor: "drupal"
access:
ssh: contributor
relationships:
database: "mysql:mysql"
solr: "solr:solr"
redis: "redis:redis"
web:
document_root: "/"
passthru: "/index.php"
disk: 2048
mounts:
"public/sites/default/files": "shared:files/files"
"tmp": "shared:files/tmp"
"private": "shared:files/private"
crons:
drupal:
spec: "*/20 * * * *"
cmd: "cd public ; drush core-cron"
```
###### Routes
```yaml {location=".platform/routes.yaml"}
"http://{default}/":
type: upstream
upstream: "php:http"
cache:
enabled: true
ssi:
enabled: false
"http://www.{default}/":
type: redirect
to: "http://{default}/"
```
###### Services
```yaml {location=".platform/services.yaml"}
mysql:
type: mysql:5.5
disk: 2048
redis:
type: redis:2.8
solr:
type: solr:3.6
disk: 1024
```
##### Changes in version 2016.3
As we are aiming to always provide you more control and flexibility on how to deploy your applications, the `.platform.app.yaml` format has been greatly improved. It is now way more flexible, and also much more explicit to describe what you want to do.
The `web` key is now a set of `locations` where you can define very precisely the behavior of each URL prefix.
Note, we no longer move your application from "/" to "public/" automatically if the new format is adopted.
If you are using Drupal, move all of your Drupal files into "public/" in the Git repository.
Old format:
```yaml {location=".platform.app.yaml"}
web:
document_root: "/"
passthru: "/index.php"
index_files:
- "index.php"
expires: 300
whitelist:
- \.html$
```
New format:
```yaml {location=".platform.app.yaml"}
web:
locations:
"/":
root: "public"
passthru: "/index.php"
index:
- index.php
expires: 300
scripts: true
allow: true
rules:
\.mp4$:
allow: false
expires: -1
"/sites/default/files":
expires: 300
passthru: true
allow: true
```
###### Backward compatibility
We generally try to keep backward compatibility with previous configuration formats. Here is what happens if you don't upgrade your configuration:
```yaml {location=".platform.app.yaml"}
web:
# The following parameters are automatically moved as a "/" block in the
# "locations" object, and are invalid if there is a valid "locations" block.
document_root: "/public" # Converted to [locations][/][root]
passthru: "/index.php" # Converted to [locations][/][passthru]
index_files:
- index.php # Converted to [locations][/][index]
whitelist: [ ] # Converted to [locations][/][rules]
blacklist: [ ] # Converted to [locations][/][rules]
expires: 3d # Converted to [locations][/][expires]
```
##### Changes in version 2015.7
The `.platform.app.yaml` configuration file now allows for a much clearer syntax, which you can (and should) start using now.
The old format had a single string to identify the `toolstack` you use:
```yaml {location=".platform.app.yaml"}
toolstack: "php:drupal"
```
The new syntax allows to separate the concerns of what language you are running
and the build process that is going to happen on deployment:
```yaml {location=".platform.app.yaml"}
type: php
build:
flavor: drupal
```
Currently we only support `php` in the 'type' key. Current supported build
flavors are `drupal`, `composer` and `symfony`.
##### Changes in version 2014.9
This version introduces changes in
the configuration files format. Most of the old configuration format is
still supported, but customers are invited to move to the new format.
For an example upgrade path, see the [Drupal 7.x branch of the
`platformsh-examples`
repository](https://github.com/platformsh-templates/drupal7/blob/master/.platform.app.yaml)
on GitHub.
Configuration items for PHP that previously was part of
`.platform/services.yaml` are now moved into `.platform.app.yaml`, which
gains the following top-level items:
- `name`: should be `"php"`
- `relationships`, `access` and `disk`: should be the same as the
`relationships` key of PHP in `.platform/services.yaml`
Note that there is now a sane default for `access` (SSH access to PHP is
granted to all users that have role "collaborator" and above on the
environment) so most customers can now just omit this key in
`.platform.app.yaml`.
In addition, version 1.7.0 now has consistency checks for configuration
files and rejects `git push` operations that contain configuration
files that are invalid. In this case, just fix the issues as they are
reported, commit and push again.
### Use build and deploy hooks
As your app goes through the [build and deploy process](https://docs.platform.sh/learn/overview/build-deploy.md),
you might want to run custom commands.
These might include compiling the app, setting the configuration for services based on variables, and rebuilding search indexes.
Do these tasks using one of [three hooks](https://docs.platform.sh/create-apps/hooks/hooks-comparison.md).
The following example goes through each of these hooks for the [Next.js Drupal template](https://github.com/platformsh-templates/nextjs-drupal).
This template uses [Drupal](https://www.drupal.org/) as the headless CMS backend
and [Next.js](https://nextjs.org/) for the frontend.
It's largely based on the [Next.js for Drupal project](https://next-drupal.org/)
The example commands are somewhat simplified, but you can find them all in the [GitHub repository](https://github.com/platformsh-templates/nextjs-drupal).
In this case, you have [two apps](https://docs.platform.sh/create-apps/multi-app.md) and so two [`.platform.app.yaml` configuration files](https://docs.platform.sh/create-apps.md).
Each file is in the folder for that app: `api` for Drupal and `client` for Next.js.
You run one hook for Drupal and two hooks for Next.js.
##### Build dependencies
The Next.js app uses Yarn for dependencies, which need to be installed.
Installing dependencies requires writing to disk and doesn't need any relationships with other services.
This makes it perfect for a `build` hook.
In this case, the app has two sets of dependencies:
* For the main app
* For a script to test connections between the apps
Create your `build` hook to install them all:
1. Create a `build` hook in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md):
```yaml {location=".platform.app.yaml" }
hooks:
build: |
set -e
```
The hook has two parts so far:
* The `|` means the lines that follow can contain a series of commands.
They aren't interpreted as new YAML properties.
* Adding `set -e` means that the hook fails if _any_ of the commands in it fails.
Without this setting, the hook fails only if its _final_ command fails.
If a `build` hook fails for any reason, the build is aborted and the deploy doesn't happen.
Note that this only works for `build` hooks.
If other hooks fail, the deploy still happens.
2. Install your top-level dependencies inside this `build` hook:
```yaml {location="client/.platform.app.yaml"}
hooks:
build: |
set -e
yarn --frozen-lockfile
```
This installs all the dependencies for the main app.
3. Copy the [testing script from the template](https://github.com/platformsh-templates/nextjs-drupal/tree/master/client/platformsh-scripts/test/next-drupal-debug).
Copy the files in this directory into a `client/platformsh-scripts/test` directory.
This script debugs the connection between Next.js and Drupal.
4. In the hook, switch to the directory with the testing script.
Each hook starts in the [app root](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#root-directory).
In this case, the app root is `client`.
To run commands from a different directory, you need to change directories (relative to the app root):
```yaml {location="client/.platform.app.yaml"}
hooks:
build: |
set -e
yarn --frozen-lockfile
cd platformsh-scripts/test
```
5. Install the dependencies for the testing script:
```yaml {location="client/.platform.app.yaml"}
hooks:
build: |
set -e
yarn --frozen-lockfile
cd platformsh-scripts/test
yarn --frozen-lockfile
```
Now all your Next.js dependencies are installed.
##### Configure Drush and Drupal
The example uses [Drush](https://www.drush.org/latest/) to handle routine tasks.
For its configuration, Drush needs the URL of the site.
That means the configuration can't be done in the `build` hook.
During the `build` hook, the site isn't yet deployed and so there is no URL to use in the configuration.
(The [`PLATFORM_ROUTES` variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) isn't available.)
Add the configuration during the `deploy` hook.
This way you can access the URL before the site accepts requests (unlike in the `post_deploy` hook).
The script also prepares your environment to handle requests,
such as by [rebuilding the cache](https://www.drush.org/latest/commands/cache_rebuild/)
and [updating the database](https://www.drush.org/latest/commands/updatedb/).
Because these steps should be done before the site accepts request, they should be in the `deploy` hook.
All of this configuration and preparation can be handled in a bash script.
1. Copy the [preparation script from the Platform.sh template](https://github.com/platformsh-templates/nextjs-drupal/blob/master/api/platformsh-scripts/hooks.deploy.sh)
into a file called `hooks.deploy.sh` in a `api/platformsh-scripts` directory.
Note that hooks are executed using the dash shell, not the bash shell used by SSH logins.
2. Copy the [Drush configuration script from the template](https://github.com/platformsh-templates/nextjs-drupal/blob/master/api/drush/platformsh_generate_drush_yml.php)
into a `drush/platformsh_generate_drush_yml.php` file.
3. Set a [mount](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts).
Unlike in the `build` hook, in the `deploy` hook the system is generally read-only.
So create a mount where you can write the Drush configuration:
```yaml {location="api/.platform.app.yaml"}
mounts:
/.drush:
source: storage
source_path: 'drush'
```
4. Add a `deploy` hook that runs the preparation script:
```yaml {location="api/.platform.app.yaml"}
hooks:
deploy: !include
type: string
path: platformsh-scripts/hooks.deploy.sh
```
This `!include` syntax tells the hook to process the script as if it were included in the YAML file directly.
This helps with longer and more complicated scripts.
##### Get data from Drupal to Next.js
This Next.js app generates a static site.
Often, you would generate the site for Next.js in a `build` hook.
In this case, you first need to get data from Drupal to Next.js.
This means you need to wait until Drupal is accepting requests
and there is a relationship between the two apps.
So the `post_deploy` hook is the perfect place to build your Next.js site.
You can also redeploy the site every time content changes in Drupal.
On redeploys, only the `post_deploy` hook runs,
meaning the Drupal build is reused and Next.js is built again.
So you don't have to rebuild Drupal but you still get fresh content.
1. Set a relationship for Next.js with Drupal.
This allows the Next.js app to make requests and receive data from the Drupal app.
```yaml {location="client/.platform.app.yaml"}
relationships:
api:
service: 'api'
endpoint: 'http'
```
2. Set [mounts](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts).
Like the [`deploy` hook](#configure-drush-and-drupal), the `post_deploy` hook has a read-only file system.
Create mounts for your Next.js files:
```yaml {location="client/.platform.app.yaml"}
mounts:
/.cache:
source: local
source_path: 'cache'
/.next:
source: local
source_path: 'next'
/.pm2:
source: local
source_path: 'pm2'
deploy:
source: service
service: files
source_path: deploy
```
3. Add a `post_deploy` hook that first tests the connection between the apps:
```yaml {location="client/.platform.app.yaml"}
hooks:
post_deploy: |
. deploy/platformsh.environment
cd platformsh-scripts/test && yarn debug
```
Note that you could add `set -e` here, but even if the job fails, the build/deployment itself can still be counted as successful.
4. Then build the Next.js site:
```yaml {location="client/.platform.app.yaml"}
hooks:
post_deploy: |
. deploy/platformsh.environment
cd platformsh-scripts/test && yarn debug
cd $PLATFORM_APP_DIR && yarn build
```
The `$PLATFORM_APP_DIR` variable represents the app root and can always get you back there.
##### Final hooks
You can find the complete [Drupal configuration](https://github.com/platformsh-templates/nextjs-drupal/blob/master/api/.platform.app.yaml)
and [Next.js configuration](https://github.com/platformsh-templates/nextjs-drupal/blob/master/client/.platform.app.yaml)
on GitHub.
The following shows only the parts necessary for the hooks.
###### Drupal
```yaml {location="api/.platform.app.yaml"}
# The name of this app. Must be unique within the project.
name: 'drupal'
# The runtime the app uses.
type: 'php:8.1'
dependencies:
php:
composer/composer: '^2'
# The relationships of the app with services or other apps.
relationships:
database:
service: 'db'
endpoint: 'mysql'
redis:
service: 'cache'
endpoint: 'redis'
# The hooks executed at various points in the lifecycle of the app.
hooks:
deploy: !include
type: string
path: platformsh-scripts/hooks.deploy.sh
# The size of the persistent disk of the app (in MB).
disk: 2048
# The 'mounts' describe writable, persistent filesystem mounts in the app.
mounts:
/.drush:
source: local
source_path: 'drush'
/drush-backups:
source: local
source_path: 'drush-backups'
deploy:
source: service
service: files
source_path: deploy
```
###### Next.js
```yaml {location="client/.platform.app.yaml"}
# The name of this app, which must be unique within the project.
name: 'nextjs'
# The type key specifies the language and version for your app.
type: 'nodejs:14'
dependencies:
nodejs:
yarn: "1.22.17"
pm2: "5.2.0"
build:
flavor: none
relationships:
api:
service: 'api'
endpoint: 'http'
# The hooks that are triggered when the package is deployed.
hooks:
build: |
set -e
yarn --frozen-lockfile # Install dependencies for the main app
cd platformsh-scripts/test
yarn --frozen-lockfile # Install dependencies for the testing script
# Next.js's build is delayed to the post_deploy hook, when Drupal is available for requests.
post_deploy: |
. deploy/platformsh.environment
cd platformsh-scripts/test && yarn debug
cd $PLATFORM_APP_DIR && yarn build
# The size of the persistent disk of the app (in MB).
disk: 512
mounts:
/.cache:
source: local
source_path: 'cache'
/.next:
source: local
source_path: 'next'
/.pm2:
source: local
source_path: 'pm2'
deploy:
source: service
service: files
source_path: deploy
```
#### Change hooks in different environments
You might have certain commands you want to run only in certain environments.
For example enabling detailed logging in preview environments
or purging your CDN cache for production environments.
The `deploy` and `post_deploy` hooks can access all [runtime environment variables](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
Use this to vary those hooks based on the environment.
Check the `PLATFORM_ENVIRONMENT_TYPE` variable to see if it's in a production environment:
```yaml {location=".platform.app.yaml"}
hooks:
deploy: |
if [ "$PLATFORM_ENVIRONMENT_TYPE" = production ]; then
# Run commands only when deploying to production
else
# Run commands only when deploying to development or staging environments
fi
# Commands to run regardless of the environment
```
#### Comparison of hooks
The following table presents the main differences among the three available hooks:
| Hook name | Failures stop build | Variables available | Services available | Timeout | Run on `worker` instances | Writable directories | Blocks requests | Runs on all redeploys\* |
| ------------- | ------------------- |-------------------- | ------------------ | ------- | ------------------------- | -------------------- | --------------- | --------------- |
| `build` | Yes | Build variables | No | 1 hour | Yes | `$PLATFORM_APP_DIR`, `$PLATFORM_CACHE_DIR`, and `/tmp` | No | No |
| `deploy` | No | Runtime variables | Yes | None | No | [Mounts](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts) | Yes | No |
| `post_deploy` | No | Runtime variables | Yes | None | No | [Mounts](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts) | No | Yes |
\* All of the hooks run with changes to the code or environment.
This column indicates which hooks run on a redeploy without any code changes.
###### Build hook
The `build` hook is run after any [build flavor](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#build).
During this hook, no services (such as a database) or any persistent file mounts are available
as the application hasn't yet been deployed.
The `build` hook can only use [environment variables](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables)
that are available at build time.
During the `build` hook, there are three writeable directories:
- `$PLATFORM_APP_DIR`:
This is where your code is checked out and is the working directory when the `build` hook starts.
The contents of this directory after the build hook is the application that gets deployed.
- `$PLATFORM_CACHE_DIR`:
This directory persists between builds, but isn't deployed as part of your application.
It's a good place for temporary build artifacts that can be reused between builds.
It's shared by all builds on all branches.
- `/tmp`:
The temp directory is also useful for writing files that aren't needed in the final application,
but it's wiped between each build.
Note that `$PLATFORM_CACHE_DIR` is mapped to `/tmp`
and together they offer about 8GB of free space.
The only constraint on what can be downloaded during a `build` hook is the disk space available for builds.
This is _not_ the `disk` specified in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#top-level-properties).
If you exceed this limit, you receive a `No space left on device` error.
See how to [troubleshoot this error](https://docs.platform.sh/create-apps/troubleshoot-disks.md#no-space-left-on-device).
The `build` hook runs only when the app or its runtime (variables and such) have changed.
Redeploys with no changes trigger only the `post_deploy` hook.
If you need the `build` hook to run, [manually trigger a build](https://docs.platform.sh/development/troubleshoot.md#manually-trigger-builds).
Each hook is executed as a single script, so they're considered to have failed only if the final command in them fails.
To cause them to fail on the first failed command, add `set -e` to the beginning of the hook.
If a `build` hook fails for any reason, the build is aborted and the deploy doesn't happen.
Note that this only works for `build` hooks.
If other hooks fail, the deploy still happens.
####### Timeout
Build hooks automatically time out if they run for 1 hour.
So if you accidentally add an unbroken loop, it gets cut off and you can continue with other activities.
###### Deploy hook
The `deploy` hook is run after the app container has been started but before it has started accepting requests.
Note that the deploy hook only runs on [`web` instances](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web),
not [`worker` instances](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#workers).
You can access other services at this stage (such as MySQL, Solr, Redis).
The disk where the application lives is read-only at this point.
This hook should be used when something needs to run once when new code is deployed.
It isn't run when a host is restarted (such as during region maintenance),
so anything that needs to run each time an instance of an app starts (regardless of whether there's new code)
should go in the `pre_start` key in [your `web` configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web-commands).
For example, clearing the cache.
Be aware: The deploy hook blocks the site accepting new requests.
If your `deploy` hook is only a few seconds,
incoming requests in that time are paused and continue when the hook is finished.
So it effectively appears as if the site just took a few extra seconds to respond.
If the hook takes too long, requests can't be held and appear as dropped connections.
Only run tasks in your deploy hook that have to be run exclusively,
such as database schema updates or some types of cache clear (those where the code must match what's on the disk).
A task that can safely run concurrently with new incoming requests should be run as a `post_deploy` hook instead.
After a Git push, in addition to the log shown in the activity log,
the execution of the `deploy` hook is logged in the [deploy log](https://docs.platform.sh/increase-observability/logs/access-logs.md#container-logs).
For example:
```bash
[2022-03-01 08:27:25.495579] Launching command 'bash export-config.sh'.
🔥 Successfully cleared configuration
🚀 Added new configuration details
```
Your `deploy` hook is tied to commits in the same way as your builds.
Once a commit has been pushed and a new build image has been created,
the result of both the `build` and `deploy` hooks are reused until there is a new git commit.
Redeploys with no changes trigger only the `post_deploy` hook.
If you need the `deploy` hook to run, [manually trigger a build](https://docs.platform.sh/development/troubleshoot.md#manually-trigger-builds).
###### Post-deploy hook
The `post_deploy` hook functions exactly the same as the `deploy` hook,
but after the container is accepting connections.
It runs concurrently with normal incoming traffic.
That makes it well suited to any updates that don't require exclusive database access.
What's "safe" to run in a `post_deploy` hook vs. in a `deploy` hook varies by the application.
Often times content imports, some types of cache warmups, and other such tasks are good candidates for a `post_deploy` hook.
In addition to the activity log, the `post_deploy` hook logs to the [post-deploy log](https://docs.platform.sh/increase-observability/logs/access-logs.md#container-logs).
The `post_deploy` hook is the only hook that runs during a redeploy.
#### Use hooks with dependencies
If you use a specific package in a hook, you may want to manage dependencies for it.
For example, you may want to compile Sass files as part of your build process.
You can set dependencies along with hooks in your [app configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#dependencies).
The following example assumes you have some Sass source files, such as a `index.scss` file.
You also need a script to compile the files, such as the following:
```json {location="package.json"}
{
"scripts": {
"build-css": "sass index.scss css/index.css"
},
}
```
Set your app configuration to have Sass available globally and use it:
```yaml {location=".platform.app.yaml"}
# Ensure sass is available globally
dependencies:
nodejs:
sass: "^1.47.0"
hooks:
# Run the script defined in package.json
build: |
npm run build-css
```
### Work with workers
Workers are instances of your code that aren't open to connections from other apps or services or the outside world.
They're good for handling background tasks.
See how to [configure a worker](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#workers) for your app.
Note that to have enough resources to support a worker and a service, you need at least a [Medium
plan](https://docs.platform.sh/administration/pricing.md#multiple-apps-in-a-single-project).
##### Access the worker container
Like with any other application container,
Platform.sh allows you to connect to the worker instance through SSH to inspect logs and interact with it.
Use the `--worker` switch in the Platform.sh CLI, like so:
```bash
platform ssh --worker=queue
```
##### Stopping a worker
If a worker instance needs to be updated during a new deployment,
a `SIGTERM` signal is first sent to the worker process to allow it to shut down gracefully.
If your worker process can't be interrupted mid-task, make sure it reacts to `SIGTERM` to pause its work gracefully.
If the process is still running after 15 seconds, a `SIGKILL` message is sent that force-terminates the worker process,
allowing the container to be shut down and restarted.
To restart a worker manually, [access the container](#access-the-worker-container) and run the following commands:
```bash
sv stop app
sv start app
```
##### Workers vs cron jobs
Worker instances don't run cron jobs.
Instead, both worker instances and cron tasks address similar use cases.
They both address out-of-band work that an application needs to do
but that shouldn't or can't be done as part of a normal web request.
They do so in different ways and so are fit for different use cases.
A cron job is well suited for tasks when:
* They need to happen on a fixed schedule, not continually.
* The task itself isn't especially long, as a running cron job blocks a new deployment.
* It's long but can be divided into many small queued tasks.
* A delay between when a task is registered and when it actually happens is acceptable.
A dedicated worker instance is a better fit if:
* Tasks should happen "now", but not block a web request.
* Tasks are large enough that they risk blocking a deploy, even if they're subdivided.
* The task in question is a continually running process rather than a stream of discrete units of work.
The appropriateness of one approach over the other also varies by language;
single-threaded languages would benefit more from either cron or workers than a language with native multi-threading, for instance.
If a given task seems like it would run equally well as a worker or as a cron,
cron is generally more efficient as it doesn't require its own container.
##### Commands
The `commands` key defines the command to launch the worker application.
For now there is only a single command, `start`, but more will be added in the future.
The `commands.start` property is required.
The `start` key specifies the command to use to launch your worker application.
It may be any valid shell command, although most often it runs a command in your application in the language of your application.
If the command specified by the `start` key terminates, it's restarted automatically.
Note that [`deploy` and `post_deploy` hooks](https://docs.platform.sh/create-apps/hooks.md) as well as [`cron` commands](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#crons)
run only on the [`web`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#web) container, not on workers.
##### Inheritance
Any top-level definitions for [`size`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#sizes), [`relationships`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships),
[`access`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#access), [`disk`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md), [`mount`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#mounts), and [`variables`](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#variables)
are inherited by every worker, unless overridden explicitly.
That means, for example, that the following two `.platform.app.yaml` definitions produce identical workers.
```yaml {location=".platform.app.yaml"}
name: myapp
type: python:3.13
disk: 256
mounts:
test:
source: local
source_path: test
relationships:
mysql:
workers:
queue:
commands:
start: |
python queue-worker.py
mail:
commands:
start: |
python mail-worker.py
```
```yaml {location=".platform.app.yaml"}
name: myapp
type: python:3.13
workers:
queue:
commands:
start: |
python queue-worker.py
disk: 256
mounts:
test:
source: local
source_path: test
relationships:
mysql:
mail:
commands:
start: |
python mail-worker.py
disk: 256
mounts:
test:
source: local
source_path: test
relationships:
mysql:
```
In both cases, there are two worker instances named `queue` and `mail`.
Both have access to a MySQL/MariaDB service defined in `.platform/services.yaml` named `mysqldb` through the `database` relationship.
Both also have their own separate, independent local disk mount at `/app/test` with 256 MB of allowed space.
##### Customizing a worker
The most common properties to set in a worker to override the top-level settings are `size` and `variables`.
`size` lets you allocate fewer resources to a container that is running only a single background process
(unlike the web site which is handling many requests at once),
while `variables` lets you instruct the application to run differently as a worker than as a web site.
For example, consider the following configuration:
```yaml {location=".platform/services.yaml"}
mysql:
type: "mariadb:11.8"
disk: 2048
rabbitmq:
type: rabbitmq:4.1
disk: 512
```
```yaml {location=".platform.app.yaml"}
name: myapp
type: "python:3.13"
disk: 2048
hooks:
build: |
pip install -r requirements.txt
pip install -e .
pip install gunicorn
relationships:
mysql:
rabbitmq:
variables:
env:
type: 'none'
web:
commands:
start: "gunicorn -b $PORT project.wsgi:application"
variables:
env:
type: 'web'
mounts:
uploads:
source: local
source_path: uploads
locations:
"/":
root: ""
passthru: true
allow: false
"/static":
root: "static/"
allow: true
workers:
queue:
size: 'M'
commands:
start: |
python queue-worker.py
variables:
env:
type: 'worker'
disk: 512
mounts:
scratch:
source: local
source_path: scratch
mail:
size: 'S'
commands:
start: |
python mail-worker.py
variables:
env:
type: 'worker'
disk: 256
mounts: {}
relationships:
rabbitmq:
```
There's a lot going on here, but it's all reasonably straightforward.
The configuration in `.platform.app.yaml` takes a single Python 3.13 code base from your repository,
downloads all dependencies in `requirements.txt`, and then installs Gunicorn.
That artifact (your code plus the downloaded dependencies) is deployed as three separate container instances, all running Python 3.13.
The `web` instance starts a Gunicorn process to serve a web application.
- It runs the Gunicorn process to serve web requests, defined by the `project/wsgi.py` file which contains an `application` definition.
- It has an environment variable named `TYPE` with value `web`.
- It has a writable mount at `/app/uploads` with a maximum space of 2048 MB.
- It has access to both a MySQL database and a RabbitMQ server, both of which are defined in `.platform/services.yaml`.
- Platform.sh automatically allocates resources to it as available on the plan, once all fixed-size containers are allocated.
The `queue` instance is a worker that isn't web-accessible.
- It runs the `queue-worker.py` script, and restart it automatically if it ever terminates.
- It has an environment variable named `TYPE` with value `worker`.
- It has a writable mount at `/app/scratch` with a maximum space of 512 MB.
- It has access to both a MySQL database and a RabbitMQ server,
both of which are defined in `.platform/services.yaml` (because it doesn't specify otherwise).
- It has "Medium" levels of CPU and RAM allocated to it, always.
The `mail` instance is a worker that isn't web-accessible.
- It runs the `mail-worker.py` script, and restart it automatically if it ever terminates.
- It has an environment variable named `TYPE` with value `worker`.
- It has no writable file mounts at all.
- It has access only to the RabbitMQ server, through a different relationship name than on the `web` instance.
It has no access to MySQL.
- It has "Small" levels of CPU and RAM allocated to it, always.
This way, the web instance has a large upload space, the queue instance has a small amount of scratch space for temporary files,
and the mail instance has no persistent writable disk space at all as it doesn't need it.
The mail instance also doesn't need any access to the SQL database so for security reasons it has none.
The workers have known fixed sizes, while web can scale to as large as the plan allows.
Each instance can also check the `TYPE` environment variable to detect how it's running
and, if appropriate, vary its behavior accordingly.
### Elasticsearch (Search service)
Elasticsearch is a distributed RESTful search engine built for the cloud.
See the [Elasticsearch documentation](https://www.elastic.co/guide/en/elasticsearch/reference/current/index.md) for more information.
##### Use a framework
If you use one of the following frameworks, follow its guide:
- [Drupal](https://docs.platform.sh/guides/drupal/elasticsearch.md)
- [Jakarta EE](https://docs.platform.sh/guides/jakarta/deploy.md#elasticsearch)
- [Micronaut](https://docs.platform.sh/guides/micronaut/elasticsearch.md)
- [Quarkus](https://docs.platform.sh/guides/quarkus/elasticsearch.md)
- [Spring](https://docs.platform.sh/guides/spring/elasticsearch.md)
##### Supported versions
From version 7.11 onward:
**Premium Service**:
Elasticsearch isn’t included in any Platform.sh plan.
You need to add it separately at an additional cost.
To add Elasticsearch, [contact Sales](https://platform.sh/contact/).
The following premium versions are supported:
| Grid | Dedicated Gen 2 |
|
- 8.5
- 7.17
- 7.2
- 7.5
- 7.6
- 7.7
- 7.9
- 7.10
- 7.17
- 8.5
- 8.8
You can select the major and minor version.
Patch versions are applied periodically for bug fixes and the like.
When you deploy your app, you always get the latest available patches.
##### Deprecated versions
The following versions are still available in your projects for free,
but they're at their end of life and are no longer receiving security updates from upstream.
| Grid | Dedicated Gen 2 |
|
- 7.10
- 7.9
- 7.7
- 7.5
- 7.2
- 6.8
- 6.5
- 5.4
- 5.2
- 2.4
- 1.7
- 1.4
- 6.8
- 6.5
- 5.6
- 5.2
- 2.4
- 1.7
To ensure your project remains stable in the future,
switch to [a premium version](#supported-versions).
Alternatively, you can switch to one of the latest, free versions of [OpenSearch](https://docs.platform.sh/add-services/opensearch.md).
To do so, follow the same procedure as for [upgrading](#upgrading).
##### Relationship reference
Example information available through the [`PLATFORM_RELATIONSHIPS` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables)
or by running `platform relationships`.
Note that the information about the relationship can change when an app is redeployed or restarted or the relationship is changed. So your apps should only rely on the `PLATFORM_RELATIONSHIPS` environment variable directly rather than hard coding any values.
```json
{
"username": null,
"scheme": "http",
"service": "elasticsearch",
"fragment": null,
"ip": "123.456.78.90",
"hostname": "azertyuiopqsdfghjklm.elasticsearch.service._.eu-1.platformsh.site",
"port": 9200,
"cluster": "azertyuiopqsdf-main-7rqtwti",
"host": "elasticsearch.internal",
"rel": "elasticsearch",
"path": null,
"query": [],
"password": "ChangeMe",
"type": "elasticsearch:8.5",
"public": false,
"host_mapped": false
}
```
For [premium versions](#supported-versions), the service type is `elasticsearch-enterprise`.
##### Usage example
###### 1. Configure the service
To define the service, use the `elasticsearch` type:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: elasticsearch:
disk: 256
```
If you’re using a [premium version](add-services/elasticsearch.md#supported-versions), use the `elasticsearch-enterprise` type instead.
Note that changing the name of the service replaces it with a brand new service and all existing data is lost.
Back up your data before changing the service.
###### 2. Define the relationship
To define the relationship, use the following configuration:
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services
and matches in both the application and services configuration.
The example above leverages [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
That is, it uses default endpoints behind-the-scenes, providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships)
(the network address a service is accessible from) that is identical to the name of that service.
Depending on your needs, instead of default endpoint configuration,
you can use [explicit endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#use-in-app) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: elasticsearch
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#use-in-app) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
###### Example configuration
###### [Service definition](https://docs.platform.sh/add-services.md)
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
elasticsearch:
type: elasticsearch:8.5
disk: 256
```
If you're using a [premium version](add-services/elasticsearch.md#supported-versions),
use the `elasticsearch-enterprise` type in the service definition.
####### [App configuration](https://docs.platform.sh/create-apps.md)
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
elasticsearch:
```
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
elasticsearch:
service: elasticsearch
endpoint: elasticsearch
```
###### Use in app
To use the configured service in your app, add a configuration file similar to the following to your project.
Note that configuration for [premium versions](#supported-versions) may differ slightly.
```js {}
const elasticsearch = require("elasticsearch");
const config = require("platformsh-config").config();
exports.usageExample = async function () {
const credentials = config.credentials("elasticsearch");
const client = new elasticsearch.Client({
host: `${credentials.host}:${credentials.port}`,
});
const index = "my_index";
const type = "People";
// Index a few document.
const names = ["Ada Lovelace", "Alonzo Church", "Barbara Liskov"];
const message = {
refresh: "wait_for",
body: names.flatMap((name) => [
{ index: { _index: index, _type: type } },
{ name },
]),
};
await client.bulk(message);
// Search for documents.
const response = await client.search({
index,
q: "name:Barbara Liskov",
});
const outputRows = response.hits.hits
.map(
({ _id: id, _source: { name } }) =>
`| ${id} | ${name} |
\n`
)
.join("\n");
// Clean up after ourselves.
await Promise.allSettled(
response.hits.hits.map(({ _id: id }) =>
client.delete({
index: index,
type: type,
id,
})
)
);
return `
`;
};
```
```php {}
credentials('elasticsearch');
try {
// The Elasticsearch library lets you connect to multiple hosts.
// On Platform.sh Standard there is only a single host so just
// register that.
$hosts = [
[
'scheme' => $credentials['scheme'],
'host' => $credentials['host'],
'port' => $credentials['port'],
]
];
// Create an Elasticsearch client object.
$builder = ClientBuilder::create();
$builder->setHosts($hosts);
$client = $builder->build();
$index = 'my_index';
$type = 'People';
// Index a few document.
$params = [
'index' => $index,
'type' => $type,
];
$names = ['Ada Lovelace', 'Alonzo Church', 'Barbara Liskov'];
foreach ($names as $name) {
$params['body']['name'] = $name;
$client->index($params);
}
// Force just-added items to be indexed.
$client->indices()->refresh(array('index' => $index));
// Search for documents.
$result = $client->search([
'index' => $index,
'type' => $type,
'body' => [
'query' => [
'match' => [
'name' => 'Barbara Liskov',
],
],
],
]);
if (isset($result['hits']['hits'])) {
print <<
| ID | Name |
|---|
TABLE;
foreach ($result['hits']['hits'] as $record) {
printf("| %s | %s |
\n", $record['_id'], $record['_source']['name']);
}
print "\n
\n";
}
// Delete documents.
$params = [
'index' => $index,
'type' => $type,
];
$ids = array_map(function($row) {
return $row['_id'];
}, $result['hits']['hits']);
foreach ($ids as $id) {
$params['id'] = $id;
$client->delete($params);
}
} catch (Exception $e) {
print $e->getMessage();
}
```
```python {}
import elasticsearch
from platformshconfig import Config
def usage_example():
# Create a new Config object to ease reading the Platform.sh environment variables.
# You can alternatively use os.environ yourself.
config = Config()
# Get the credentials to connect to the Elasticsearch service.
credentials = config.credentials('elasticsearch')
try:
# The Elasticsearch library lets you connect to multiple hosts.
# On Platform.sh Standard there is only a single host so just register that.
hosts = {
"scheme": credentials['scheme'],
"host": credentials['host'],
"port": credentials['port']
}
# Create an Elasticsearch client object.
client = elasticsearch.Elasticsearch([hosts])
# Index a few documents
es_index = 'my_index'
es_type = 'People'
params = {
"index": es_index,
"type": es_type,
"body": {"name": ''}
}
names = ['Ada Lovelace', 'Alonzo Church', 'Barbara Liskov']
ids = {}
for name in names:
params['body']['name'] = name
ids[name] = client.index(index=params["index"], doc_type=params["type"], body=params['body'])
# Force just-added items to be indexed.
client.indices.refresh(index=es_index)
# Search for documents.
result = client.search(index=es_index, body={
'query': {
'match': {
'name': 'Barbara Liskov'
}
}
})
table = '''
| ID | Name |
|---|
'''
if result['hits']['hits']:
for record in result['hits']['hits']:
table += '''| {0} | {1} |
\n'''.format(record['_id'], record['_source']['name'])
table += '''
\n
\n'''
# Delete documents.
params = {
"index": es_index,
"type": es_type,
}
for name in names:
client.delete(index=params['index'], doc_type=params['type'], id=ids[name]['_id'])
return table
except Exception as e:
return e
```
**Note**:
When you create an index on Elasticsearch,
don’t specify the ``number_of_shards`` or ``number_of_replicas`` settings in your Elasticsearch API call.
These values are set automatically based on available resources.
##### Authentication
By default, Elasticsearch has no authentication.
No username or password is required to connect to it.
Starting with Elasticsearch 7.2 you may optionally enable HTTP Basic authentication.
To do so, include the following in your `.platform/services.yaml` configuration:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
elasticsearch:
type: elasticsearch:8.5
disk: 2048
configuration:
authentication:
enabled: true
```
If you're using a [premium version](#supported-versions),
use the `elasticsearch-enterprise` type.
That enables mandatory HTTP Basic auth on all requests.
The credentials are available in any relationships that point at that service,
in the `username` and `password` properties.
Note that the information about the relationship can change when an app is redeployed or restarted or the relationship is changed. So your apps should only rely on the `PLATFORM_RELATIONSHIPS` environment variable directly rather than hard coding any values.
This functionality is generally not required if Elasticsearch isn't exposed on its own public HTTP route.
However, certain applications may require it, or it allows you to safely expose Elasticsearch directly to the web.
To do so, add a route to `.platform/routes.yaml` that has `elasticsearch:elasticsearch` as its upstream
(where `elasticsearch` is whatever you named the service).
For example:
```yaml {location=".platform/routes.yaml"}
"https://es.{default}/":
type: upstream
upstream: "elasticsearch:elasticsearch"
```
##### Plugins
Elasticsearch offers a number of plugins.
To enable them, list them under the `configuration.plugins` key in your `.platform/services.yaml` file, like so:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
elasticsearch:
type: elasticsearch:8.5
disk: 1024
configuration:
plugins:
- analysis-icu
```
If you're using a [premium version](#supported-versions),
use the `elasticsearch-enterprise` type.
In this example you'd have the ICU analysis plugin and Python script support plugin.
If there is a publicly available plugin you need that isn't listed here, [contact support](https://docs.platform.sh/learn/overview/get-support.md).
###### Available plugins
This is the complete list of official Elasticsearch plugins that can be enabled:
| Plugin | Description | 2.4 | 5.x | 6.x | 7.x | 8.x |
|-------------------------|-------------------------------------------------------------------------------------------|-----|-----|-----|-----|-----|
| `analysis-icu` | Support ICU Unicode text analysis | * | * | * | * | * |
| `analysis-nori` | Integrates Lucene Nori analysis module into Elasticsearch | | | * | * | * |
| `analysis-kuromoji` | Japanese language support | * | * | * | * | * |
| `analysis-smartcn` | Smart Chinese Analysis Plugins | * | * | * | * | * |
| `analysis-stempel` | Stempel Polish Analysis Plugin | * | * | * | * | * |
| `analysis-phonetic` | Phonetic analysis | * | * | * | * | * |
| `analysis-ukrainian` | Ukrainian language support | | * | * | * | * |
| `cloud-aws` | AWS Cloud plugin, allows storing indices on AWS S3 | * | | | | |
| `delete-by-query` | Support for deleting documents matching a given query | * | | | | |
| `discovery-multicast` | Ability to form a cluster using TCP/IP multicast messages | * | | | | |
| `ingest-attachment` | Extract file attachments in common formats (such as PPT, XLS, and PDF) | | * | * | * | * |
| `ingest-user-agent` | Extracts details from the user agent string a browser sends with its web requests | | * | * | | |
| `lang-javascript` | JavaScript language plugin, allows the use of JavaScript in Elasticsearch scripts | | * | | | |
| `lang-python` | Python language plugin, allows the use of Python in Elasticsearch scripts | * | * | | | |
| `mapper-annotated-text` | Adds support for text fields with markup used to inject annotation tokens into the index | | | * | * | * |
| `mapper-attachments` | Mapper attachments plugin for indexing common file types | * | * | | | |
| `mapper-murmur3` | Murmur3 mapper plugin for computing hashes at index-time | * | * | * | * | * |
| `mapper-size` | Size mapper plugin, enables the `_size` meta field | * | * | * | * | * |
| `repository-s3` | Support for using S3 as a repository for Snapshot/Restore | | * | * | * | * |
| `transport-nio` | Support for NIO transport | | | | * | * |
###### Plugin removal
Removing plugins previously added in your `.platform/services.yaml` file doesn't automatically uninstall them from your Elasticsearch instances.
This is deliberate, as removing a plugin may result in data loss or corruption of existing data that relied on that plugin.
Removing a plugin usually requires reindexing.
To permanently remove a previously enabled plugin,
[upgrade the service](#upgrading) to create a new instance of Elasticsearch and migrate to it.
In most cases it isn't necessary as an unused plugin has no appreciable impact on the server.
##### Upgrading
The Elasticsearch data format sometimes changes between versions in incompatible ways.
Elasticsearch doesn't include a data upgrade mechanism as it's expected that all indexes can be regenerated from stable data if needed.
To upgrade (or downgrade) Elasticsearch, use a new service from scratch.
There are two ways to do so.
###### Destructive
In your `.platform/services.yaml` file, change the version *and* name of your Elasticsearch service.
Be sure to also update the reference to the now changed service name in its corresponding application's `relationship` block.
When you push that to Platform.sh, the old service is deleted and a new one with the new name is created with no data.
You can then have your application reindex data as appropriate.
This approach has the downsides of temporarily having an empty Elasticsearch instance,
which your application may or may not handle gracefully, and needing to rebuild your index afterward.
Depending on the size of your data that could take a while.
###### Transitional
With a transitional approach, you temporarily have two Elasticsearch services.
Add a second Elasticsearch service with the new version, a new name, and give it a new relationship in `.platform.app.yaml`.
You can optionally run in that configuration for a while to allow your application to populate indexes in the new service as well.
Once you're ready to switch over, remove the old Elasticsearch service and relationship.
You may optionally have the new Elasticsearch service use the old relationship name if that's easier for your app to handle.
Your application is now using the new Elasticsearch service.
This approach has the benefit of never being without a working Elasticsearch instance.
On the downside, it requires two running Elasticsearch servers temporarily,
each of which consumes resources and needs adequate disk space.
Depending on the size of your data, that may be a lot of disk space.
### Gotenberg
Gotenberg is a stateless API for converting various document formats into PDF files.
For more information, see the [Gotenberg documentation](https://gotenberg.dev/docs/getting-started/introduction).
##### Supported versions
- 8
You can select the major version. But the latest compatible minor version is applied automatically and can’t be overridden.
Patch versions are applied periodically for bug fixes and the like.
When you deploy your app, you always get the latest available patches.
##### Relationship reference
Example information available through the [`PLATFORM_RELATIONSHIPS` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables)
or by running `platform relationships`.
```json
{
"host": "gotenberg.internal",
"hostname": "azertyuiopqsdfghjklm.gotenberg.service._.eu-1.platformsh.site",
"cluster": "azertyuiopqsdf-main-7rqtwti",
"service": "gotenberg",
"rel": "http",
"scheme": "http",
"port": "3000",
"type": "gotenberg:8",
"instance_ips": [
"123.456.78.90"
],
"ip": "123.456.78.90",
"url": "http://gotenberg.internal:3000"
}
```
Here is an example of how to gather [`PLATFORM_RELATIONSHIPS` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables) information
in a [`.environment` file](https://docs.platform.sh/development/variables/set-variables.md#use-env-files):
```bash {location=".environment"}
# Decode the built-in credentials object variable.
export RELATIONSHIPS_JSON=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode)
# Set environment variables for individual credentials.
export APP_GOTENBERG_HOST=="$(echo $RELATIONSHIPS_JSON | jq -r '.gotenberg[0].host')"
```
##### Usage example
###### 1. Configure the service
To define the service, use the `gotenberg` type:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: gotenberg:
```
Note that changing the name of the service replaces it with a brand new service and all existing data is lost. Back up your data before changing the service.
###### 2. Define the relationship
To define the relationship, use the ``http`` endpoint:
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services and matches in both the application and services configuration.
With the above definition, Platform.sh uses the ``http`` endpoint,
providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) (the network address a service is accessible from) that is identical to the name of the service.
The application has access to the service via this relationship and its corresponding ``PLATFORM_RELATIONSHIPS`` [environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: http
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has access to the service via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
The `http` endpoint uses port `3000` by default.
###### Example configuration
####### [Service definition](https://docs.platform.sh/add-services.md)
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
gotenberg:
type: gotenberg:8
```
####### [App configuration](https://docs.platform.sh/create-apps.md)
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
relationships:
gotenberg:
```
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
gotenberg:
service: gotenberg
endpoint: http
```
##### Generate a PDF using Gotenberg
As an example, to generate a PDF file of the Platform.sh website, run the following cURL command:
```bash {location="Terminal"}
curl \
--request POST http://yduimhaby523ase4lju3qhimre.gotenberg8.service._.eu-3.platformsh.site/forms/chromium/convert/url \
--form url=https://platform.sh \
--form landscape=true \
--form marginTop=1 \
--form marginBottom=1 \
-o my.pdf
```
### Headless Chrome
Headless Chrome is a headless browser that can be configured on projects like any other service on Platform.sh.
You can interact with the `chrome-headless` service container using Puppeteer, a Node.js library that provides an API to control Chrome over the DevTools Protocol.
Puppeteer can be used to generate PDFs and screenshots of web pages, automate form submission, and test your project's UI. You can find out more information about using Puppeteer on [GitHub](https://github.com/GoogleChrome/puppeteer) or in their [documentation](https://pptr.dev/).
##### Supported versions
You can select the major version. But the latest compatible minor version is applied automatically and can’t be overridden.
Patch versions are applied periodically for bug fixes and the like.
When you deploy your app, you always get the latest available patches.
| Grid | Dedicated Gen 2 |
|
- 120
- 113
- 95
- 91
- 86
- 84
- 83
- 81
- 80
- 73
None available
##### Relationship reference
Example information available through the [`PLATFORM_RELATIONSHIPS` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables)
or by running `platform relationships`.
Note that the information about the relationship can change when an app is redeployed or restarted or the relationship is changed.
So your apps should only rely on the `PLATFORM_RELATIONSHIPS` environment variable directly rather than hard coding any values.
```json
{
"service": "chrome-headless",
"ip": "123.456.78.90",
"hostname": "azertyuiopqsdfghjklm.chrome-headless.service._.eu-1.platformsh.site",
"cluster": "azertyuiop-main-7rqtwti",
"host": "chrome-headless.internal",
"rel": "http",
"scheme": "http",
"type": "chrome-headless:120",
"port": 9222
}
```
##### Requirements
Puppeteer requires at least Node.js version 6.4.0, while using the async and await examples below requires Node 7.6.0 or greater.
If your app container uses a language other than Node.js, upgrade the Node.js version before using Puppeteer.
See how to [manage your Node.js version](https://docs.platform.sh/languages/nodejs/node-version.md).
##### Usage example
###### 1. Configure the service
To define the service, use the `chrome-headless` type:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: chrome-headless:
```
Note that changing the name of the service replaces it with a brand new service and all existing data is lost.
Back up your data before changing the service.
###### 2. Define the relationship
To define the relationship, use the following configuration:
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services
and matches in both the application and services configuration.
The example above leverages [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
That is, it uses default endpoints behind-the-scenes, providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships)
(the network address a service is accessible from) that is identical to the name of that service.
Depending on your needs, instead of default endpoint configuration,
you can use [explicit endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#use-in-app) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: http
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#use-in-app) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
###### Example configuration
###### [Service definition](https://docs.platform.sh/add-services.md)
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
chrome-headless:
type: chrome-headless:120
```
####### [App configuration](https://docs.platform.sh/create-apps.md)
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
chrome-headless:
```
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
chrome-headless:
service: chrome-headless
endpoint: http
```
###### Use in app
After configuration, include [Puppeteer](https://www.npmjs.com/package/puppeteer) as a dependency:
```bash {}
pnpm add puppeteer
```
```bash {}
yarn add puppeteer
```
Using the [Node.js Config Reader library](https://docs.platform.sh/development/variables/use-variables.md#access-variables-in-your-app), you can retrieve formatted credentials for connecting to headless Chrome with Puppeteer:
```js
const platformsh = require('platformsh-config');
const config = platformsh.config();
const credentials = config.credentials('chromeheadless');
```
and use them to define the `browserURL` parameter of `puppeteer.connect()` within an `async` function:
```js
exports.getBrowser = async function (url) {
try {
// Connect to chrome-headless using pre-formatted puppeteer credentials
const formattedURL = config.formattedCredentials('chromeheadless', 'puppeteer');
const browser = await puppeteer.connect({browserURL: formattedURL});
...
return browser
} catch (error) {
console.error({ error }, 'Something happened!');
browser.close();
}
};
```
Puppeteer allows your application to [create screenshots](https://pptr.dev/#?product=Puppeteer&version=v13.0.1&show=api-pagescreenshotoptions), [emulate a mobile device](https://pptr.dev/#?product=Puppeteer&version=v13.0.1&show=api-pageemulateoptions), [generate PDFs](https://pptr.dev/#?product=Puppeteer&version=v13.0.1&show=api-pagepdfoptions), and much more.
You can find some useful examples of using headless Chrome and Puppeteer on Platform.sh on the Community Portal:
* [How to take screenshots using Puppeteer and Headless Chrome](https://support.platform.sh/hc/en-us/community/posts/16439566011538)
* [How to generate PDFs using Puppeteer and Headless Chrome](https://support.platform.sh/hc/en-us/community/posts/16439696206482)
### InfluxDB (Database service)
InfluxDB is a time series database optimized for high-write-volume use cases such as logs, sensor data, and real-time analytics.
It exposes an HTTP API for client interaction. See the [InfluxDB documentation](https://docs.influxdata.com/influxdb) for more information.
##### Supported versions
You can select the major and minor version.
Patch versions are applied periodically for bug fixes and the like.
When you deploy your app, you always get the latest available patches.
| Grid | Dedicated Gen 2 |
|
- 2.7
- 2.3
None available
##### Deprecated versions
The following versions are still available in your projects,
but they're at their end of life and are no longer receiving security updates from upstream.
| Grid | Dedicated Gen 2 |
|
- 2.2
- 1.8
- 1.7
- 1.3
- 1.2
None available
To ensure your project remains stable in the future,
switch to a [supported version](#supported-versions).
See more information on [how to upgrade to version 2.3 or later](#upgrade-to-version-23-or-later).
##### Relationship reference
Example information available through the [`PLATFORM_RELATIONSHIPS` environment variable](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables)
or by running `platform relationships`.
Note that the information about the relationship can change when an app is redeployed or restarted or the relationship is changed.
So your apps should only rely on the `PLATFORM_RELATIONSHIPS` environment variable directly rather than hard coding any values.
```json
{
"host": "influxdb.internal",
"hostname": "azertyuiopqsdfghjklm.influxdb.service._.eu-1.platformsh.site",
"cluster": "azertyuiopqsdf-main-bvxea6i",
"service": "influxdb",
"type": "influxdb:2.7",
"rel": "influxdb",
"scheme": "http",
"username": "admin",
"password": "ChangeMe",
"port": 8086,
"path": null,
"query": {
"org": "main",
"bucket": "main",
"api_token": "azertyuiopqsdfghjklm1234567890"
},
"fragment": null,
"public": false,
"host_mapped": false,
"instance_ips": [
"123.456.78.90"
],
"ip": "123.456.78.90"
}
```
##### Usage example
###### 1. Configure the service
To define the service, use the `influxdb` type:
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
:
type: influxdb:
disk: 256
```
Note that changing the name of the service replaces it with a brand new service and all existing data is lost.
Back up your data before changing the service.
###### 2. Define the relationship
To define the relationship, use the following configuration:
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
:
```
You can define ```` as you like, so long as it’s unique between all defined services
and matches in both the application and services configuration.
The example above leverages [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
That is, it uses default endpoints behind-the-scenes, providing a [relationship](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships)
(the network address a service is accessible from) that is identical to the name of that service.
Depending on your needs, instead of default endpoint configuration,
you can use [explicit endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#use-in-app) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
:
service:
endpoint: influxdb
```
You can define ```` and ```` as you like, so long as it’s unique between all defined services and relationships
and matches in both the application and services configuration.
The example above leverages [explicit endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships.
Depending on your needs, instead of explicit endpoint configuration,
you can use [default endpoint configuration](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships).
With the above definition, the application container now has [access to the service](#use-in-app) via the relationship ```` and its corresponding [PLATFORM_RELATIONSHIPS](https://docs.platform.sh/development/variables/use-variables.md#use-provided-variables).
###### Example configuration
###### [Service definition](https://docs.platform.sh/add-services.md)
```yaml {location=".platform/services.yaml"}
# The name of the service container. Must be unique within a project.
influxdb:
type: influxdb:2.7
disk: 256
```
####### [App configuration](https://docs.platform.sh/create-apps.md)
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows simplified configuration leveraging a default service
# (identified from the relationship name) and a default endpoint.
# See the Application reference for all options for defining relationships and endpoints.
relationships:
influxdb:
```
.platform.app.yaml
```yaml {}
name: myapp
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
influxdb:
service:
endpoint: influxdb
```
###### Use in app
To use the configured service in your app, add a configuration file similar to the following to your project.
```yaml {}
# The name of the app container. Must be unique within a project.
name: myapp
[...]
# Relationships enable an app container's access to a service.
relationships:
influxdb:
```
.platform.app.yaml
```yaml {}
# The name of the app container. Must be unique within a project.
name: myapp
[...]
# Relationships enable access from this app to a given service.
# The example below shows configuration with an explicitly set service name and endpoint.
# See the Application reference for all options for defining relationships and endpoints.
# Note that legacy definition of the relationship is still supported.
# More information: https://docs.platform.sh/create-apps/app-reference/single-runtime-image.html#relationships
relationships:
influxdb:
service: influxdb
endpoint: influxdb
```
```yaml {location=".platform/services.yaml"}
influxdb:
type: influxdb:2.7
```
This configuration defines a single application (`myapp`), whose source code exists in the `/myapp` directory.
`myapp` has access to the `influxdb` service, via a relationship whose name is [identical to the service name](#2-define-the-relationship)
(as per [default endpoint](https://docs.platform.sh/create-apps/app-reference/single-runtime-image.md#relationships) configuration for relationships).
From this, `myapp` can retrieve access credentials to the service through the environment variable `PLATFORM_RELATIONSHIPS`. That variable is a base64-encoded JSON object, but can be decoded at runtime (using the built-in tool `jq`) to provide more accessible environment variables to use within the application itself:
```bash {location="myapp/.environment"}
# Decode the built-in credentials object variable.
export RELATIONSHIPS_JSON=$(echo $PLATFORM_RELATIONSHIPS | base64 --decode)
# Set environment variables for common InfluxDB credentials.
export INFLUX_USER=$(echo $RELATIONSHIPS_JSON | jq -r ".influxdb[0].username")
export INFLUX_HOST=$(echo $RELATIONSHIPS_JSON | jq -r ".influxdb[0].host")
export INFLUX_ORG=$(echo $RELATIONSHIPS_JSON | jq -r ".influxdb[0].query.org")
export INFLUX_TOKEN=$(echo $RELATIONSHIPS_JSON | jq -r ".influxdb[0].query.api_token")
export INFLUX_BUCKET=$(echo $RELATIONSHIPS_JSON | jq -r ".influxdb[0].query.bucket")
```
The above file — `.environment` in the `myapp` directory — is automatically sourced by Platform.sh into the runtime environment, so that the variable `INFLUX_HOST` can be used within the application to connect to the service.
Note that `INFLUX_HOST` and all Platform.sh-provided environment variables like `PLATFORM_RELATIONSHIPS`, are environment-dependent. Unlike the build produced for a given commit, they can't be reused across environments and only allow your app to connect to a single service instance on a single environment.
A file very similar to this is generated automatically for your when using the `platform ify` command to [migrate a codebase to Platform.sh](https://docs.platform.sh/get-started.md).
##### Export data
To export your data from InfluxDB, follow these steps:
1. Install and set up the [`influx` CLI](https://docs.influxdata.com/influxdb/cloud/tools/influx-cli/).
2. Connect to your InfluxDB service with the [Platform.sh CLI](https://docs.platform.sh/administration/cli/_index.md):
```bash
platform tunnel:single
```
This opens an SSH tunnel to your InfluxDB service on your current environment and produces output like the following:
```bash
SSH tunnel opened to at: http://127.0.0.1:30000
```
3. Get the username, password and token from the [relationship](#relationship-reference) by running the following command:
```bash
platform relationships -P
```
4. Adapt and run [InfluxDB's CLI export command](https://docs.influxdata.com/influxdb/v2.3/reference/cli/influx/backup/).
``` bash
influx backup --host --token